AutoML Translationで実践『カスタム翻訳モデル』利用ガイド
はじめに
この記事はGoogle Developer Groups in Japan Advent Calendar 2023 23日目の記事です。
こんにちは。渋谷でソフトウェアエンジニア兼PjMをしている @_yukamiya です。
本記事では、Google Cloud Platform製品群のひとつ、AutoML Translationについて紹介します。
AutoML Translationとは
AutoML Translationは、特定のドメインや用途に特化した翻訳モデルを作成することが可能です。このカスタム翻訳モデルを使うことで、一般的な翻訳ツールが対応できない専門的な語彙や表現を正確に翻訳する必要がある場合に有用です。
AutoML Translationを利用しようと思った理由
業務で「子ども向けプログラミング教材」の翻訳を行う機会がある中で、下記の課題感から興味を持ちました。
- 子どもを対象としたコンテンツのためひらがながメインで単純な機械翻訳サービスでは誤訳が多い
- 学習素材であるキャラクター名や背景名に固有名詞が多く、事前学習なしの翻訳サービスでは表記ゆれが起こる
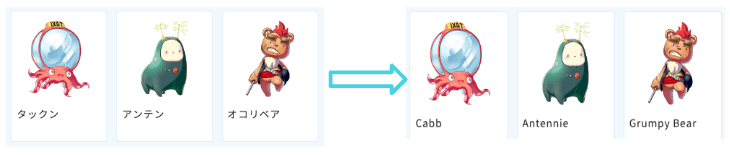
キャラクター名の例
カスタム翻訳モデルの作成
事前準備
AutoML Translationを使う前に準備が必要です。
本記事では詳細手順は割愛しますので詳しくはドキュメントの通りに手順を進めてください。ここでは特段難しいことはなく、作業の要素としては下記の通りです。
- ローカルでgcloud CLIを使えるようにする
- プロジェクトの作成
- 必要なAPI(AutoML Translation, Cloud Storage等)を有効にする
- Cloud Storageに翻訳データのやり取りに使うバケットを作成する
トレーニングデータの用意
前提
前提として、一度人手での翻訳を行った日英の翻訳データがある程度手元にある状況です。モデルに学習させるためにはどうしてもお手本となる良質な教師データが必要であるため、最初はある程度人手での翻訳が必要になります。
用意したデータ
下記のような日英の翻訳データを対にしてデータセットをtsvファイルにして用意します。
チャレンジコースへようこそ!ここでは、ゲームせっけい図を使って1からゲームを作っていくよ! Welcome to the course! Using a game design diagram, we're going to build a game from the ground up!
まずは、今回作るゲームをあそんでみよう! First, let's try playing the game that we will be building!
ゲームせっけい図を使って、メリンの動きを考えるよ! Using the game design diagram, think about Merin's movements!
