TextToSpeech(GCP)
概要
端的にいうとGoogle の AI テクノロジーを搭載した API を利用して、テキストを自然な音声、つまり人が話しているように聞こえる音声を生成する
サービスの特徴
- 標準音声とWaveNet音声をサポート。独自音声の作成も可能(β版&日本語非対応)
- SSMLのサポート
機能
- 音声は標準・WaveNet・カスタムの3種類
音声合成に利用可能な音声一覧
標準音声
一般的な音声テクノロジーの 1 つであるパラメータ テキスト読み上げでは通常、ボコーダと呼ばれる信号処理アルゴリズムを介して出力を渡すことによって音声データを生成している。
Text-to-Speech の標準音声も、このテクノロジーのバリエーションを使用している
WaveNet 音声
Text-to-Speech による音声の作成方法は、合成音声技術が音声の機械モデルを作成する方法によって異なる
WaveNetはGoogle アシスタント、Google 検索、Google 翻訳の音声生成に使用されているモデル
WaveNet 音声を使うと他のテキスト読み上げシステムよりも自然な音声(より人間らしく、音節、音素、単語の強調や抑揚がある音声)が合成される。他の合成音声よりも暖かみがあり、人間のそれに似ていると感じられます。
標準音声と料金が異なる(料金詳細)
Custom Voice(ベータ版)
独自の音声録音を使用してカスタム音声モデルをトレーニングし、オリジナルのより自然な音声の作成が可能
新しいフレーズを録音する手間をかけず、自社に合った音声プロファイルを定義、選択して、必要な音声の変更に合わせてすばやく調整できます。
*現状アメリカ英語(en-US)、オーストラリア英語(en-AU)、アメリカ スペイン語(es-US)のみで日本語非対応
機能(音声調整)
その他にもチューニングやSSMLでの調整も可能
音声のチューニング
音声の高さ(ピッチ): デフォルトから上下 20 セミトーン(半音 20 個分)の幅で調整可能
発話の速度: 通常の 4 倍まで速くまたは遅くカスタマイズ可能
テキストと SSML(音声合成マークアップ言語) のサポート
SSML タグを使用すると、発話休止、数字、日時形式、その他の発音上の指示を追加して発話をカスタマイズできます。
実装
API
RESTとRPCの2種類のAPIがある(以降は一旦RESTで書く)
APIBaseURL: https://texttospeech.googleapis.com
POST /v1/text:synthesize
テキストを合成音声に変換するときに利用

input(required)
