GGUFって結局どのサイズ選んだらいいの??
検証内容
- llama.cppのGGUFフォーマットについて量子化サイズ、手法での精度の変化を確認する
- 変換、量子化にはb3369のReleaseを使用
- 変換するモデルはtokyotech-llm/Llama-3-Swallow-8B-Instruct-v0.1
- 評価対象は次の84種類
- Model CardのUsageに沿ってvllmで実行したfloat32(そのままを
original、system promptに日本語で回答する指示を加えたものをoriginal_ja) - safetensors -> GGUFに変換した
F32とF16のGGUF -
Q8_0からQ2_Kまでのimatrixを必要としない14種類の量子化GGUF -
Q6_KからIQ1_Sまでのimatrixを使用できるor必要とする22種類の量子化GGUF
(4についてはimatrix作成のためのデータを3種類用意しそれぞれに22種類作成)
- Model CardのUsageに沿ってvllmで実行したfloat32(そのままを
- 評価指標はELYZA-tasks-100
- 評価者はGPT-4o(gpt-4o-2024-05-13)で、評価のためのプロンプトは下記リポジトリを参考にした
- それぞれのサイズにおいて100問×5setの回答を生成し、setごとに評価
- 5setの平均スコア、最大(最小)偏差、英語での回答回数、無限リピート回数を集計
コード、結果データ
検証のために使用したコードは下記で公開しています。
モデル、モデルの生成テキスト、GPT-4oの評価結果、全結果のcsvは下記に置いています。
量子化でどれくらいスコアは下がるの?
まずは、GGUFへの変換とそこからの量子化でどの程度スコアが低下するのか見ていきます。
結果はこちらです。
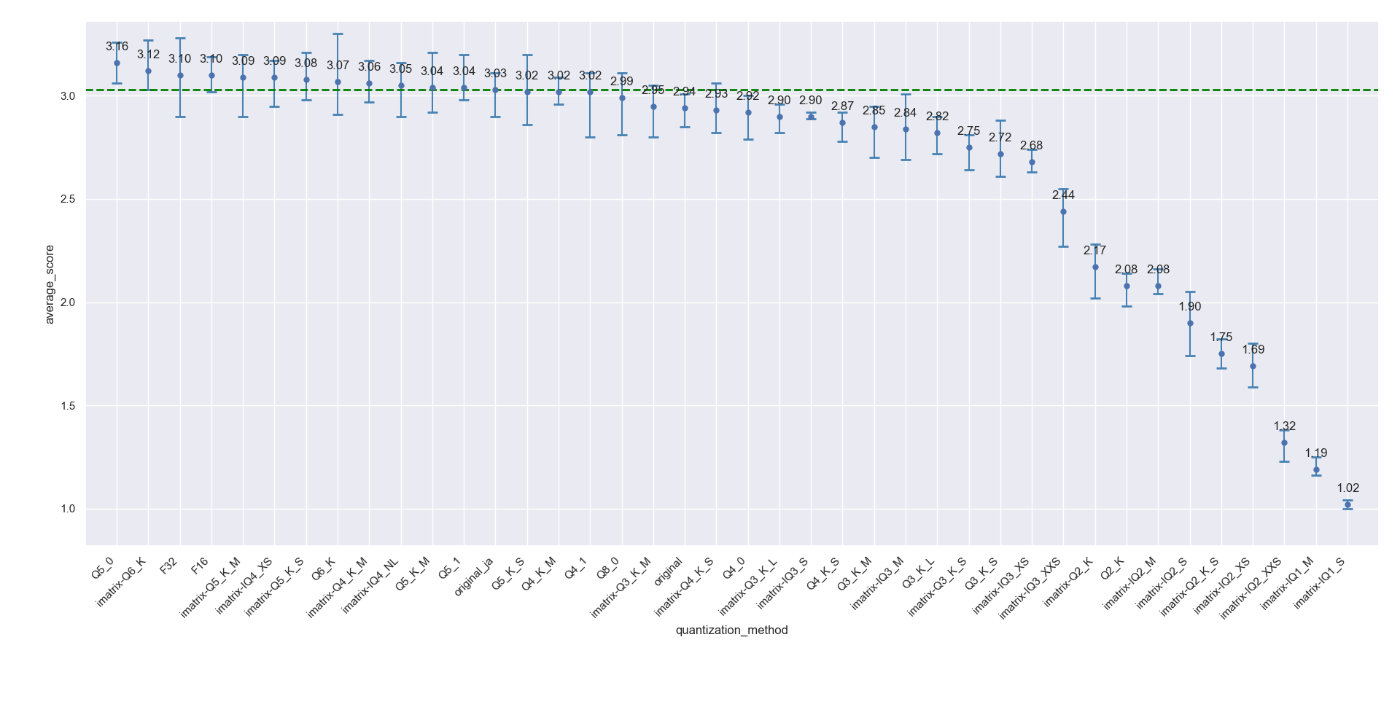
imatrix-とついているものはTFMC/imatrix-dataset-for-japanese-llmを使用し、imatrix量子化を行ったものです。
量子化することでoriginal_jaやF32よりも平均スコアが上がっているものもありますが、概ねQ8_0からQ4_K_Mまでは大きなスコア低下は無いように見えます。
気になったのは最近では積極的に見かけないQ5_0がベストスコアになっている点ですが、
回答例を見てみても、特段精度が上がったようには感じませんでした。
