Claude MCPを使って「RSS → AI要約 → Notion保存」の朝ルーティン効率化に挑戦してみた
📝 はじめに
毎日AIの進化が囁かれていますが、私の日課は変わらず「朝一のRSSで記事チェック」から始まっています。
正直、この運用しんどい…。
だいたい毎日300件ほどのタイトルにざっと目を通して 気になったものを「後で読む」に保存し、空き時間に消化する毎日。
「これ、AIを活用して効率化できるのでは?」と思い、日曜開発のテーマとして RSS処理の自動化 に挑戦してみました。
最終的には、
- 自分の興味に合った記事だけをピックアップ
- 記事の要約を自動生成
- まとめを毎朝Notionに通知
といった理想像を描いています。
今回はその第一歩として、Claude MCPを使った仕組みづくり を実装してみました。
🎯 今回つくったもの
- RSSから記事を取得
- Claudeで必要な記事をピックアップ&要約
- Notionに保存
まだ最終形には遠く、「体感40点」くらいの仕上がりですが、精度や自動化が未完成だからこそ40点 という意味です。
仕組みとしてはちゃんと動いているので、最後まで見ていただけると嬉しいです!
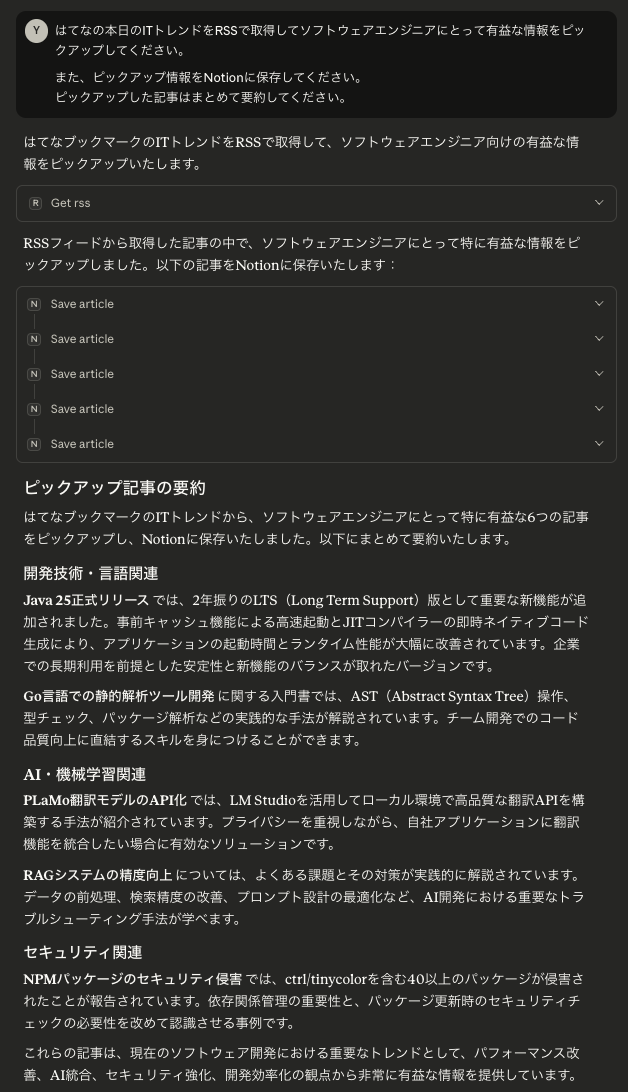
はてなブックマークのITトレンドから記事のピックアップを依頼 @Claude

Notionに記事が自動的に登録された状態 @Notion
ちゃんと当日のはてなブックマークのランキングからピックアップされた記事が要約され、Notionに保存されていることを確認することができました。
🔧 技術スタック
- ChatGPT: 実装方針やコード生成などのエージェント
- Claude Desktop + MCP: Claudeに外部ツールを接続
-
Python: RSS/Notion向けのMCPサーバーを実装
-
feedparser: RSSフィード取得 -
requests: Notion API呼び出し -
python-dotenv:.envでAPIキー管理
-
- Notion API: 記事保存先
🏗️ 実装の流れ
1. Notionで保存先DBを準備
- Notion My Integrations で Internal Integration を作成
- APIキー(最近は
ntn_...形式)を発行 - アウトプット用のデータベースを用意して、インテグレーションを接続(「… → Add connections」から追加)
- DB URLから Database ID を取得
📂 DB設計イメージ
| カラム名 | タイプ | 用途 |
|---|---|---|
| Title | Title | 記事タイトル |
| URL | URL | 記事リンク |
| Summary | Text | Claude生成の要約 |
| Date | Date | 公開日 or 取得日 |
2. Notion MCPサーバー
Claudeから利用するMCPサーバーをPythonで実装しました。(ChatGPT作)
from dotenv import load_dotenv
import requests
import os
from mcp.server.fastmcp import FastMCP
load_dotenv()
server = FastMCP("notion")
NOTION_API_KEY = os.getenv("NOTION_API_KEY")
DB_ID = os.getenv("NOTION_DB_ID")
@server.tool()
def save_article(title: str, url: str, summary: str, date: str):
headers = {
"Authorization": f"Bearer {NOTION_API_KEY}",
"Notion-Version": "2022-06-28",
"Content-Type": "application/json"
}
body = {
"parent": {"database_id": DB_ID},
"properties": {
"Title": {"title": [{"text": {"content": title}}]},
"URL": {"url": url},
"Summary": {"rich_text": [{"text": {"content": summary}}]},
"Date": {"date": {"start": date}}
}
}
res = requests.post("https://api.notion.com/v1/pages", headers=headers, json=body)
return res.json()
if __name__ == "__main__":
server.run()
コードの内容はシンプルで、登録情報を引数に受け取ってNotion APIで対象のDBにデータを保存しにいく処理になっています。
