【dbt】dbt-external-tables
※ChatGPT
✅ dbt run-operation stage_external_sources
- 既存のソースがあれば更新し、新規があれば作成する
- メタデータの更新が必要な場合のみリフレッシュする
- 既存のテーブルを削除・再作成しない
- 通常運用向け(必要な更新だけを実施)
✅ dbt run-operation stage_external_sources --vars "ext_full_refresh: true"
- すべての外部テーブルを削除し、作成し直す
- メタデータを強制的に更新する
- テーブルの入れ替えが発生するため、依存関係のあるジョブに影響する可能性がある
- スキーマの変更があった場合や、メタデータが壊れている場合に使用
どちらを選ぶべきか?
- 通常の運用 →
dbt run-operation stage_external_sources - スキーマ変更やリフレッシュが必要な場合 →
ext_full_refresh: trueを指定
もし影響を最小限にしたいなら、通常は ext_full_refresh: true なしで運用し、必要に応じてフルリフレッシュを実施するのが良いと思います。
packages:
- package: dbt-labs/dbt_external_tables
version: 0.11.1
APIから取得されるJSONをdbtで蓄積することを考える
サンプル
[
{
"id": 123,
"user": {
"name": "John",
"email": "john@example.com"
},
"tags": [
"tech",
"cloud"
],
"update_at": "2025-01-01 00:00:00"
},
{
"id": 124,
"user": null,
"tags": [
"data",
"analytics"
],
"update_at": "2025-01-02 12:00:00"
}
]
前提条件: update_atは項目の編集で更新されるが、項目の追加や削除で更新されない
想定データフロー
Cloud Storageに保存する形式検討
BigQuery では、次の形式の Cloud Storage データのクエリがサポートされています。
- カンマ区切り値(CSV)
- JSON(改行区切り)
- Avro
- ORC
- Parquet
- Datastore エクスポート
- Firestore エクスポート
てstてst
ストレージコストを考えParquetにする
変換スクリプト
import json
import pandas as pd
# JSON ファイルを読み込む
with open("sampile.json", "r", encoding="utf-8") as infile:
data = json.load(infile)
# フラット化(ネストを解除)
df = pd.json_normalize(data)
# Parquet ファイルに変換(pyarrowを使用)
df.to_parquet("sampile.parquet", engine="pyarrow", index=False)
出力結果
{"id":123,"tags":["tech","cloud"],"update_at":"2025-01-01 00:00:00","user.name":"John","user.email":"john@example.com","user":null}
{"id":124,"tags":["data","analytics"],"update_at":"2025-01-02 12:00:00","user.name":null,"user.email":null,"user":null}
BQに外部テーブルとして取り込み
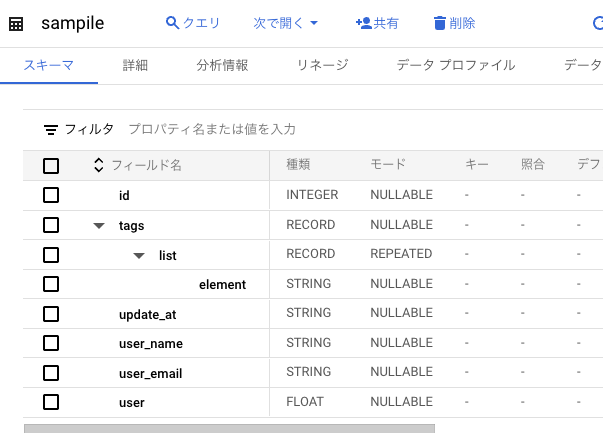
dbtのsnapshot ってBQのネストされたカラムに対応しているのか
→ ネスト列は展開する必要がありそう。
展開方法は2つ
- user.nameの項目をuser__nameで展開しフラット化する
- ネスト項目が多くなるとカラム数が多くなり、parquetの列圧縮の恩恵があまり受けれずファイル容量が空くなるなりづらい
- dbt snapshotで増分項目の摘発はしやすい
import json
import pandas as pd
# JSON ファイルを読み込む
with open("sampile.json", "r", encoding="utf-8") as infile:
data = json.load(infile)
df = pd.json_normalize(data)
df.columns = df.columns.str.replace('.', '__')
# Parquet ファイルに変換(pyarrowを使用)
df.to_parquet("sampile.parquet", engine="pyarrow", index=False)
{"id":123,"tags":["tech","cloud"],"update_at":"2025-01-01 00:00:00","user__name":"John","user__email":"john@example.com","user":null}
{"id":124,"tags":["data","analytics"],"update_at":"2025-01-02 12:00:00","user__name":null,"user__email":null,"user":null}

2. 単一項目でないものは、文字列として格納する
- 列数が多くなりづらい
- あとで展開する必要がある
import json
import pandas as pd
# JSON ファイルを読み込む
with open("sampile.json", "r", encoding="utf-8") as infile:
data = json.load(infile)
def convert_nested_objects_to_string(record):
