Pythonについて勉強していく
Pythonに入門する
Pure Python
実装上の最小値
import sys
sys.float_info.min # 2.2250738585072014e-308
プログレスバー
print(f"\r\033[K{i}", end="")
リストの偶数番目・奇数番目の要素を取得する。原理として、リストをスライスする際に [start:stop:step] のように増分(ステップ)を指定できる。
l = [0, 1, 2, 3]
print(l[0::2]) # [0, 2]
print(l[1::2]) # [1, 3]
内側のループをbreakした場合のみ後続の処理を実行する。
if else のインデントがずれていても問題ないらしい(使いたくはない)。
for x in iterable_x:
for y in iterable_y:
if x == y:
break
else:
print(f"{x} has no duplicates.")
HTTP Server
python -m http.server 8000
リスト同士の重複を抽出する。
a = [1, 2, 3]
b = [4, 5, 6]
set(a) & set(b) # {2, 3}
Null合体演算子を使いたい。
None or "string" # string
0 or "string" # string
"" or "string" # string
NumPy
Pandas
列Aのユニークな要素ごとに、最後の行を取得する。
df.reset_index().groupby("A", as_index=False).last() # インデックスも列として保持
df.index = df["index"] # インデックスを再度割り当て
列Aのユニークな要素ごとに、最後の行以外を取得する。
df[~df.index.isin(df.index)]
インデックスの列名
df.index.name = "index"
df = pd.DataFrame(
index=pd.Series([0, 1, 2], name="index"),
columns=["a", "b", "c"],
)
df = pd.DataFrame(
index=pd.Series(name="index"),
columns=["a", "b", "c"],
)
- (df_result["S_CODE"] != transaction["S_CODE"])[df_result["S_CODE"] != transaction["S_CODE"]]
+ (df_result["S_CODE"] != transaction["S_CODE"])[lambda x: x]
df.itertuples() でループしたとき、タプルのインデックスは row.index ではなく row.Index 。
Pandasの要素の中にリストを格納する。
PandasのEDAの初手をやってくれるVSCodeの拡張機能
Pandasのstr.contins()で、リスト内のいずれか文字列を含むかどうかを判別する。
読み込み時のデータ型指定。読み込み時に指定しないと、最初に float として読み込まれた値を str に変換する際、値が 12345.0 のようになったりする。
PARSE_DATES = ["date"]
DTYPE = {"string": str}
columns = list(DTYPE.keys()) + PARSE_DATES
df = pd.read_csv(path, usecols=columns dtype=DTYPE, parse_dates=PARSE_DATES)
ラップしたやつ
def read(path, dtype, parse_dates=None, **kwargs):
columns = list(dtype.keys())
if parse_dates is not None:
columns += parse_dates
return pd.read_csv(
filepath_or_buffer=path,
usecols=columns,
dtype=dtype,
parse_dates=parse_dates,
**kwargs,
)
ラップしたやつ2
def read(columns, **kwargs):
usecols = [col for (col, _) in columns.values()]
names = [name for name in columns.keys()]
dtypes = {name: dtype for (name, (_, dtype)) in columns.items() if dtype != "datetime"}
parse_dates = [name for (name, (_, dtype)) in columns.items() if dtype == "datetime"]
return pd.read_csv(
filepath_or_buffer=path,
usecols=usecols,
names=names,
dtype=dtypes,
parse_dates=parse_dates,
**kwargs
)
pd.read_csv
Pandasでデータを読み込む場合、型を指定して読み込むのが望ましい。
例えば、 00123 というIDが 123 という整数として読み込まれてしまうから。
しかし、nullを含む場合だと int 型や bool 型を指定するとエラーが出る。
ValueError: Bool column has NA values in column ...