たまたま良い回答ができたのか、グラフではエラーバーのレンジが比較的小さいように思えるので、回答が安定した結果平均スコアが上がったということなのかもしれません。
ここでのまとめとして、汎用的な使用目的であれば8BサイズのモデルはQ4_K_M、もっと言えばIQ4_XSでも大きく性能低下はしないのかもしれません。
サイズと精度の落としどころは?
では、「極力小さいサイズを使いたいけど精度も捨てがたい。。」
そんな欲張りさんはどれを選ぶのがいいのでしょうか。
X軸を精度低下率、Y軸をファイルサイズの圧縮率として各サイズをプロットしてみました。
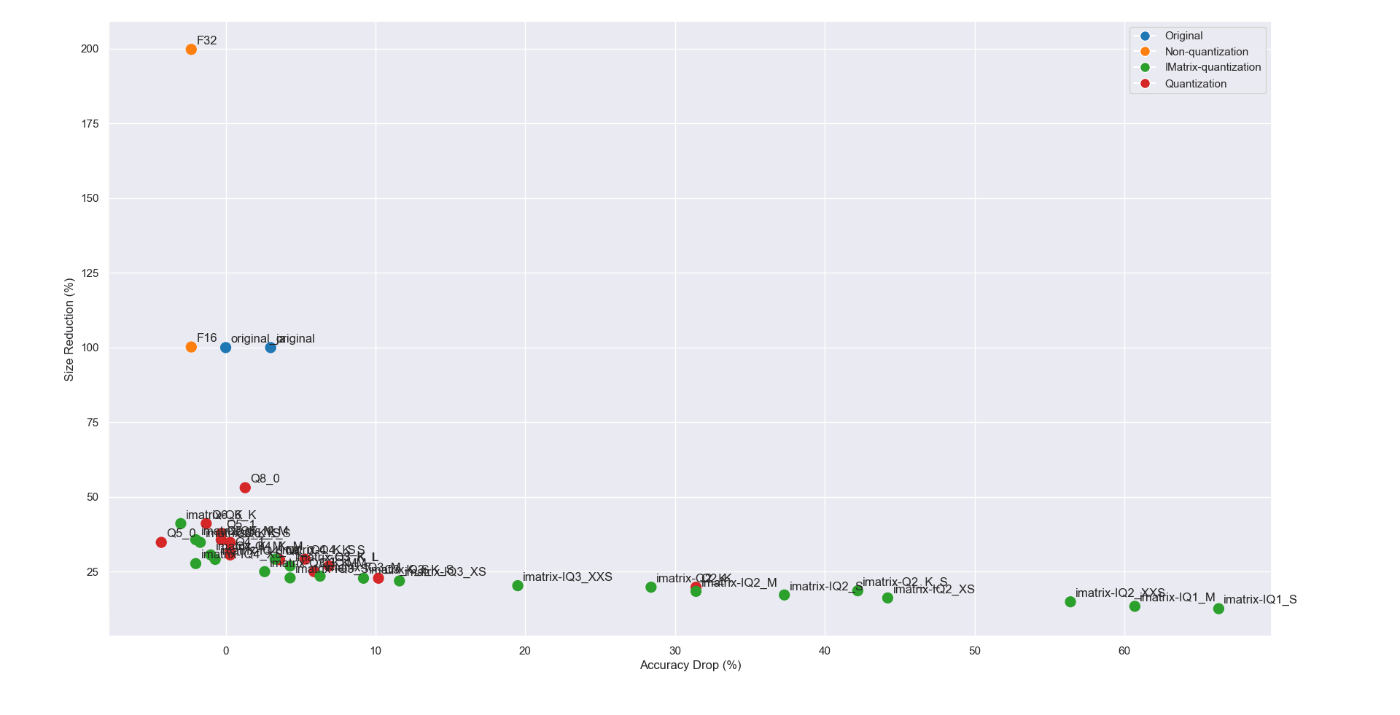
左下にあればあるほど精度を保ったまま小さくできているということになります。
ほとんどの量子化が左下に集まっていますので拡大してみます。
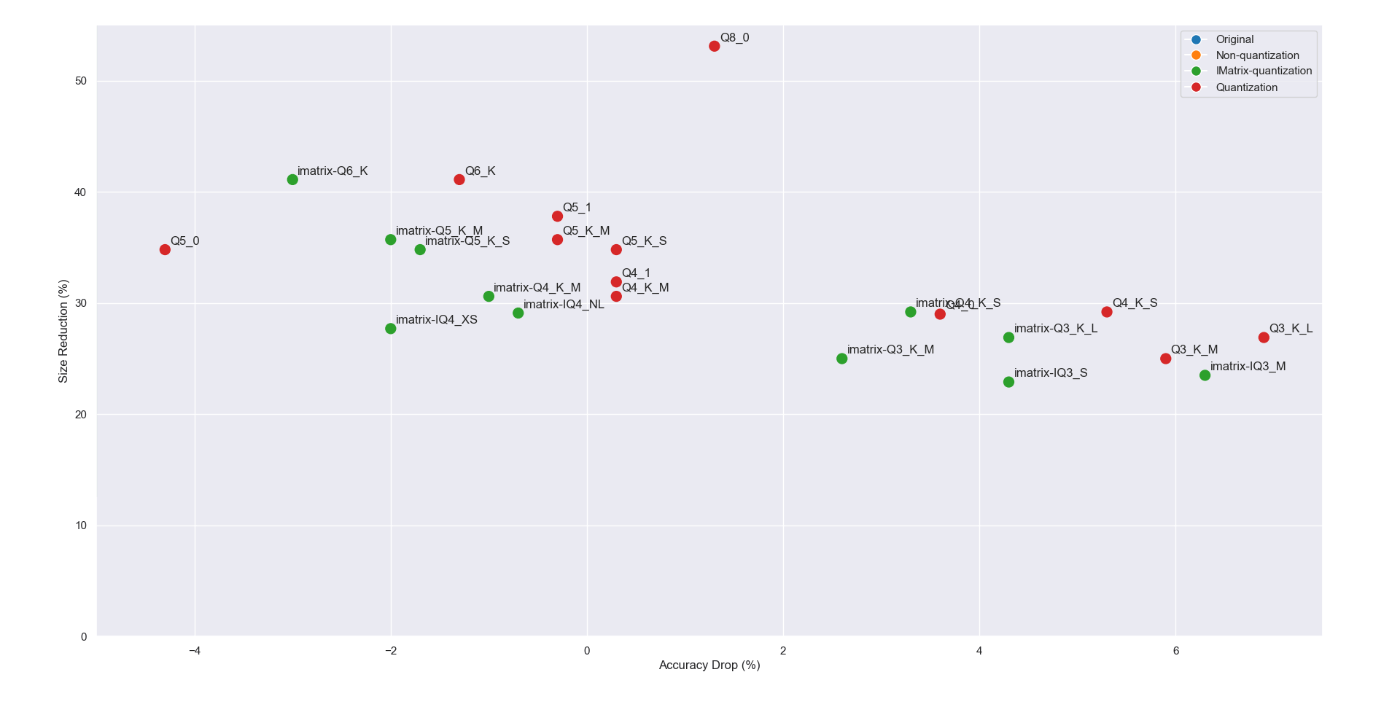
前項でもあったとおりQ5_0やIQ4_XSが左下に近いですね。
このグラフを見る限り、次のように考えられそうです。
- Q6~Q4が安定的にベスト
- 同じサイズでもimatrixを適用したほうがより精度が向上する(Q3以下は特に)
- ファイルサイズが大きければ精度がいいということでもない?