for key, value in record.items():
if not isinstance(value, (int, float, str, bool, type(None))): # 単一の値かどうかを判定
record[key] = json.dumps(value, ensure_ascii=False) # JSON 文字列に変換
return record
# すべてのレコードに対して変換を適用
data = [convert_nested_objects_to_string(record) for record in data]
# フラット化(ネストを解除)
df = pd.json_normalize(data)
# Parquet ファイルに変換(pyarrowを使用)
df.to_parquet("sampile.parquet", engine="pyarrow", index=False)
{"id":123,"user":"{\"name\": \"John\", \"email\": \"john@example.com\"}","tags":"[\"tech\", \"cloud\"]","update_at":"2025-01-01 00:00:00"}
{"id":124,"user":null,"tags":"[\"data\", \"analytics\"]","update_at":"2025-01-02 12:00:00"}

GCSのファイル構成
- API からデータ取得 → GCS に YYYYMMDD.json と latest.json を保存
- 外部テーブル(latest.json)を使って最新データをクエリ
- dbt-external-tablesで外部テーブル更新
- dbt spanpshotで全カラム指定でcheck戦略の更新
- 必要に応じてJSONを展開して保存
import json
import pandas as pd
from datetime import datetime
# JSON ファイルを読み込む
with open("sampile.json", "r", encoding="utf-8") as infile:
data = json.load(infile)
def convert_nested_objects_to_string(record):
for key, value in record.items():
if not isinstance(value, (int, float, str, bool, type(None))): # 単一の値かどうかを判定
record[key] = json.dumps(value, ensure_ascii=False) # JSON 文字列に変換
return record
# すべてのレコードに対して変換を適用
data = [convert_nested_objects_to_string(record) for record in data]
# フラット化(ネストを解除)
df = pd.json_normalize(data)
df["imported_at"] = datetime.utcnow() # UTCで統一
print(df)
# Parquet ファイルに変換(pyarrowを使用)
df.to_parquet("sampile.parquet", engine="pyarrow", index=False)
version: 2
sources:
- name: work
database: ~
schema: work
tags:
- porters
loader: gcloud storage
tables:
- name: event
external:
location: 'gs://~output.parquet'
options:
format: parquet
freshness:
error_after: {count: 3, period: hour}
loaded_at_field: imported_at
dbt run-operation stage_external_sources --args "select: work" --vars "ext_full_refresh: true"
dbt source freshness --select source:work
'data_tests' セクションを使用する方法が最も柔軟で管理しやすいでしょう。全てのカラムを取り込みつつ、必要なテストだけを指定できる
- name: field
data_tests:
- unique:
column_name: id
- not_null:
column_name: id
下記の書き方だと、id列しか取り込まれない
- name: field
columns:
- name: id
data_tests:
- unique
- not_null
設定されたテストは、dbt test --store-failures が呼び出されたときに失敗を保存します。この設定をfalseに設定してもstore_failures_asが設定されていれば、上書きされます。
data_tests:
+store_failures: true # all tests
<package_name>:
+store_failures: false # tests in <package_name>
dbt run-operation stage_external_sources --args "select: 〜〜〜" --vars "ext_full_refresh: true"
カラムの増減を予想して--vars "ext_full_refresh: true"
ちなみにTROCCOのdbt連携ではdbt run-operationの--vars オプション未対応
dbt source freshness --select source:〜〜〜
でロードされているの確認
dbt build --select tag:〜〜〜,tag:snapshot --store-failures
でスナップショット
型エラーはスナップショットないのクエリでcastして型変換する
