【学習メモ】Goの並行処理を理解しにかかる〜#5-2〜


並列処理と並行処理について
まず、並行処理と並列処理の違いを見ていこうと思います。
よく、並列処理と並行処理は対比して比較されます。ですが、そもそも並列処理と並行処理は対比して比べられる概念ではありません。
後述しますが、並列処理とは複数の処理を実行する物理的な方法のことであり、並行処理とは、問題を最適に解決するためのツール、手法であるからです。
CPU のコアとスレッドについて
まず並列処理が何なのかを理解するために CPU のコアとスレッドについて解説していきます。
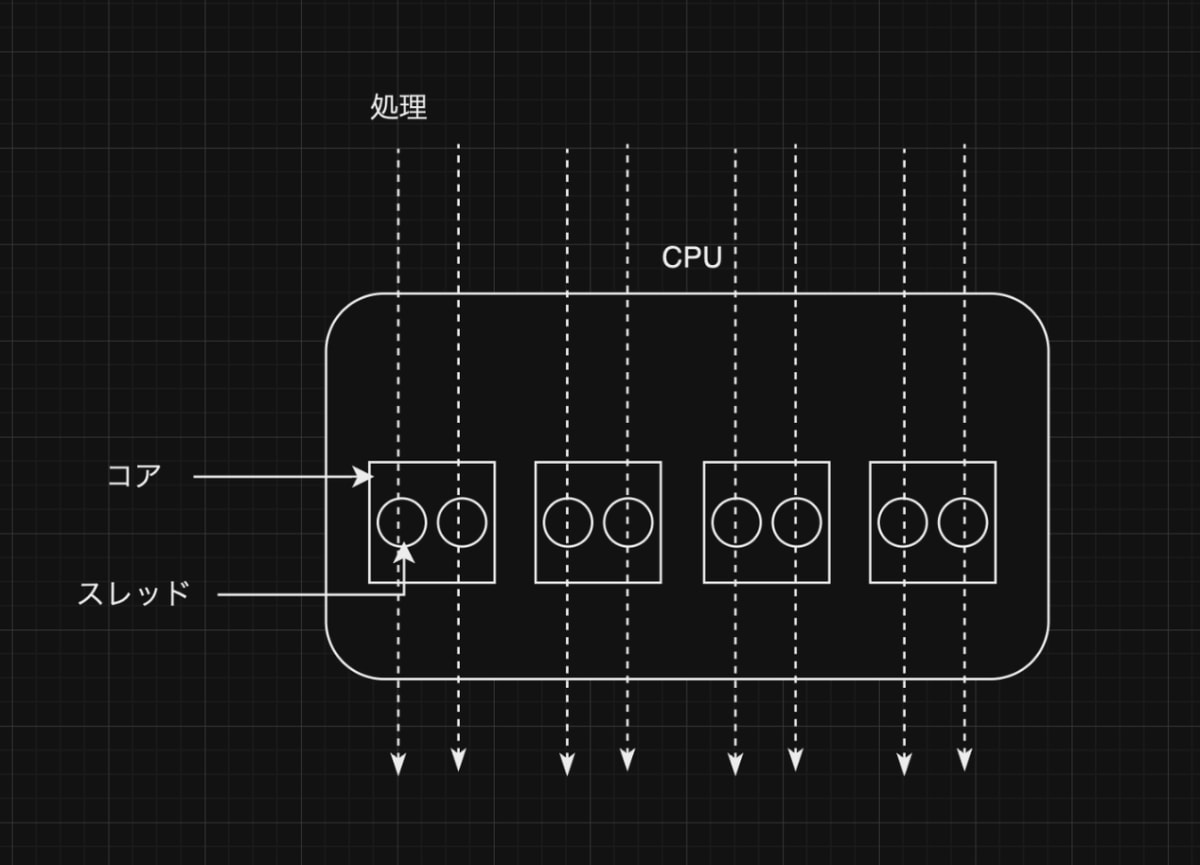
- コアとは:CPU 内部にある演算回路
- スレッドとは:同時に処理できる作業単位のこと
これらのコア数とスレッド数の掛け算で同時に実行できる処理数が決まってくる。
ちょっと上記のテキストだとイメージがつきにくいので、図で説明すると

上記のように CPU 内部にはコアと呼ばれる作業領域がありそれぞれが独立して処理を実行できるようになっています。また、それぞれのコアには同時にいくつ処理を実行できるかを表すスレッドという単位が存在します。
例えば以下のように 4 コア、2 スレッドの場合、同時に 8 つの処理を実行することができます。
並列処理と並行処理の違いについて
では、いよいよですが並行処理と並列処理の違いはなんでしょうか?