数としては、多ければ多いほど有用とのことですが、その分コストもかかるので量には注意が必要です。ではどういったデータをどの程度用意したら良いのか?のヒントは最下部のTipsに記載しています。
Cloud Storageへのアップロード
事前準備で作成したバケット [プロジェクト名]-vcm にtsvファイルをアップロードします。私の場合は数回トレーニングを試したため [プロジェクト名]-vcm/dataset_[timestamp] というディレクトリを作り、その配下に複数のデータセットであるtsvファイルを格納しました。
トレーニング
準備が整ったところで、いざ、トレーニング開始です。
- GCPのコンソールを開き、
翻訳 > AutoML Translation > データセットを選択します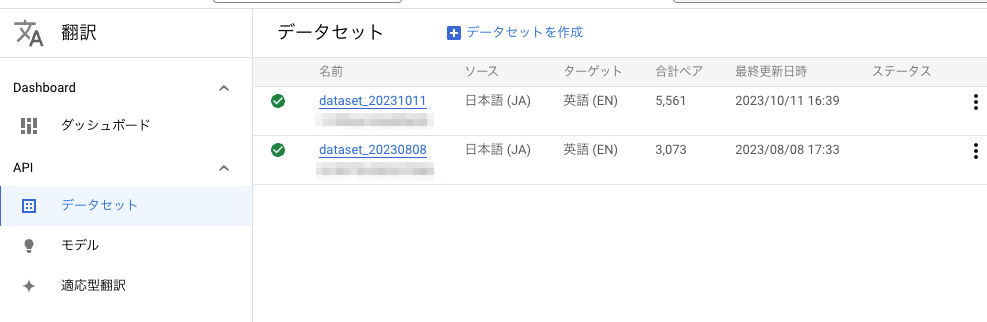
-
データセットを作成をクリックし、日英翻訳の場合、必要な情報を入れて作成ボタンを押します(データセット名はデフォルトの文字列ではなく私の場合はtimestampにしました)
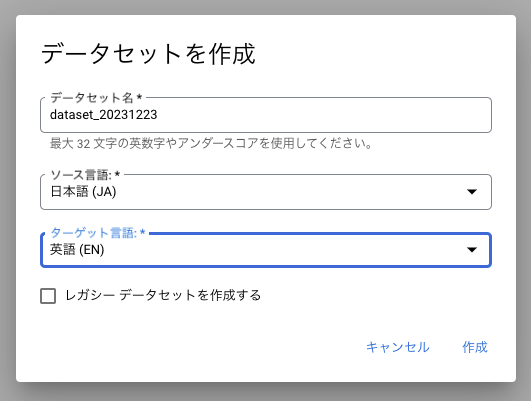
- 作成したデータセットを開き、
インポートタブにて準備したtsvファイルとCloud Storage上の格納場所を指定します
-
続行ボタンを押下します - トレーニングはバッチ処理で行われるため、完了したらメールで通知が届くのでそれまで待ちます
カスタム翻訳モデルの利用
トレーニングが完了したらカスタムモデルの完成です。
ここではトレーニングの結果として得られたものを2つご紹介します。
1. 翻訳の精度判定
評価 のタブを見ると、なにやら BLUE という箇所に数値が入っています。
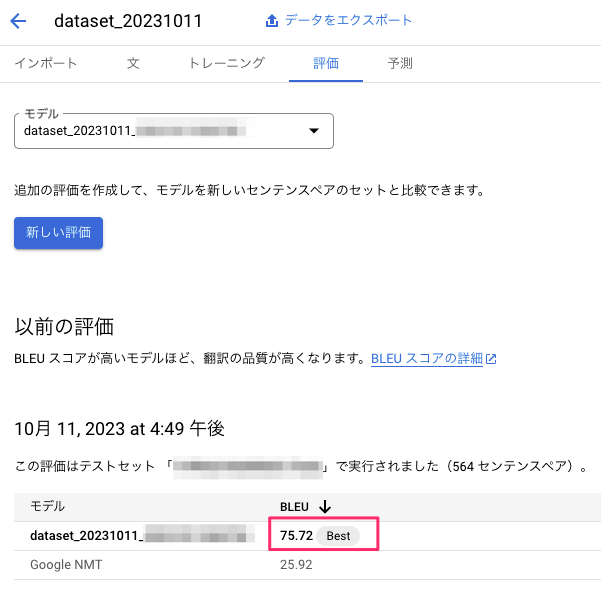
BLUEスコアとは、モデルの品質と精度を評価した値で、翻訳したデータの精度検証が可能です。
ただしBLUEスコアの定義についてはあくまで翻訳前後の一致する単語の割合を示したものという定義なので、流暢さと言ってもそのような評価方法だということは認識しておきましょう。

ちなみにBLUEスコアの下段にあるGoogle NMTというのはニューラル機械翻訳のことで、ベースモデルとなるため比較対象として置いてある認識です。(この辺り専門でないので理解が異なっていたら教えてください)
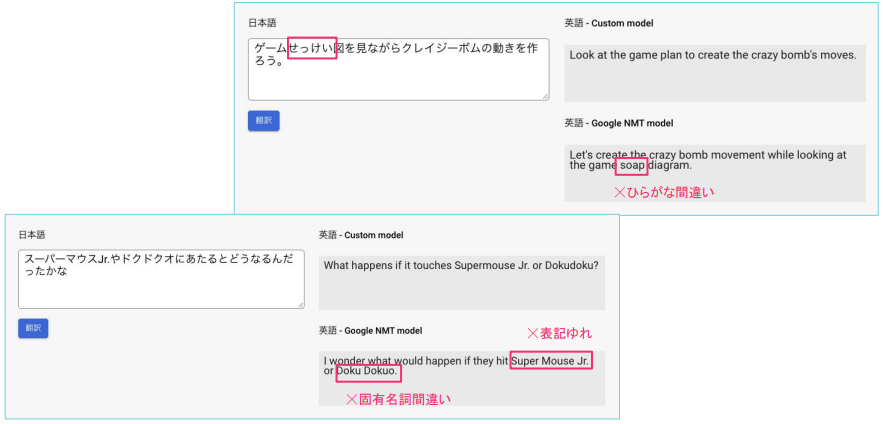
2. カスタムモデルを用いた翻訳
もう一点は 予測 タブでできあがったカスタム翻訳モデルに対して実際に翻訳がかけられるという点です。