--vars "ext_full_refresh: true"によって推論されたデータ型が変わることで
スナップショット時にデータ型変更のエラーが変わることを検知してスナップショット実行前にワークフローを止めたい
公式の記事に、このような場合の対処法が載っていました。以下の2つです。
https://discourse.getdbt.com/t/snapshots-when-column-data-type-changes/10452/2
① スナップショットを保存する際に型を戻す。例えばsafe_cast(sex as int64) as sexとする
② スナップショットテーブルの列の型を手動で変えておく
今回は②で対処します
上記の対応でもいいが
{% macro my_macro() %}
{% set old_relation = source("sample", "field") %}
{% set dbt_relation = ref("sample_snapshot__field") %}
{% set excluded_columns = [
"dbt_scd_id",
"dbt_updated_at",
"dbt_valid_from",
"dbt_valid_to",
"gcs_imported_at",
] %}
{% set comparison_query %}
{{ audit_helper.compare_relation_columns(
a_relation=old_relation,
b_relation=dbt_relation
) }}
{% endset %}
{% set sql_query %}
with
check_list as (
select *
from ({{ comparison_query }})
where not column_name in ('{{ excluded_columns | join("', '") }}')
)
select countif(in_both = false) = 0 as validation_result
from
check_list
{% endset %}
{% set results = run_query(sql_query) %}
{% if execute %}
{% set validation_result = results.columns[0].values()[0] %}
{% if validation_result %}
{% do log(
"✅ データ型チェック成功:すべてのカラム整合性が確認されました",
info=True,
) %}
{% else %}
{% do log(
"❌ データ型不一致:check_list CTEで不一致カラムを確認してください",
info=True,
) %}
{% endif %}
{% endif %}
{% endmacro %}
compare_relation_columnsを使用
$ dbt run-operation my_macro
✅ データ型チェック成功:すべてのカラム整合性が確認されました
これもありかな
ext_full_refresh: trueそこに設定できるの><
version: 2
sources:
- name: cricinfo
database: "{{ env_var('ENV_CODE') | trim | upper }}_{{ env_var('PROJ_CODE') | trim | upper }}_RAW_DB"
schema: "CRICSHEET"
loader: S3
tables:
- name: all_player_details
ext_full_refresh: true
external:
location: "@{{ env_var('ENV_CODE') | trim | upper }}_{{ env_var('PROJ_CODE') | trim | upper }}_RAW_DB.CRICSHEET.TST_ENTECHLOG_CRICSHEET_S3_STG/cricinfo/" # required: S3 file path, GCS file path, Snowflake stage, Synapse data source
file_format: >
(TYPE = JSON)
partitions:
- name: file_name
data_type: varchar
expression: metadata$filename
columns:
- name: player_data
data_type: varchar
↑デマだった dbt_project.ymlに書いたらいけた
vars:
# dbt-external-tables
ext_full_refresh: true
stagingで行う処理の一例として、
テーブル名の修正
カラム名の修正
カラムのデータ型の修正
カラムの構造(STRUCT)化
JSONのパース
数値IDへのラベル付与
タイムゾーン(UTC、JST)の統一
重複データの削除
データの誤りの修正
dbt source freshnesはdbt biuldに含まれないかつ、TROCCOのdbt連携で選択できないコマンドなので、dbt testで同じ実装を行う
{% test data_freshness(
model, column_name, error_after_count, error_after_period, filter
) %}
with
freshness_check as (
select max({{ column_name }}) as max_loaded_at
from {{ model }}
{% if filter %} where {{ filter }} {% endif %}
)
select
max_loaded_at,
{{ dbt.current_timestamp() }} as executed_at,
{{ dbt.datediff("max_loaded_at", dbt.current_timestamp(), error_after_period) }}
as diff_count