指示応答、無限リピート
今回量子化したLlama-3-Swallow-8B-Instruct-v0.1は英語モデルから日本語継続事前学習を行った関係からか、日本語の質問でも英語で返してしまう癖があります。
ただ、system promptに「日本語で回答してください」といった指示を追加すると
original(指示なし) -> 英語での平均回答数: 15/100 問
original_ja(指示あり) -> 英語での平均回答数: 8.6/100 問
という風に英語での回答がおおよそ半減したことから、ある程度プロンプトで回答を日本語限定にすることは可能そうです。
しかし、量子化することで言うことを聞かなくなってしまわないか気になり調べてみました。
また、ELYZA-tasks-100の中で回答を列挙させるような問題(13問目など)において無限リピートしてしまい出力が破綻するケースが少なからずありました。
これについても量子化することで悪化してしまうのかどうか見てみます。
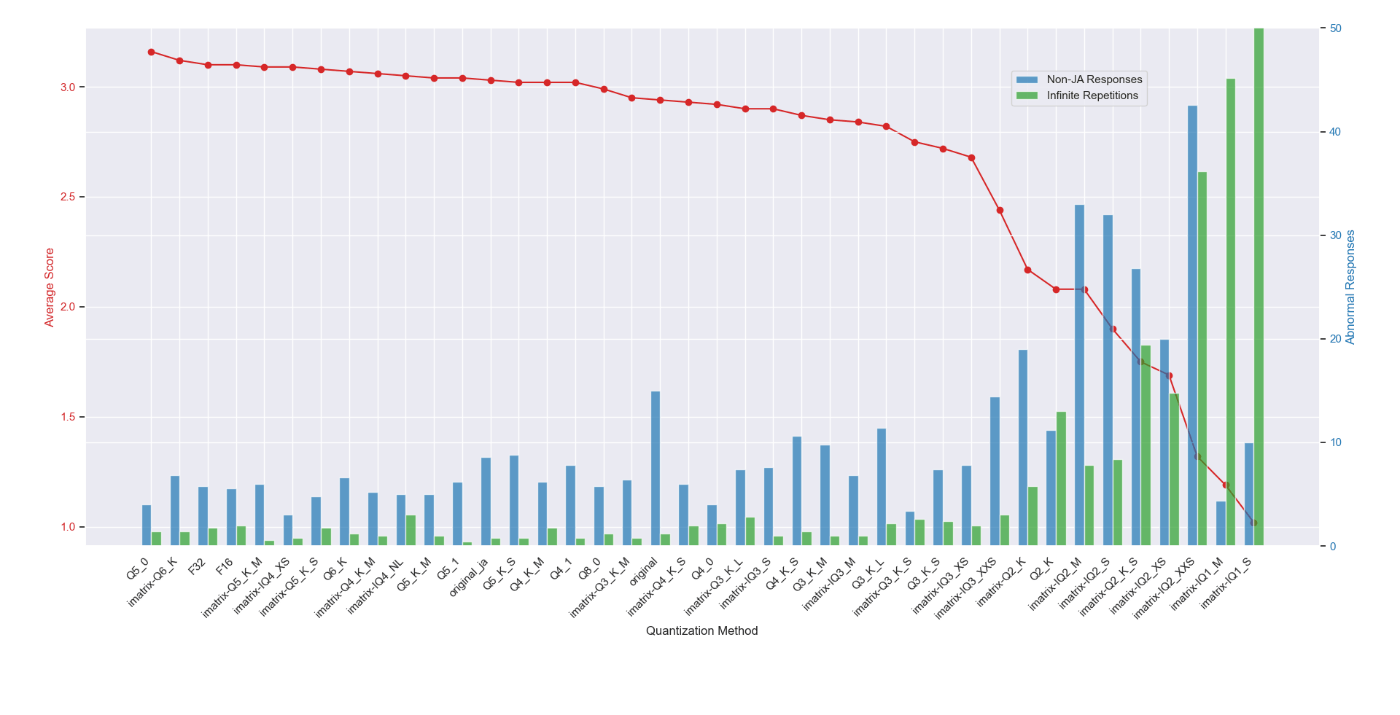
この例ではQ3まで量子化しても指示応答や無限リピートの回数にほぼ変化はありませんでした。
その代わり、Q2以下の量子化ではimatrixを適用したとしても指示を無視したり出力崩壊の回数が著しく増えています。
サイズと生成速度の関係
少し検証の目的からそれますが、量子化でサイズを圧縮した場合生成速度はどのように変化するのでしょうか?