合成対象となる文字列
- text(制限5000文字文字)
- raw text
- SSML(制限5000文字)
- SSML形式
- 有効なものでなかったり、フォーマットが違っていた場合google.rpc.Code.INVALID_ARGUMENTが返される
*両方をセットあるいはどちらもセットしなかった場合google.rpc.Code.INVALID_ARGUMENTが返される
voice(required)
合成する際にどの音声(voice)を使用するか
- languageCode(required)
→ ex) ja-JP,en-US - name
- ja-JP-Wavenet-A ,ja-JP-Standard-Aのような値を設定
- 設定しない場合はlanguageCodeやgenderのような他のパラメーターに基づいて自動で選択される
- ssmlGender
- 選択しても該当のgenderのものがなければ、失敗するのではなく違うgenderのものが代用として使われる
audioConfig(required)
速度、ピッチ、句点読点の長さ、音量、抑揚を設定できる
-
audioEncoding(required)
- エンコード方式
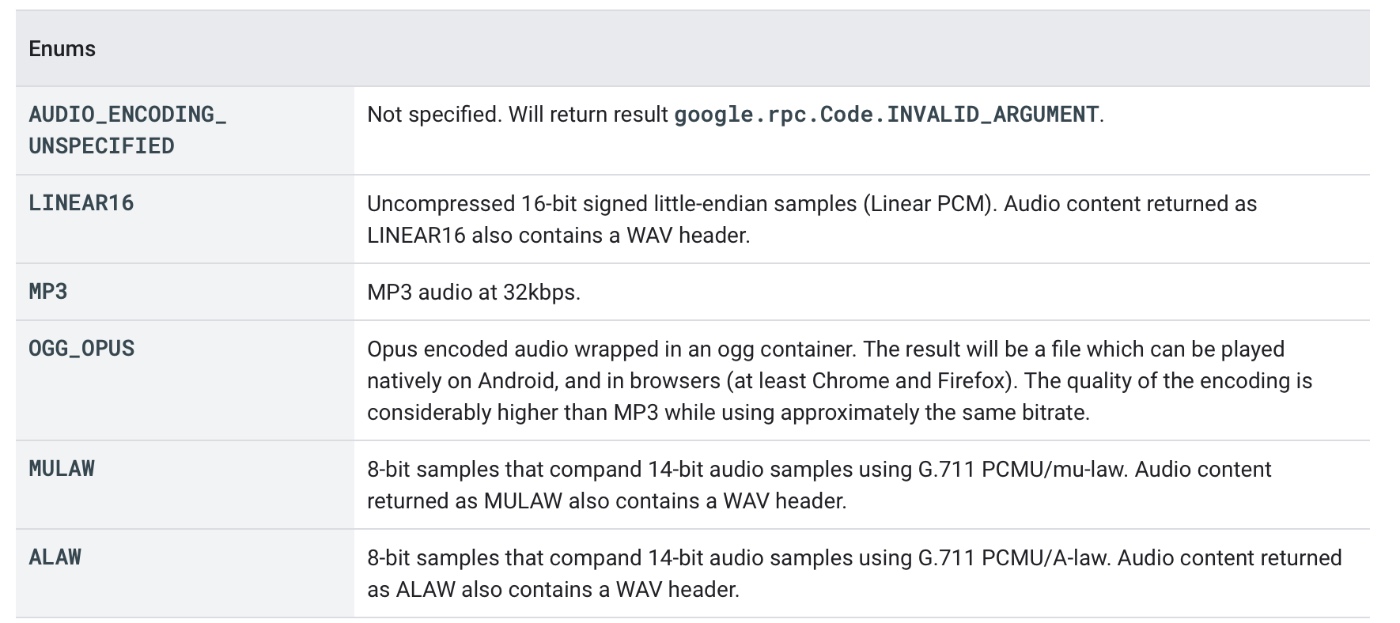
- エンコード方式
-
speakingRate
- 話す速さ
- 範囲は0.25~4.0
- 1.0が標準
- 設定されてないor0.0の場合は標準の1.0となる
- 範囲を超えた値が設定されるとエラーが返される
-
pitch
- 声のトーン
- 範囲は-20~20
-
volumeGainDb
- 設定しないor0.0が設定される標準の値に自動的になる
- 範囲は-96.0~16.0
- -6.0が設定されると通常の半分。6.0が設定される通常の倍になる
- +10.0以上の値は設定しても効果的な結果を望めないため非推奨
-
sampleRateHertz
- 音声ファイルのサンプル周波数?
- 指定した値が音声の自然な値と異なる場合、指定された値が設定される。その結果音質が悪くなることもある
- 指定されたサンプルレートが選択されたエンコーディングでサポートされてない場合はリクエストに失敗しgoogle.rpc.Code.INVALID_ARGUMENTが返される
-
effectsProfileId
- デバイスごとに音声合成を最適化できる?(詳細)
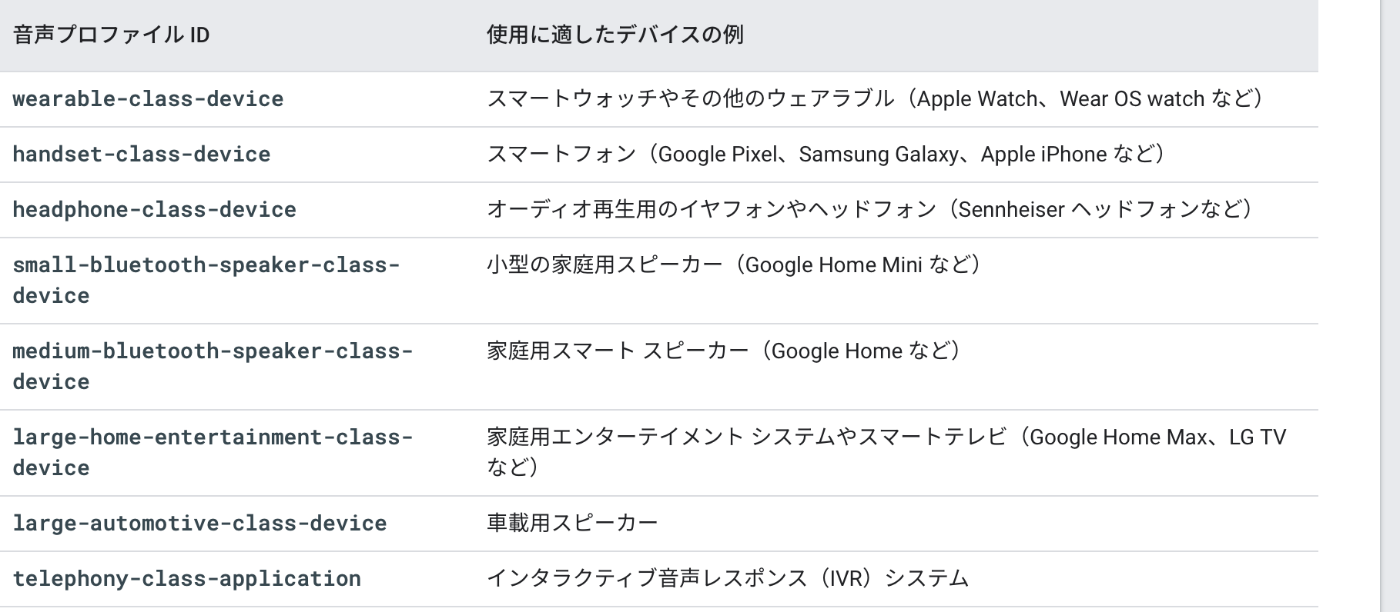
- デバイスごとに音声合成を最適化できる?(詳細)
GET /v1/voices