- 並列処理
並列処理は上記の通り、複数のコアやスレッドを用いて複数の処理を同時に実行することです
まさに上述した図の通りです!

- 並行処理
では、並行処理はというと複数の処理を切り替えながら実行することで同時に進んでいるように見える手法のことです。ここで勘違いしてはいけないのは並行処理で書かれたコードというのは並列に処理されるかもしれないし、一つのスレッドで交互に入れ替わりながら実行されているかもしれないということです。
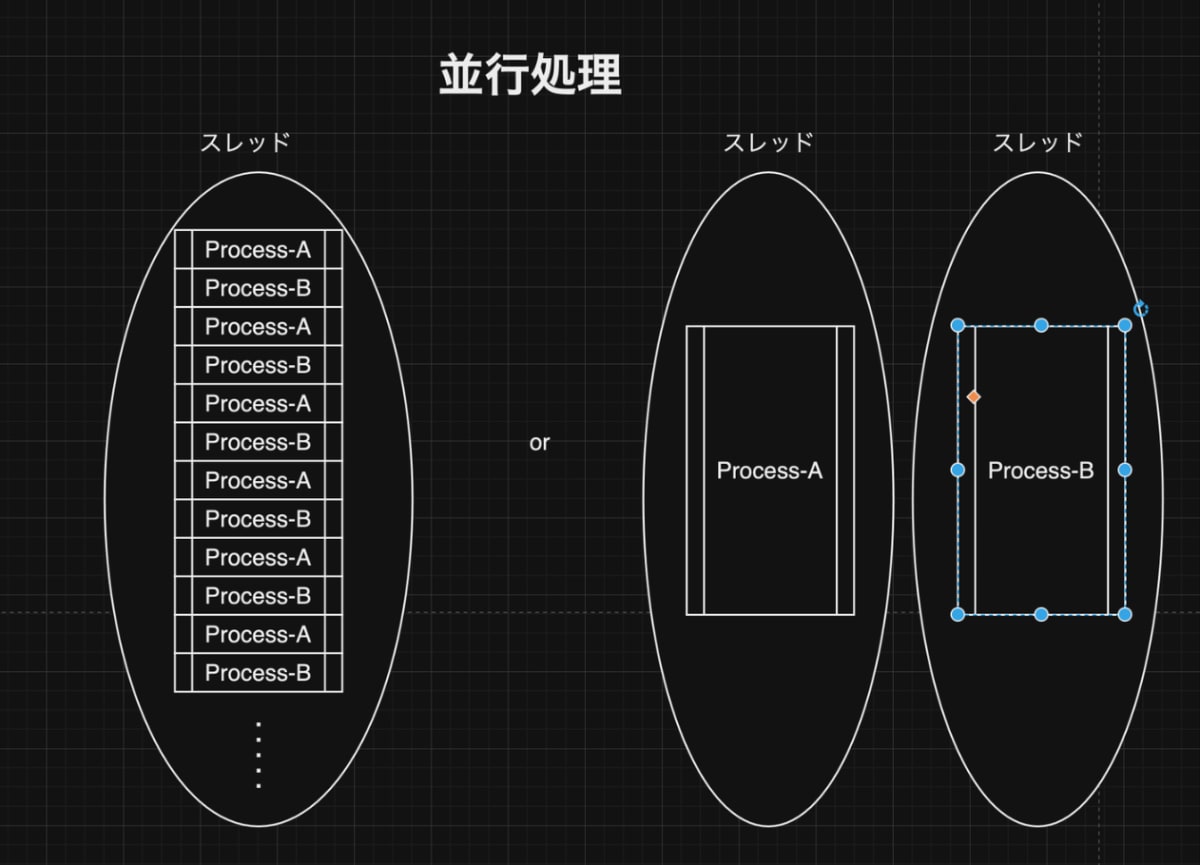
(説明するまでもありませんが、上記の図の右側は並列処理)
ここで重要なのは、並行処理というのは特定の時間内に複数のタスクを実行することであり、その方法は問わないということです。
並行処理のメリット
- 処理が速く実行されるかもしれない
上記で見たとおり、並行処理で記述されたコードは並列に処理される可能性があり処理速度を上げることができるかもしれない。
並行処理のデメリット
並行処理はデメリットがあることも考えておく必要があります。
- 必ずしも処理速度が速くなるとは限らない。
上記で見てきたとおり、必ずしも並列処理で実行されるとは限らないので、速度が速くなるとは限りません。(並行性を持ったコードが並列に実行されるかはハードウェアとアルゴリズムによって決まる) - コードが難解になる
上記のように A という処理と B という処理を並行で走らせた場合、どちらが先に処理を終了するか分かりません。故に上から下に順次実行されるコードと比べると難解になりがちです。
Go で並行処理
Go で並行処理を実装するためには、以下の 3 つの概念を理解し、使用することになります。
- goroutine(ゴルーチン)
sync.WaitGroup- チャネル
goroutine
goroutine を使用するためには、go文を使用します。
goroutine で定義された関数は他のコードに対して、並行に実行されます。(※上記でも記述しましたが、必ずしも並列に処理されるわけではない点に注意)
func main() {
go func() {
fmt.Println("Println in goroutine")
}()
fmt.Printf("goroutines: %d\n", runtime.NumGoroutine())
fmt.Println("main func finish")
}
上記を実行すると大抵以下のような結果になります。(複数回実行することで結果はその都度変わります。)
❯ go run main.go
goroutines: 2
main func finish
上記の結果では、goroutine で定義された関数が実行されていないのがわかると思います。これは、goroutine が実行される前に main 関数自体が終了しまったからです。
runtime.NumGoroutine()はその時点で存在する goroutine の数を返す関数ですが、上記の結果では 2 が返されます。
これは
- main 関数自体
- goroutine で定義された関数
ということで、2 が返されます。
Fork Join model
goroutine はFork Join modelが採用されています。
これはその名のとおり、スレッドが親から子に分岐し、親と並行に実行させる。(Fork)
最終的に親と子が合流する(Join)という流れで進みます。
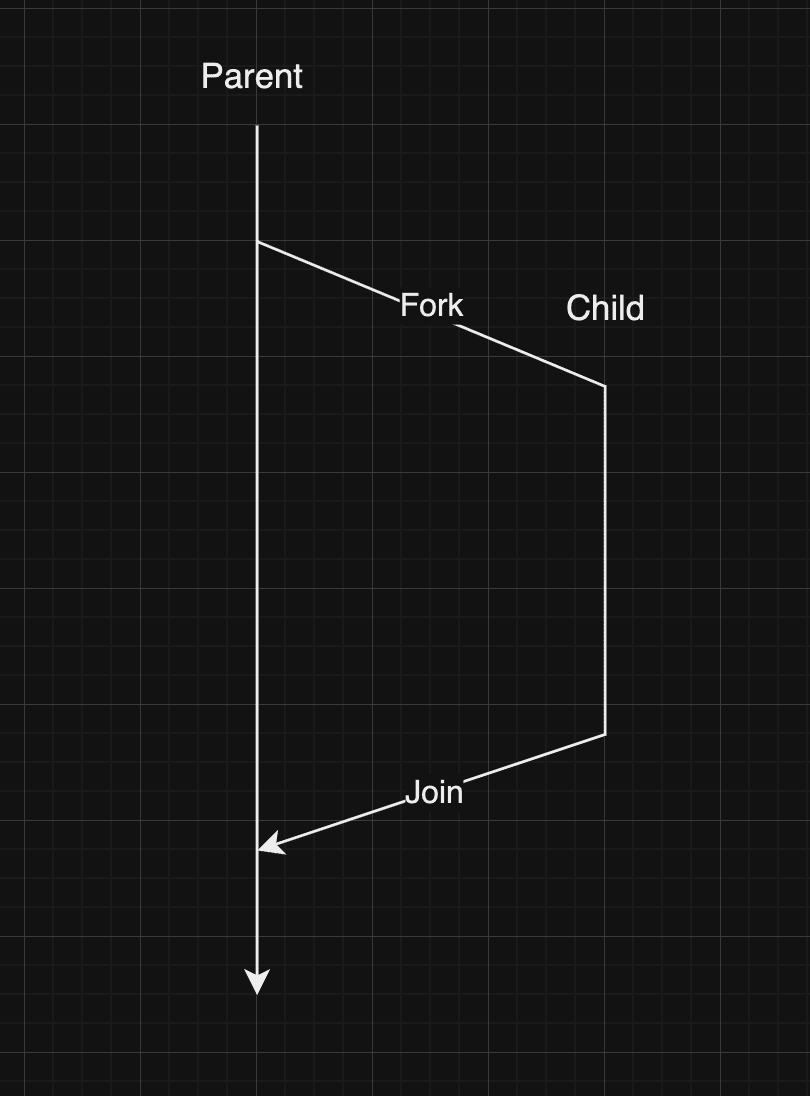
上述したプログラムの結果は、main 関数と goroutine で定義した関数が分岐(Fork)したまま、プログラムが終了した様子です。
これでは、色々困るので、分岐された全ての goroutine が完了するのを待ってからプログラムを終了するためにはsync.WaitGroupを使用します。
sync.WaitGroup
sync.WaitGroupの struct には以下の 3 つのメソッドを持っています。
- Add
- Done
- Wait
使用方法は以下です。
func main() {