こちらもサイズごとに5回tps(tokens per second)を取得して平均値をとってみました。
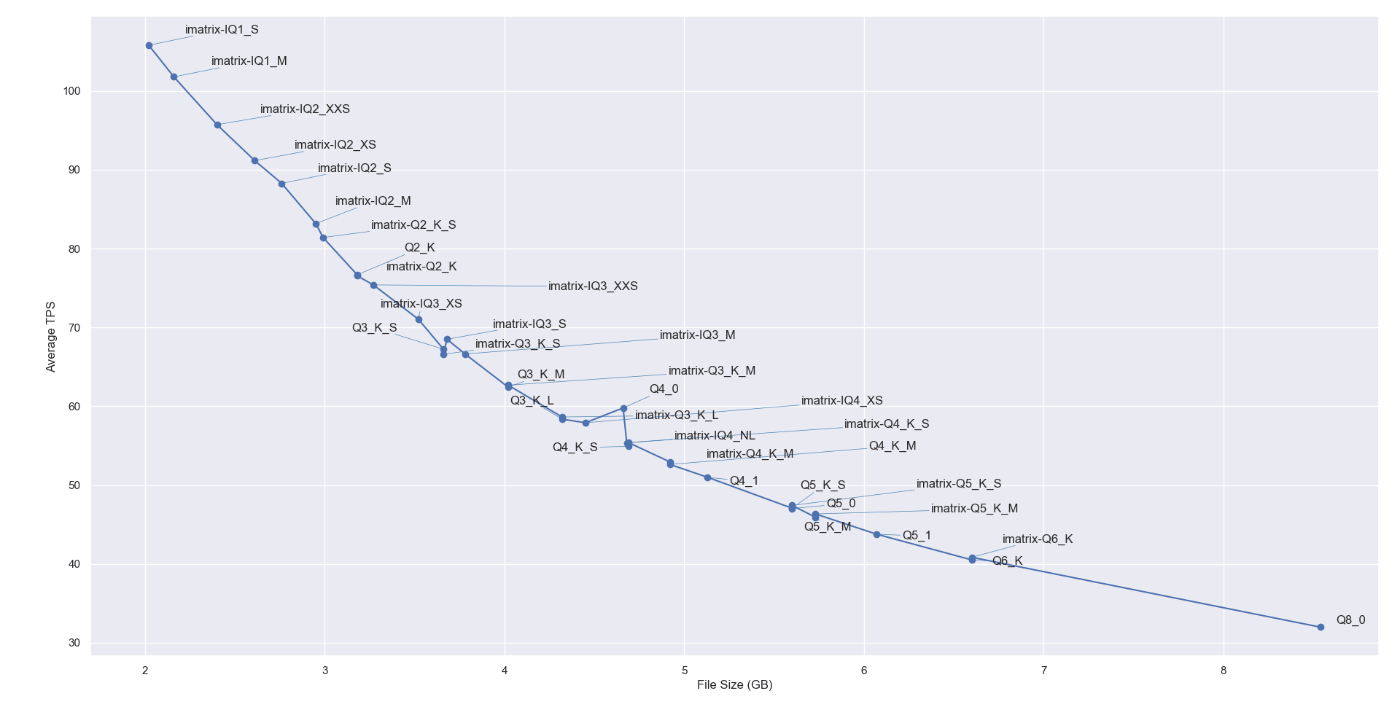
きれいにファイルサイズが小さくなればなるほど生成速度は速くなっています。
imatrixを適用したかどうかは生成速度に影響しないことも分かりますね。
また、記載していませんでしたが、この検証にはGeForce RTX 4060 Tiを使用しています。
チャットなどの目的であれば40tpsも出ればストレスは全くないのですが、今回のように複数回プロンプトをバッチ処理するケースなどはやはり少し遅さが目立つように感じました。
一旦まとめ
- VRAMに余裕がないなら
imatrixのQ4_K_M、もしくはIQ4_XSがいいかも! - 多少余裕があるなら
imatrixのQ6_Kがベスト!