パラメータに言語コードを渡すことで、指定言語で音声合成に利用可能な音声一覧が取得できる
(省略)
概要
Google の AI テクノロジーを搭載した API を利用して、テキストを自然な音声に変換できます。
ドキュメント・参考
- ドキュメントTOP
https://cloud.google.com/text-to-speech/#section-5 - API Reference
https://cloud.google.com/text-to-speech/docs/reference/rest/v1/text/synthesize#VoiceSelectionParams - チュートリアル
https://medium.com/google-cloud/how-to-integrate-google-cloud-text-to-speech-api-into-your-ios-app-140ab7be42ae - 利用可能音声一覧
https://cloud.google.com/text-to-speech/docs/voices - 料金
https://cloud.google.com/text-to-speech/#section-11
カスタマイズ
-
ボイスの種類
標準・WavNet・独自の3種類で間違っていなければ以下 *ただし独自は日本語非対応
"ja-JP-Wavenet-A"
"ja-JP-Wavenet-B"
"ja-JP-Wavenet-C"
"ja-JP-Wavenet-D"
"ja-JP-Standard-A"
"ja-JP-Standard-B"
"ja-JP-Standard-C"
"ja-JP-Standard-D" -
読み上げスピード
0.25~4.0
1.0が標準
設定されてないor0.0の場合は標準の1.0となる
範囲を超えた値が設定されるとエラーが返される -
読み上げピッチ(声の高さ)
範囲は-20~20 -
読み上げ音量
設定しないor0.0が設定される標準の値に自動的になる
範囲は-96.0~16.0
-6.0が設定されると通常の半分。6.0が設定される通常の倍になる
+10.0以上の値は設定しても効果的な結果を望めないため非推奨 -
sampleRateHertz(音声ファイルのサンプル周波数?)
指定した値が音声の自然な値と異なる場合、指定された値が設定される。その結果音質が悪くなることもある
指定されたサンプルレートが選択されたエンコーディングでサポートされてない場合はリクエストに失敗しgoogle.rpc.Code.INVALID_ARGUMENTが返される
- effectsProfileId(最適化対象デバイス?)