図のように、トレーニングをしていないGoogle NMTモデルでは誤訳(というより未知の単語なので知らない)が多いのに対し、カスタムモデルでは意図した訳ができていることがわかります。
利用料金
肝心のコストについてです。トレーニングに使うペア数に応じて課金される仕組みで料金表はこちらです。

※2023年12月現在
私の場合はトレーニングペア数が約5,000だったため2~3時間と試算したものの、実際は半日ほどかかり、料金も完全に上ぶれてしまいました。理由ははっきりわかっていませんがテキスト量も関係したのかと思われます。
トレーニングデータTips
データセットの内容
機械学習の専門ではない私としては、AutoML Translationを使用するにあたって「どんなデータをどの程度学習させたら良いのか?」がわかりませんでした。もちろん手元に存在するすべてのデータセットを使っても良かったのですが、上述のように学習データの量に比例してコストがかかります。なのである程度戦略的にデータを用意する必要があります。
社内のMLエンジニアにも相談した結果、下記のアプローチをとりました。
- できるだけパターンを網羅する
- 最も精度の高い翻訳データを対象とする
1. できるだけパターンを網羅する
学習に使えるデータとしては、文章・単語・カンマ区切りなどの種類がありました。この中でも、文字数的にも固有名詞の出現率的にも 単語 のペアに関してはすべて使いました。( オコリベア[tab]Grumpy Bear 等)
また文章に関しては、サービスのメインキャラクターが話している文章をすべて使いました。これによりサービス全体の口調や世界観を統一することができます。
2. 最も精度の高い翻訳データを対象とする
手元にあった人手翻訳の中でも、目視確認によるクロスチェックを通したものと、そうでないものが存在していました。精度のばらつきを避けるため、トレーニングデータとしてはクロスチェックを通した最も品質の高いデータセットのみを使用しました。
データセットの量
上記の網羅性と品質を担保した上で、トータル5,500個ほどのデータセットを用いてトレーニングを行いました。
まとめ
いちソフトウェアエンジニアが初めてGCPのML/AI製品を使ってみたお話しを記事にしました。
専門知識がなくても手軽に使えて良い時代だなーと思いつつも、チューニングの過程では機械学習に明るいエンジニアやGCP担当者など相談できる人がいたほうがベターだと思いました。
AutoML Translationを利用することで従来であればドメイン知識や専門性が必要が故に外注していた翻訳作業も、コストを抑えて効率的に翻訳できるようになるため検討に入れてみても良いかもしれません。
Discussion