Open23
SQLを勉強していく
SQLに入門する
分散トランザクション Sagaパターン
3層スキーマ
インデックス
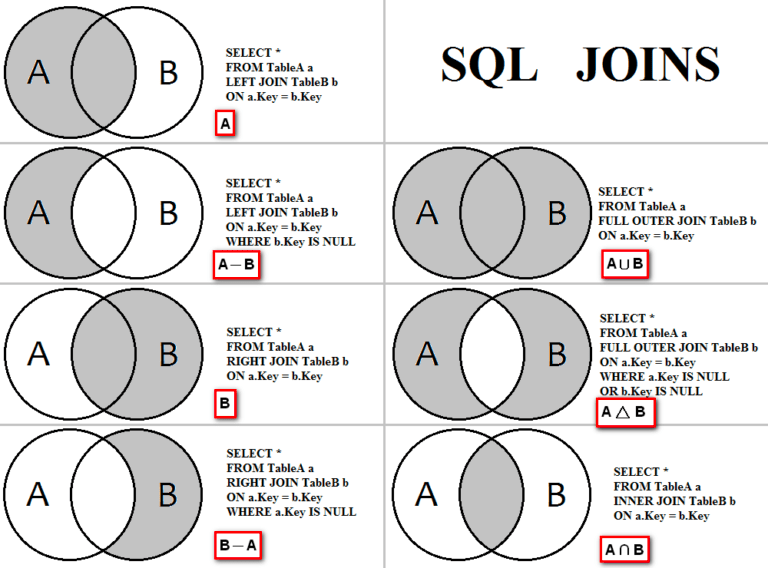
JOIN
評価順序
FROM
ON
JOIN
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
ORDER BY
TOP(LIMIT)
あれ、もしかして一対多のテーブルに右も左もない…?
多対一(左・右)ならinner joinもleft outer join同じ結果になるはず…
一対一なら A = B
多対一なら A ⊃ B
多対多なら A ∩ B ≠ φ
であってるのか…?
チューニング
- SQLを工夫して組み立てる。
- DBサーバーのメモリを調整する。
- インデックスを貼る。
- テーブルを工夫して設計する。
JOINは重い。
- インデックス
-
ON句を使う。 - サブクエリの階層を減らす。
-
WHERE句で扱うデータを絞る。
「DBが読み込む・取得するデータ量を減らす」
インデックスが活用されるように、「条件内にインデックス対象カラムを適切に記述しましょう」
- 加工をしない。
- 順番を揃える。
サブクエリ内ので不要なカラムをSELECTしない
- 通常テーブル内のデータ(レコード)は、TableSpace (≒ハードディスク)で保持されている
- クエリが実行されると、バッファプール(≒メインメモリ)上に必要なテーブルデータがロードされる。
- 処理に必要なデータ(レコード・カラム)がバッファプールに入り切らない場合、都度ディスクからデータを読み取る必要がある(I/O が発生する)
GROUP BYで一意にする。
index貼ってると早いらしい。
Pythonのset的な。
JOINするよりWHERE ~ IN ~。
インデックスはデータが綺麗に並んでいる。
INSERT時に綺麗に並べてインデックスに加えることで、読み込み速度が速くなる。
EXISTS ≒ INNER JOIN > IN
SQLite
SQLiteはMacにデフォルトでインストールされている。
データベースの作成
$ cd db
$ sqlite3 database_name.db
CSVをインポートしてテーブルを作成
sqlite3
.mode csv
.import csv_file_path table_name