デバイスごとに音声合成を最適化できる?(詳細)
備考
所感として句読点を打つなり、raw textではなくSSML(音声合成マークアップ言語)形式の文字列を渡さないとなかなか期待する読み方はしてくれないかも
SSMLを使うと文字に対して違う読み方をさせたり、他にも工夫ができるみたい
API叩いてリクエストボディの内容でサーバー側で合成を行った後
クライアントに合成済みファイルを返す
クライアント側はこれを再生するだけっぽい
だから音量やスピードみたいな調節はリアルタイムでしたいしAVAudioPlayerで調節するようにしたほうが良さそう
Cloud Text-to-Speechでも速さ、ボリューム、ピッチ(高さ)を調整できるけど、APIリクエストを受けてサーバー側で音声合成を行うときに設定するから現状流れているものに対しての調整を行えない
音声周りの基本がわからない
そもそも音声データを記録するための音楽ファイル形式には「非圧縮」「非可逆圧縮」「可逆圧縮」の3つの種類があるみたい
非圧縮
- その名の通り圧縮されていないファイル
- 高品質だけど、容量が大きい
- WAVやAIFFとか
圧縮
人間の耳に聴こえる周波数帯は決まっており、それ以外の周波数は聴こえない
その余分な周波数を削り、全体的に容量を小さくすること
参照: http://ww1.tiki.ne.jp/~y-mitsu/monganoyakata/av_electronics/mp3.htm
非可逆圧縮
例えばMP3方式で圧縮するとCDと同等の音質で容量を約11分の1に大きさに出来ます。
削った部分を捨ててしまって容量を少なくするのですから、一度圧縮した音源は元には戻せません。こういう圧縮方式を不可逆圧縮と言います。逆に戻すのが不可ということです。
参照: http://ww1.tiki.ne.jp/~y-mitsu/monganoyakata/av_electronics/mp3.htm
人間の可聴域は20Hz~20000Hzだと言われています。このファイル形式はそれ以外の判別しにくい部分を排除し圧縮することで、ある程度の音質を保ちながらもファイルサイズを抑えられるというメリットがあります。
参照: https://data.wingarc.com/music-file-format-11263
可逆圧縮
戻せる圧縮は可逆圧縮といいます
参照: http://ww1.tiki.ne.jp/~y-mitsu/monganoyakata/av_electronics/mp3.htm
この形式はオリジナルのデータを保ったまま圧縮します。
再生時は解凍され元の非圧縮形式に戻ることができるので、音質面ではオリジナルのデータと変わらないということになります。非圧縮形式よりもファイルサイズは軽減できますが、それでも約半分程度なので、非可逆圧縮形式に比べるとファイルサイズは大きめで、エンコード・デコードの時間も要します。
また、現在主流の音楽配信サイトで扱われていないことが多く、再生出来る機器も非圧縮形式に比べると少ないです。この形式で最も一般的なのは「FLAC」、Appleでは「ALAC」という独自のフォーマットを採用しています。
参照: https://data.wingarc.com/music-file-format-11263
WAVとMP3のちがい
どちらも音声データを記録するためのファイル形式だけど違いってなんなんだろう
WAV
- 非可逆圧縮
- ロスレスで高品質。圧縮されていない録音した状態と同じ音質を保った形式
- ファイルが重い
MP3
MP3はWAVでは重すぎる音源ファイルを軽くするためにWAVファイルの中の、人間には聴こえないとされる音のみを取り除きファイルを大幅に軽くしたものです。
ちなみに参考として、同じWAVファイルとMP3ファイルの大きさは
WAVが41MBあるのに対して、MP3ファイルがその1/4以下の9.2MBです。
参照: https://vook.vc/n/1076
WAVは非可逆圧縮の音声フォーマットと勘違いされることがあるけど必ずしもそうではないらしい
標準では無圧縮のPCM方式のデータが記録されていることが多いため無圧縮の音声フォーマットであると説明されることもあるがこれは誤解であり、実際、WMA形式やMP3形式などで圧縮された音声データをWAVファイルに記録することもできる。
linear16 は通常、高品質オーディオデータに使用されます。
参照: https://docs.oracle.com/cd/E26924_01/html/E29112/audioconvert-1.html