from freshness_check
where
{{ dbt.datediff("max_loaded_at", dbt.current_timestamp(), error_after_period) }}
>= {{ error_after_count }} -- エラーになる閾値
{% endtest %}
genericテスト仕組み
- 0レコードで成功
- 1以上のレコードが発生していると失敗する
dbt.datediff
dbt.datediffがコンパイルされるとBQ環境だとdatetime_diffになります。
この関数は2つの日付の差ではなく、「差に近しいもの」を返す関数だった問題ありますが
error_after_countを2以上にしたら問題ないと思っているので、一旦これで
データ鮮度テスト (Data Freshness Test)
このカスタムgeneric testは、柔軟な時間単位でデータの鮮度をチェックします。指定した期間と回数に基づき、データの更新頻度を検証します。
目的
- モデル内のデータが定期的に更新されていることを保証
- 時間単位(hour/day/minuteなど)を柔軟に指定可能
- 閾値超過時にエラーを発生させる
使用方法
version: 2
models:
- name: orders
columns:
- name: last_updated_at
tests:
- data_freshness:
error_after_count: 3 # エラーになる閾値
error_after_period: "hour" # 時間単位(hour/day/minuteなど)
パラメータ
| パラメータ | 型 | 必須 | 説明 |
|---|---|---|---|
error_after_count |
integer | Yes | エラーになる閾値 |
error_after_period |
string | Yes | 時間単位(dbtのdatediffでサポートされる単位) |
動作フロー
- 対象モデルから最大のタイムスタンプを取得
- 現在時刻との差分を指定単位で計算
- 差分が
error_after_count以上の場合にテスト失敗
主な特徴
- 柔軟な時間単位: 時間/分/日など任意の単位で設定可能
-
厳格なチェック:
>=演算子を使用し閾値を含めて判定 - 詳細な出力: 差分値とタイムスタンプを表示
使用例
# 8時間以上経過したらエラー
error_after_count: 8
error_after_period: "hour"
# 3日以上経過したらエラー
error_after_count: 3
error_after_period: "day"
# 15分以上経過したらエラー
error_after_count: 15
error_after_period: "minute"
注意事項
-
datediffの挙動はデータベースによって異なる場合があります - タイムゾーン設定を環境全体で統一する必要があります
- パフォーマンス影響が出る場合は
max()の代わりに別の方法を検討 -
error_after_periodは小文字で指定する必要があります
わざわざ、dbt source freshnessとdbt test2度うちしなくてもdbt testだけで問題ない
version: 2
sources:
- name: ~~
database: ~~
schema: ~~
loader: gcloud storage
tables:
- name: ~~
external:
location: 'gs://~~~~.parquet'
options:
format: parquet
freshness:
warn_after: {count: 5, period: hour}
error_after: {count: 15, period: hour}
loaded_at_field: gcs_imported_at
data_tests:
- unique:
column_name: id
- not_null:
column_name: id
- data_freshness:
column_name: gcs_imported_at
error_after_count: 15
error_after_period: hour
後続のスナップショットでこけた時
audit_helperのパッケージ必要
下記のクエリで内容確認
{% set old_relation = source("ソーステーブル") %}
{% set dbt_relation = ref("スナップショットテーブル") %}
{% set excluded_columns = [
"dbt_scd_id",
"dbt_updated_at",
"dbt_valid_from",
"dbt_valid_to",
"gcs_imported_at",
] %}
{% set comparison_query %}
{{ audit_helper.compare_relation_columns(
a_relation=old_relation,
b_relation=dbt_relation
) }}
{% endset %}
{% set check_col = "null" %}
with
check_list as (
select *
from ({{ comparison_query }})
where not column_name in ('{{ excluded_columns | join("', '") }}')
),
has_match_list as ( -- マッチしていない項目確認
select *
from check_list
where not (has_ordinal_position_match and has_data_type_match)
)
{% if check_col %}
,
col_check_list as ( -- マッチしていないカラムの内容
select {{ check_col }}
from {{ old_relation }}
where {{ check_col }} is not null