ハマりポイントとしてPCにPython実行環境が備わっている必要があります。
今回私はpython3をインストールしました。
また、生成してもらったソースコードはそのままでは実行できず、エラーメッセージをChatGPTに投げながら改修を加えていきました。具体的にはmcp.serverのimport方法が悪くうまくAPIを利用できないよう状態でした。
また、今回Notion APIを使ってアウトプット情報をNotionに保存する際に利用するAPIキーをコードの中で直接記述していたのですが、これがうまく参照できないようでした。
解決策として、.envファイルを別途用意して、load_dotenv()経由でAPIキーとDB IDを読み込ませるようにしています。
3. RSS MCPサーバー
記事一覧の取得はfeedparserを利用。(ChatGPT作)
import feedparser
from mcp.server.fastmcp import FastMCP
server = FastMCP("rss")
@server.tool()
def get_rss(url: str):
"""Fetch RSS feed entries safely"""
feed = feedparser.parse(url)
entries = []
for e in feed.entries:
entries.append({
"title": getattr(e, "title", ""),
"link": getattr(e, "link", ""),
"published": getattr(e, "published", getattr(e, "updated", ""))
})
return entries
if __name__ == "__main__":
server.run()
取得元のRSSの構成によっては取得できにない項目があったりしたので、ひとまず今回取れない場合があった、updated要素があってもなくてもコードがコケないような形にしました。
🧪 動作確認の工夫
ChatGPTがが出してくれたコードはそのまま動かないことが多いので、以下のステップでデバッグしました。
まず、ClaudeにMCPサーバーとして読み込ませた時に発生したエラーとしてPythonのシンタックスエラーについてはエラーメッセージからすぐに原因を特定することができたので直接コードを書き換えて対応しました。(わからなければChatGPTにそのままエラーメッセージを投げると改善策を提示してくれると思います。)
ただ、MCPサーバーとして読み込ませることができても、データの取得エラーはコードの実行エラーが発生して想定の動きをしてくれない事象が発生しました。今回は権限エラーによってNotionに保存できない事象がが発生していました。
発行したAPIキーがまずいのか、DB IDがおかしいのかなどの棲み分けができなかったので、curlでNotion APIを直接叩くことで検証しました。
curl -X POST "https://api.notion.com/v1/pages" \
-H "Authorization: Bearer ntn_xxxxxxxxx" \
-H "Content-Type: application/json" \
-H "Notion-Version: 2022-06-28" \
--data '{
"parent": { "database_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" },
"properties": {
"Title": {
"title": [
{
"text": {
"content": "APIテスト"
}
}
]
}
}
}'
RSS取得は想定のテーブル構造と異なる場合は実行エラーが発生してしまっていたので、ある程度のエラーハンドリング等を行うことでエラーを解消しました。
Web検索を有効にすることで、取得が正常にできなくてもうまく取り直してくれたりはできるのでそこまで致命的なエラーには今回はなりませんでした。
🔮 今後の展望
- 事前にピックアップしたサイト情報から自動的に情報を取ってきてもらう
- Notionで日誌を生成するワークフローの中にトリガーを仕込む
- cronで毎朝自動実行してNotionに「今日のまとめ」を溜める
- 自分の興味のある情報や必要な情報を覚えさせる
今回はピックアップする指標が「ソフトウェアエンジニアにとって有益な情報」といったコンテキストしか伝えることができていないので、精度がイマイチです。私の日誌の情報といった独自コンテキストをプロンプトに加えていくことによって精度が向上していくのではないかと期待しています。
✅ まとめ
- Claude MCPを使って RSS → AI要約 → Notion保存 の仕組みを作った
- 最低限ピックアップした記事だけに絞ってNotionに保存される状態を実現
- 自分の興味に合わない記事もピックアップされることがある
- インプット効率化の第一歩! 🚀
Discussion