データにnullが含まれているとき、 bool 型を指定する場合は "boolean" を、 int 型を指定する場合は "Int64" を、代わりに指定する。
DTYPE = {
"nullable_number": "Int64",
"nullable_flag": "boolean",
}
継承
と似たようなことをする。
df.groupby & agg
df = df.groupby("category").agg({
"amount": "mean",
"quantity": "sum",
})
リストを要素として扱う
リスト形式の要素を列方向に展開する
df.explode("column")
リスト形式の要素を列方向に展開する。
df["column"] = df["column"].str.strip("[]")
df["column"] = df["column"].str.split(",", expand=True)
三項演算子みたいなことをする
df.loc[df["mask"], "X"] = df["Y"]
tenacity
Pythonでリトライ処理を簡単に書けるライブラリ
Streamlit
st.text_input() によって代入された st.session_state の値がリセットされることがある。
def main():
# ステートを表示
st.write(st.session_state)
# 初回レンダリング
if "fuga" not in st.session_state:
st.session_state.hoge = "hoge"
st.text_input("テキストを入力", key="fuga") # "fuga"と入力
return
# 次回以降レンダリング
st.button("ボタン")
return
初回レンダリング時の st.session_state 。値は格納されていない。

テキスト入力後の st.session_state 。明示的に代入した hoge と st.text_input() によって代入された fuga が格納されている。
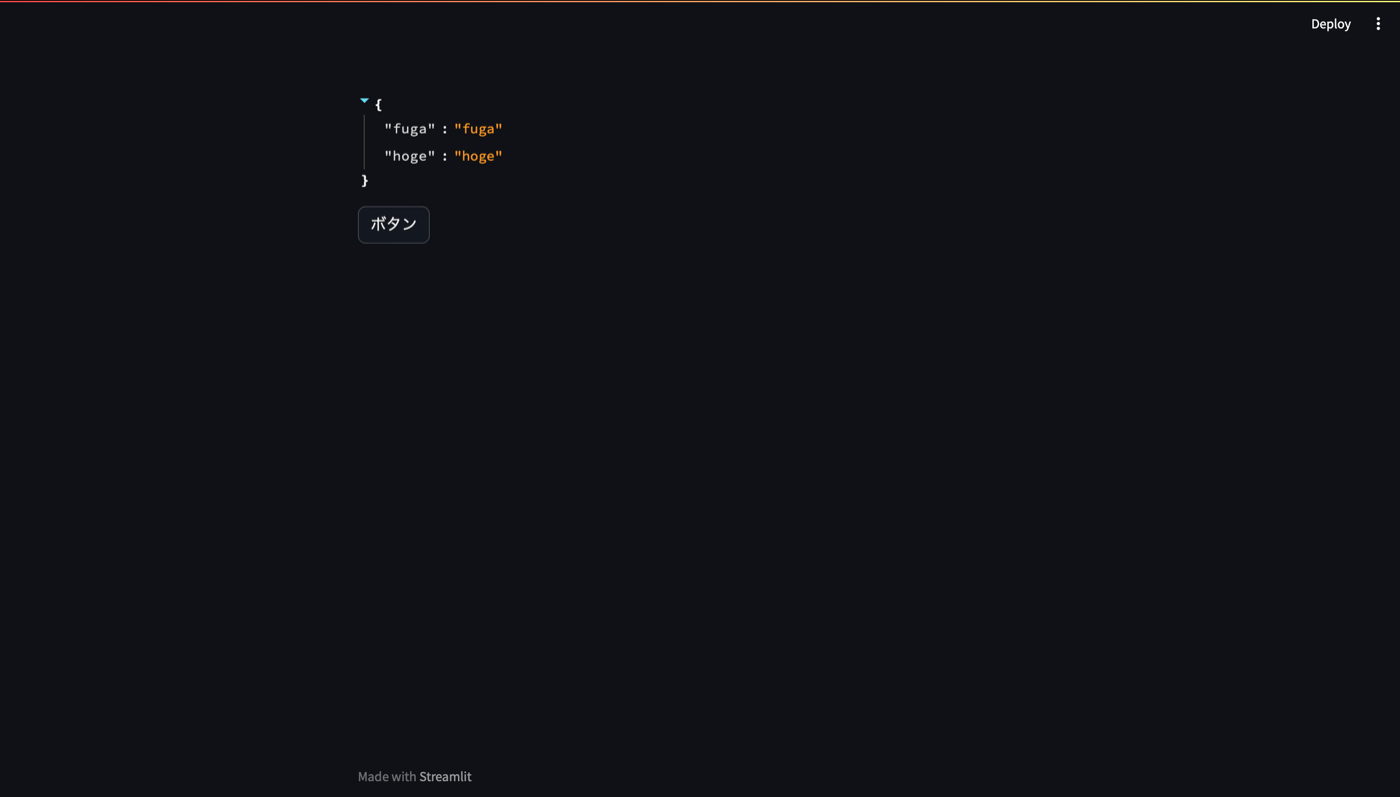
ボタン押下後の st.session_state 。明示的に代入した hoge は維持されているが、 st.text_input() によって代入された値 fuga がリセットされている。

意図があってそのような管理仕様になっているとは思うが、解決方法が分からない。
そのため、以下のように対処療法的に対応している。
def main():
# ステートを表示
st.write(st.session_state)
# 初回レンダリング
if "fuga" not in st.session_state:
st.session_state.hoge = "hoge"
st.text_input("テキストを入力", key="fuga") # "fuga"と入力
return
# 次回以降レンダリング
st.session_state.fuga = st.session_state.fuga # ステートを明示的に代入
st.button("ボタン")
return
よく使うやつ
Ryeで構築する分析環境
$ rye init playground
$ cd playground
$ rye add numpy pandas matplotlib seaborn plotly ipykernel
$ rye sync
$ . .venv/bin/activate
import pandas as pd
def read(dtype, parse_dates=None):
columns = list(dtype.keys())
if parse_dates is not None:
columns += parse_dates
return pd.read_csv(
filepath_or_buffer="hoge.csv",
usecols=columns,
dtype=dtype,
parse_dates=parse_dates,
)
def format_hoge(df, init_value=""):
df["hoge"] = df["hoge"].fillna(init_value)
return df
def format_fuga(df, init_value=0):
fuga = subsets["fuga"]
df.loc[fuga > 0, "fuga"] = init_value
return fuga
def format_piyo(df, init_value="1900-01-01"):
init_datetime = pd.Timestamp(init_value)
df["piyo"] = df["piyo"].fillna(init_datetime)
return df
"nullable_number": ,
"nullable_flag": ,