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println("Println in goroutine")
}()
wg.Wait()
fmt.Printf("goroutines: %d\n", runtime.NumGoroutine())
fmt.Println("main func finish")
}
- Add の引数には、実行する goroutine の数を指定します。引数で指定された数値が WaitGroup カウンタに追加されます。
- goroutine の中では、処理が終了した時に Done を実行します。Done が実行されると、WaitGroup カウンタから-1(デクリメント)されます。
- Wait のコード箇所で WaitGroup カウンタが 0 になるまで、次の処理が実行されるのを待ちます。
よって、上記のコードは必ず以下のように出力されます。
❯ go run main.go
Println in goroutine
goroutines: 1
main func finish
goroutine の注意点
以下のようなコードを実行した場合
func main() {
var wg sync.WaitGroup
s := []int{1, 2, 3}
for _, v := range s {
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println(v)
}()
}
wg.Wait()
fmt.Println("finish")
}
結果は以下のようになります。
❯ go run main.go
3
3
3
finish
これは、goroutine の関数が実行されるまでに少しタイムラグがあるため、先に for 文が回り切ってしまい、全て 3 が表示されてしまうのです。
スライスの値を順次 goroutine の中で使いたい場合は、以下のように引数で受け取るようにします。
func main() {
var wg sync.WaitGroup
s := []int{1, 2, 3}
for _, v := range s {
wg.Add(1)
go func(i int) {
defer wg.Done()
fmt.Println(i)
}(v)
}
wg.Wait()
fmt.Println("finish")
}
❯ go run main.go
3
1
2
finish
もちろんですが、結果から分かる通り並列処理なので、どの処理が先に実行されるかはその時々で違ってきます。
チャネル
チャネルを使用することで複数の goroutine 間でデータの送受信をすることができる。
- チャネルの定義:
ch := make(chan int) - チャネルの書き込み(write):
ch <- 10 - チャネルの読み込み(read):
<-ch
上記のようにチャネルの wirte と read はチャネルを中心に矢印で表現されます。
※注意点:バッファなしのチャネルを定義した場合
バッファなしのチャネルを定義した場合、チャネルへの書き込み処理は、チャネルの読み込み処理が実行されるまで待ち続けます。
よって、以下のコードはデッドロックを引き起こします。
func main() {
ch := make(chan int)
ch <- 10 //ここでストップ
fmt.Println(<-ch)
}
通常チャネルはこのような使い方はされず、goroutine 間(異なるスレッド間)でデータをやり取りする際に使用されます。
func main() {
ch := make(chan int)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
ch <- 10
}()
fmt.Println(<-ch) //10
wg.Wait()
}
上記では、main スレッドと goroutine のスレッドで別々に処理が走り、main スレッド側でチャネルの読み込みがされるまで待ったのち、goroutine で定義された関数内のチャネルへの書き込みが実行されます。
上記のコードを以下のようにした場合、デッドロックが発生します。