imatrixのテキストデータ選び
さて、ここまでのimatrixはBaku氏の作った「C4から英語と日本語を抽出したテキストデータ」を使っていました。
※Baku氏がこのテキストデータの公開に至るまでに検証された内容は下記をご覧ください。
ただ、やはり気になるのはこれがベストなのだろうか?という点です。
mmnga氏をはじめとする各日本語モデルのGGUF変換をアップされている方はすべからくこのデータを使用しています。(多分)
そこで私はこの現状に一石を投じたいと思います!🤪
1. より使用用途に近いデータがいいのでは?
Baku氏の検証結果によるとデータは日本語だけでなく英語と日本語を混ぜた方がいいとのこと。
しかも順番があり、英語→日本語の順がもっとも性能がよかったということです。
この点についてはこれを踏襲したいと思います。
そして、私の理解ではこのデータはキャリブレーションデータのようなもので、実際の用途に近いデータがいいはずです。
じゃあ、instructionデータセットをキャリブレーションに使えばいいのでは?と考え、今回はdatabricks/databricks-dolly-15kを使うことにしました。
dolly-15kの日本語版としては
kunishou氏のdatabricks-dolly-15k-ja
と、
Kan Hatakeyama氏のdatabricks-dolly-15k-ja-regen-nemotron
があります。
今回はどちらを使用しようかなとデータを見てみるとどちらも以下の点で一長一短でした。
- dolly-15k-jaは元の情報が欠落しているデータがあるものの、文章はやわらかめ(フランク?)
- regen-nemotronは自然な文章が多いがLLM特有の補完が行われている、文章はかため
そのためどっちと決めるのではなく、両方を比較していいとこどりをしてみることにしました。
データの作成方法は次の通りです。
- dolly-15kの各カテゴリーのデータ割合のまま、英語200kB+日本語200kBの容量になるように各カテゴリーからデータをランダムに取り出す
- dolly-15k-jaとregen-nemotronの同じデータを比較し、より自然な日本語の方を選択
- Just Do It!!
しかしこのデータ選別思ったよりしんどかったです。
データによってはinstructionはdolly-15k-jaの方がいいけど、output(response)はregen-nemotronがいいなとかがあって結構複雑なMIXになりましたが割と自然な日本語データを集められたと思います。
txtファイルの形式はBakuさんのものに合わせて{instruction}{input}{output}\n\nにしました。
2. プロンプトフォーマットにしたら?
そしてもう一つ、LLMにとって用途に近い入力データといえば生のテキストデータではなくプロンプトフォーマットに整形された文字列だと思います。
なので先ほどのdolly-15k-jaとregen-nemotronの抽出MIXデータをllama3のプロンプトフォーマットに整形したものをimatrixデータにしたらどうなるのか気になって試してみました。
ただここで一つ問題がありまして、llama.cppのimatrix.cppを読むとどうやら次の処理になっているみたいです。
- 受け取ったテキストデータを全部読み込んでtokenize
- それをchunk(=512tokens)に分割
- chunkの最初のtokenをBOStokenにreplaceしてモデルに通す
- imatrixデータを収集
- 以下繰り返し
512tokensにぶった切られてしまうというのと、chunkの頭がBOStokenになって正しいプロンプトフォーマットにはならないという点です。
正確に検証しようとするならBOS含めて512tokensにしたデータを400kB分集めるのがいいのでしょうが、正直tokenizerの知識がない私には正確に全てのデータを512tokensにできる自信がありません。
なので、今回は単純に抽出データをllama3のプロンプトフォーマットで整形してそれをそのまま使ってみます。
3つのimatrix量子化を比較してみる
そして、全て同様にF32のGGUFを基にimatrixを作成し評価した結果がこちらです!