}
PARSE_DATES = ["piyo"]
DTYPE = {
"id": str,
"hoge": int, # 欠損値がある場合は `"Int64"` を使用
"fuga": bool, # 欠損値がある場合は `"boolean"` を使用
}
df = read(DTYPE, PARSE_DATES)
df = format_hoge(df)
df = format_fuga(df)
df = format_piyo(df)
df = df.set_index("id")- まずは前処理を当てずにDTYPEの指定だけ(インデックスの指定もなし)で読み込む。
- Data Wranglerで見る。
- 欠損値(
Mising)はあるか? - 値の重複(
Distinct)はあるか?(行数と比較) - 最小値(
Min)・最大値(Max)は何か? - カテゴリ変数の値は?
- 異常値の確認:カテゴリ変数を一覧にする、最大値・最小値を見る。
- 欠損値(
- 前処理を当てて異常値がなくなるようにする。
カテゴリ変数の一覧: df["column"].value_counts()
最大値・最小値:Sort ascending or Sort descending
Rye
RyeでJupyter Notebookを使う。
rye add ipykernel
RyeでCUDA依存のパッケージをインストールする
マーケ分析
カテゴリ別売上ランキング
df = orders.join(items["category"], on="item_id")
df = df.groupby("category").agg({
"amount": "sum",
"quantity": "sum",
})
df.sort_values("amount", ascending=False)
RFM分析
class RFM:
def __init__(
self,
records: pd.DataFrame = None,
r_thresholds: list[str] | None = None,
f_thresholds: list[int] | None = None,
):
assert (
type (r_thresholds) == list and
type (f_thresholds) == list
), "Thresholds must be a list."
self.records = records # id, user, item, amount, quantity, created
self.rth = [pd.Timestamp(th) for th in r_thresholds]
self.fth = f_thresholds
# user
self.users = self.records.groupby("user").agg({
"created": ["last", "count"],
})["created"]
# item
self.items = self.records.groupby("item").agg({
"amount": "sum",
"quantity": "sum",
})
# matrix
self.users["recency"] = self.users["last"].apply(self.filter, thresholds=self.rth)
self.users["frequency"] = self.users["count"].apply(self.filter, thresholds=self.fth)
self.matrix = self.users.value_counts(["recency", "frequency"])
self.matrix = self.matrix.sort_index()
def filter(self, value, thresholds=None):
for i, threshold in enumerate(thresholds):
if value < threshold:
return i + 1
return len(thresholds) + 1
How to use
rfm = RFM(records,
r_thresholds=["2022-07-01", "2022-11-01"],
f_thresholds=[2, 3],
)
print(rfm.matrix) # RFM分析の結果を表示
df = rfm.items.join(items["category"])
df["category"] = df["category"].fillna("")
df = df.groupby("category").sum()
df = df.sort_values("amount", ascending=False)
print(df) # # カテゴリ別ランキング(売上順)を表示
Ruff
Linter。(たしか)Ryeにも載ってる。