【翻訳】Swift Concurrency Deep Dive [3] — Structured concurrency
この投稿は、 Swift の並行処理、つまり async/await をより深く理解するために書かれています。
Apple Developer's Document、Swift-evolutionリポジトリ、 Swift Language Guide のような信頼できる情報源から可能な限り情報を集めましたが、間違った情報が含まれているかもしれません。その場合は、コメントで教えてください。
私の以前のシリーズを読むことを強くお勧めします。
Swift Concurrency Deep Dive [1] — GCD vs async/await (https://towardsdev.com/swift-concurrency-deep-dive-1-gcd-vs-async-await-280ac5df7c76)
Swift Concurrency Deep Dive [2] — Continuation (https://enebin.medium.com/swift-concurrency-deep-dive-2-continuation-c2e385b11a10)
構造化プログラミングのパラダイム
構造化と非構造化の概念
from Wikipedia
構造化プログラミングとは、 選択(if/then/else) や 繰り返し(whileやfor)、ブロック構造、サブルーチンといった構造化された制御フロー構造を多用することで、コンピュータ・プログラムの明瞭性、品質、開発期間を向上させることを目的としたプログラミング・パラダイムです。
ごく簡単に言えば、構造化プログラミングとは、コードが書かれた順番に実行されるということであり、いわば手続き的なものです。
構造化プログラミングを実装した Swift のコード例です。
var preparedDishes = 0
for i in 1...100 {
cook()
preparedDishes += 1
}
if preparedDishes == 100 {
print("It's done")
}
末尾のコードは、先行するすべてのコードが完了したときにのみ実行されることがすぐに分かるでしょう。
これを完了ハンドラー・パターンで表現すると、次のようになります。
var preparedDishes = 0
DispatchQueue.global().async {
while true {
if self.preparedDishes == 100 {
print("It's done")
break
}
}
}
DispatchQueue.global().async {
for i in 1...100 {
cook(completion: {
self.preparedDishes += 1
})
}
}
この場合、最初の例とは異なり、末尾のコードの補完が先行するコードに影響を与えます。このコードは構造化されていないと言えます。
Swiftの古い並行コードは構造化されていない

Swift の並行処理が導入される前は、 Swift での並行処理プログラミングは、我々が見た例のように、ほとんどが構造化されていない方法で行われなければなりませんでした。
DispatchQueue の async と Combine の Publisher を使って、結果を得るためにコールバック関数を使わなければなりませんでした。残念なことに、これらを使うと、コードが非構造的にならざるを得ませんでした。
非構造化プログラミングは、末尾のコードが直前のコードに影響を与える可能性があり、自然な読み順を逆転させるため、可読性が損なわれ、エラーが発生しやすい構造になってしまいます。
これらの理由から、 Swift の非同期プログラミングにおける構造化されたコードの必要性が浮上し、結果として Swift の並行処理が提案されました。
Swiftにおける構造化並行処理
構造化プログラミングは、 Swift の並行処理の核となるコンセプトと言えます。 Swift-evolution リポジトリに書かれた提案文書や WWDC のセッション「Explore structured concurrency in Swift - WWDC21」から、メーカーの意図を垣間見ることができます。
では、 URLSession を通して、 Swift の構造化プログラミングと非構造化プログラミングの違いを見てみましょう。
var completionHandler: ((Result<UIImage, Error>) -> Void)?
let urlRequest = URLRequest(url: URL(string: "www.example.com")!)
URLSession.shared.dataTask(with: urlRequest) { data, response, error in
// ...
guard let completion = completionHandler else { return }
guard let data = data else {
completion(.failure(URLError.cannotDecodeContentData))
return
}
let image = UIImage(data: data)
completion(.success(image))
}
最初の例は、これまでよく使われてきた completionHandler を使う方法です。
これには次のような特徴があります。
・ クロージャである completionHandler を使って、 dataTask が完了したときにコールバックを受け取る関数です。
・ ここでは、 completionHandler を直接呼び出して、処理した画像を外部に受け渡す必要があります。
・ また、データを渡すだけでなく、 Result 型を使ってエラーを外部に投げられるようにしています。
let urlRequest = URLRequest(url: URL(string: "www.example.com")!)