func main() {
ch := make(chan int)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
ch <- 10
}()
wg.Wait() // 読み込み処理が走らないため、goroutineは処理を終了できず、ここで待ち続けるためデッドロック
fmt.Println(<-ch)
}
goroutine リーク
以下のコードはチャネルの書き込み処理を待ち続けてそのまま main 処理が終了してしまうケースです。
func main() {
ch := make(chan int)
go func() {
fmt.Println(<-ch)
}()
fmt.Printf("goroutines: %d \n", runtime.NumGoroutine()) //2
}
このように goroutine がいつまで経っても Join できない状態を goroutine リークと言います。
goroutine リークを検知するためのテストライブラリがあるので、これらを使用してテストしておくと良い。("go.uber.org/goleak")
func TestLeak(t *testing.T) {
defer goleak.VerifyNone(t)
main() //goroutineリークを評価したい関数
}
バッファ付きのチャネル
バッファ付きのチャネルの場合、バッファがいっぱいになるまでは、チャネルの読み込み処理を待たなくてもチャネルの書き込みができるという仕様になっているので、先ほど見てきたデッドロックを心配する必要はない。
func main() {
ch := make(chan int, 1)
ch <- 2
fmt.Println(<-ch) //2
}
ただし、以下のようなバッファサイズがいっぱいの場合は、デッドロックが発生する
func main() {
ch := make(chan int, 1)
ch <- 2
ch <- 3 //バッファサイズがいっぱいのため、チャネルの読み込みがされるまで待ち続ける
fmt.Println(<-ch)
}
チャネルのクローズ
以下のように不要になったチャネルはclose(ch)でクローズすることができる。
func main() {
ch := make(chan int)
var wg sync.WaitGroup
wg.Add(1)
go func() {
defer wg.Done()
ch <- 10
}()
v, ok := <-ch
fmt.Printf("%v %v \n", v, ok) // 10 true
wg.Wait()
// チャネルをクローズ
close(ch)
v, ok = <-ch
fmt.Printf("%v %v \n", v, ok) // 0 false
}
バッファ付きのチャネルの場合は、少し挙動が変わっており、クローズされた後でも書き込みされた全ての値が読み込まれるまで読み込み可となる。
func main() {
ch := make(chan int, 2)
ch <- 10
ch <- 20
close(ch)
v, ok := <-ch
fmt.Printf("%v %v\n", v, ok) //10 true
v, ok = <-ch
fmt.Printf("%v %v\n", v, ok) //20 true
v, ok = <-ch
fmt.Printf("%v %v\n", v, ok) //0 false
}
チャネルのカプセル化
以下のgenerateCountStream関数のように定義することで戻り値が読み取り専用のチャネルとなる関数を定義することができる。
こうすることで関数内にチャネルの生成と書き込みは閉じ込めることができる。
func main() {
ch := generateCountStream()
for v := range ch {
fmt.Println(v)
}
}
func generateCountStream() <-chan int {
ch := make(chan int)
go func() {