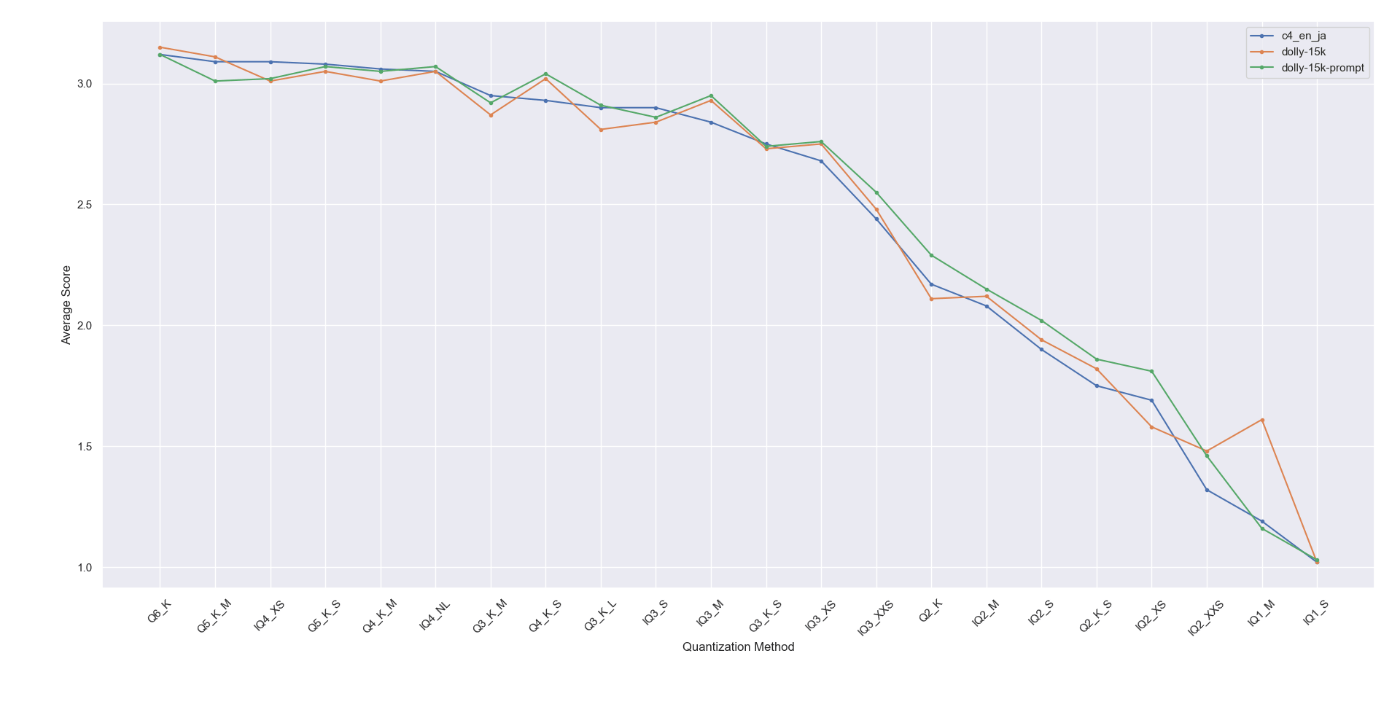
変わりませんでした。\(^o^)/
ある程度生成テキストや評価精度にばらつきがあることを考えると特別違いはないように思います。
あるとすればIQ3_XS以下はc4_en_jaに比べてdolly-15k-promptが上にいますから低いbitでは優位なのかな?というくらいですね。。
さあ!皆さんはこれからもTFMC/imatrix-dataset-for-japanese-llmを使っていきましょう!
では!
余談
今回の検証で発生した費用は、検証の検証含めて約30,000円!
今日は白米に焼き肉のたれをかけて食べました。😇
Discussion