Task {
let data = try await URLSession.shared.data(for: urlRequest)
let image = UIImage(data: data.0)
return image
}
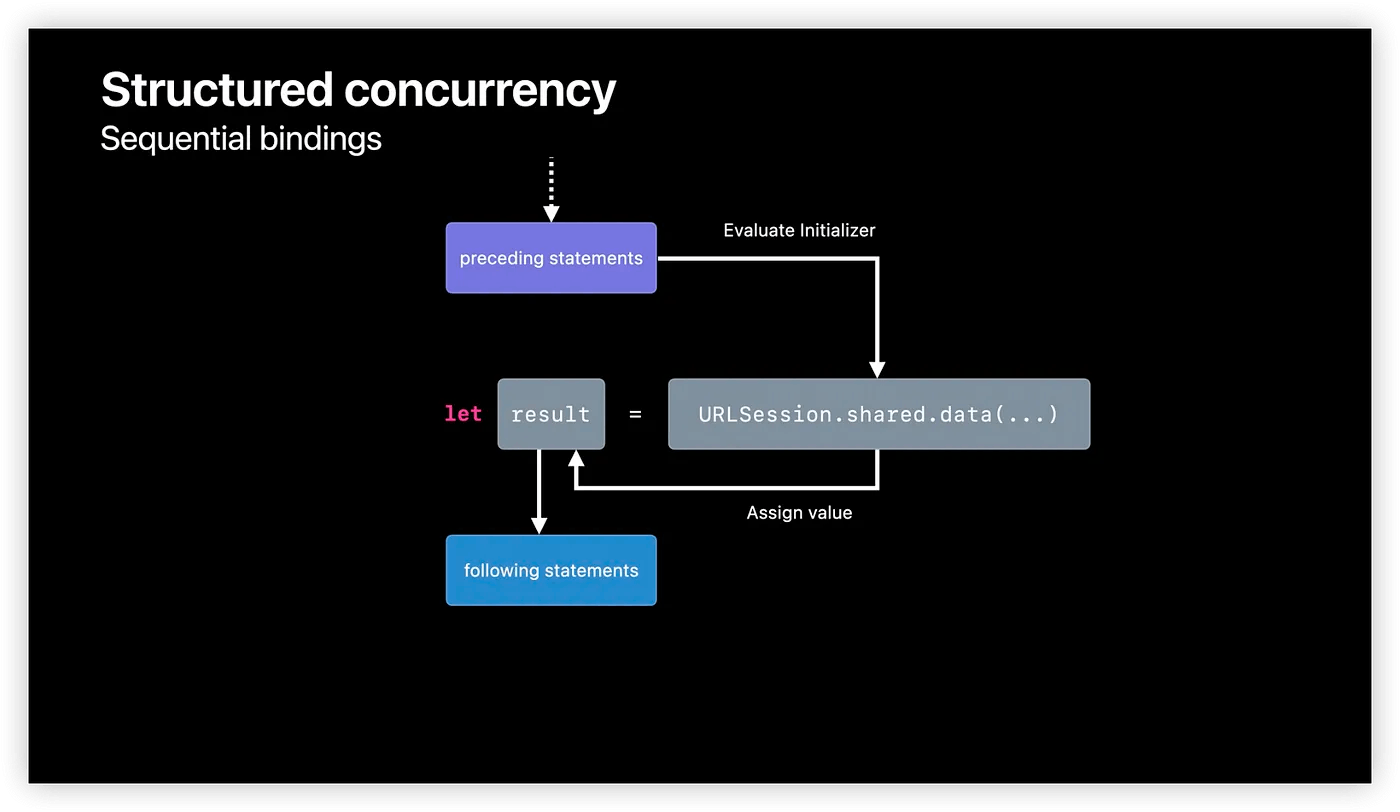
2つ目の例は、 completionHandler から変更した async/await を使ったコードです。
次のような特徴があります。
・ await を使うとデータのロードが中断されるので、すべてのコードは処理が完了するまでその時点で停止します。
・ 処理が完了すると、結果データが変数データに保存されます。
・ 中断した時点から再開し、そのデータを使って画像を作成します。その後、 Task は画像を返します。
このように、コードは書かれた順番に実行されます。
比較
completionHandler を使った最初の例では、 completionHandler を呼び忘れた場合に結果が渡せないという問題があります。completionHandler パターンを使ったコードによくある問題のひとつです。
しかし、 async/await を使った2番目の例では、 completionHandler を使わなくても result が渡されるので、潜在的なエラーはなくなります。
また、 Result 型を使う必要もなく、キーワード try を使ってすぐにエラーを投げることができます。 throw を使うこともできます。
これらの機能のおかげで、コードがより短く、読みやすくなり、さらにパフォーマンスも向上します。
Taskとは?
ところで、私たちは無意識のうちに Task というキーワードを使ってきました。
一言で言えば、 Task は Swift の並行処理における非同期ジョブの単位であり、そのイニシャライザは Swift の並行処理のコンテキストで非構造化並行処理を行うのに役立ちます。
さて、そろそろ Task について深く掘り下げてみましょう。
【翻訳元の記事】
Swift Concurrency Deep Dive [3] — Structured concurrency
Discussion