defer close(ch)
for i := 0; i < 5; i++ {
ch <- i
}
}()
return ch
}
また、main 関数内の range はgenerateCountStream関数内でチャネルがクローズされるまで回り続ける。
データの値を持たない通知専用のチャネル
以下はデータのやり取りをする目的ではなく、通知用に作成されたチャネルです。
func main() {
var wg sync.WaitGroup
ch := make(chan struct{})
for i := 0; i < 5; i++ {
wg.Add(1)
go func(n int) {
defer wg.Done()
fmt.Printf("goroutine: %d\n", n)
<-ch
fmt.Println(n) //ここの処理はchがcloseされるまで走らない。
}(i)
}
time.Sleep(2 * time.Second)
close(ch) //ここでgoroutine内のPrintlnが一気に発火する
wg.Wait()
}
上記にコメントの通り、goroutine 内の Println の処理はclose(ch)が走った後に、一気に実行されることになります。
これはバッファなしのチャネルの書き込みは読み込みされるか close されるまで待ち続けるという特徴を利用して、何かしらの処理が終わったことを通知する目的で使われています。
select
セレクトを使用することで複数のチャネルから受信することができるようになります。以下はその例です。
func main() {
ch1 := make(chan string)
ch2 := make(chan string)
var wg sync.WaitGroup
wg.Add(2)
go func() {
defer wg.Done()
time.Sleep(500 * time.Millisecond)
ch1 <- "A"
}()
go func() {
defer wg.Done()
time.Sleep(800 * time.Millisecond)
ch2 <- "B"
}()
for ch1 != nil || ch2 != nil {
select {
case v := <-ch1:
fmt.Println(v)
ch1 = nil
case v := <-ch2:
fmt.Println(v)
ch2 = nil
}
}
wg.Wait()
fmt.Println("finish")
}
上記では、select-caseで 2 つのチャネルの値を読み込みしています。
for 文の終了条件をチャネルが読み込まれるまでとすることで、どちらのチャネルも読み込まれるまで for 文が回り続けるという流れです。
セレクトでタイムアウトを受け取る
以下は、タイムアウトを設定し、指定された時間内に処理が終了しなかった場合に呼び出し元にキャンセルを通知する例です。
func main() {
ch1 := make(chan string, 1)
ch2 := make(chan string, 1)
var wg sync.WaitGroup
ctx, cancel := context.WithTimeout(context.Background(), 300*time.Millisecond)
defer cancel()
wg.Add(2)
go func() {
defer wg.Done()
time.Sleep(500 * time.Millisecond)
ch1 <- "A"
}()
go func() {
defer wg.Done()
time.Sleep(800 * time.Millisecond)
ch2 <- "B"
}()
loop:
for ch1 != nil || ch2 != nil {
select {
case <-ctx.Done():
fmt.Println("timeout")
break loop
case v := <-ch1:
fmt.Println(v)
ch1 = nil
case v := <-ch2:
fmt.Println(v)
ch2 = nil
}
}
wg.Wait()
fmt.Println("finish")
}
まず、以下でタイムアウトの時間を指定しています。
ctx, cancel := context.WithTimeout(context.Background(), 300*time.Millisecond)
defer cancel()
ここでは、300 ミリ秒待って終わらなければ、キャンセルが実行されるようにしています。
context.Context(上記ではctxの変数)には Done()という読み取り専用かつ通知用チャネルを返すメソッドを保持しています。
Done() <-chan struct{}
タイムアウトし、キャンセルが実行されると、自然と Done チャネルはクローズされます。それを通知するためにセレクト内に case を一つ追加しています。
select {
case <-ctx.Done():
fmt.Println("timeout")
break loop
//省略
}
これでタイムアウトが発生した場合、セレクトの for 文を抜ける用の条件が追加されたという流れです。
注意が必要なのは、このままでは、ch1 と ch2 のチャネルが読み込まれることがなく、goroutine が永遠に終わらないので、wg.Wait()でデッドロックを起こしてしまいます。
そのため、チャネルをバッファ付きのチャネルにする必要があります。
mutext
以下のように goroutine で定義した関数で同じ変数に対してインクリメントを実行するコードがある。
func main() {
var wg sync.WaitGroup
var i int
wg.Add(2)
go func() {
defer wg.Done()
i++
}()
go func() {
defer wg.Done()
i++
}()
wg.Wait()
fmt.Println(i) // 2 or 1
}
この場合、基本的には2が表示されるが、このコードでは排他制御をしていないので、同時にインクリメントが走った場合、最終的にi=1となる可能性もある。
このような場合に排他制御を行ってくれるのが、sync.Mutexとなる。
func main() {
var wg sync.WaitGroup
var mu sync.Mutex
var i int
wg.Add(2)
go func() {
defer wg.Done()
mu.Lock()
defer mu.Unlock()
i++
}()
go func() {
defer wg.Done()
mu.Lock()
defer mu.Unlock()
i++
}()
wg.Wait()
fmt.Println(i) // 2 or 1
}
上記のとおり、Lock()でロック、Unlock()で解放となる。
また、このようなデータ競合の検知をしてくれるのが、-raceコマンドである。
go run -race main.go
context
context の 1 番の使用目的はメインの goroutine からサブ goroutine を一斉にキャンセルさせること。

上記のとおり、context を作成するためには第一引数に親の context を指定する必要があるが、トップのコンテキストの作成にはcontext.Background()を使う。
よく使用されるコンテキストは以下
-
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)- 特に指定なくコンテキストを作成したい場合。用途としては、サブ goroutine でタイムアウトなどでキャンセルが発生した場合に、他のサブ goroutine にもキャンセルを伝搬させる用途で使用
-
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc)- 第二引数で指定した時刻内に終わらなかった場合、キャンセル
-
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)- 第二引数で指定した時間内に終わらなかった場合、キャンセル
Discussion