)
{% endif %}
select *
from has_match_list
公式の記事に、このような場合の対処法が載っていました。以下の2つです。
① スナップショットを保存する際に型を戻す。例えばsafe_cast(sex as int64) as sexとする
② スナップショットテーブルの列の型を手動で変えておく
今回は②で対処します。
alter table `ucchi_test_snapshot`
rename column sex to sex_old;
alter table `ucchi_test_snapshot`
add column sex string;
update `ucchi_test_snapshot`
set sex = cast(sex_old as string)
where true;
alter table `ucchi_test_snapshot`
drop column sex_old;
パーケットに保存する際は、nullを保持したまますべてのカラムをstringに
import json
import datetime
import pandas as pd
from typing import Dict, Any, List
from util.log import log
def convert_json_to_parquet(data, output_parquet_path) -> None:
"""
JSONファイルを読み込み、Parquet形式に変換して保存する関数。
"""
log("INFO", f"Start converting JSON to Parquet: {output_parquet_path}")
# キーのピリオドをアンダースコアに変換する
data = replace_keys(data)
# すべてのレコードに対して変換を適用
data = [convert_nested_objects_to_string(record) for record in data]
# フラット化(ネストを解除)
df = pd.json_normalize(data)
# 全カラムを nullable string に変換、nullを保持したまま文字列型にできる
for col in df.columns:
df[col] = df[col].astype("string")
# 現在のUTC日時を追加
df["gcs_imported_at"] = datetime.datetime.now(datetime.timezone.utc)
# Parquet ファイルに変換(pyarrowを使用)
df.to_parquet(output_parquet_path, engine="pyarrow", index=False)
log("INFO", f"Parquet file saved: {output_parquet_path}")
def convert_nested_objects_to_string(record):
"""
ネストされたオブジェクトをJSON文字列に変換する関数
Args:
record (dict): 変換対象のレコード
Returns:
dict: ネストされたオブジェクトをJSON文字列に変換したレコード
"""
for key, value in record.items():
if not isinstance(value, (int, float, str, bool, type(None))): # 単一の値かどうかを判定
record[key] = json.dumps(value, ensure_ascii=False) # JSON 文字列に変換
return record
def replace_keys(obj: Any) -> Any:
"""オブジェクト内のすべてのキーのピリオドをアンダースコアに置換します。
Args:
obj (Any): 処理対象のオブジェクト。辞書、リスト、またはその他の型が可能です。
Returns:
Any: キーのピリオドがアンダースコアに置換された新しいオブジェクト。
入力が辞書やリストでない場合は、入力をそのまま返します。
Examples:
>>> replace_keys({"a.b": 1, "c": {"d.e": 2}})
{'a_b': 1, 'c': {'d_e': 2}}
"""
if isinstance(obj, dict):
new_obj = {}
for key, value in obj.items():
new_key = key.replace(".", "_").lower()
new_obj[new_key] = replace_keys(value)
return new_obj
elif isinstance(obj, list):
return [replace_keys(item) for item in obj]
else:
return obj
✅ 標準モード(メタデータの更新のみ)
$ dbt run-operation stage_external_sources
# 既存のものがあればCREATE EXTERNAL TABLEされない
1 of 1 START external source ~.~
1 of 1 SKIP
- すべての external source ノードを走査します。
- 必要に応じて
CREATE EXTERNAL TABLEを実行。 - 既存の external table がある場合は メタデータを更新(REFRESH) のみ行います。
🔁 フルリフレッシュモード(作り直し)
$ dbt run-operation stage_external_sources --vars "ext_full_refresh: true"
# CREATE EXTERNAL TABLEされる
1 of 1 START external source porters.option
1 of 1 (1) create or replace external table `〜`.`〜`.`〜` ...
1 of 1 (1) None (0 processed)
- すべての external source ノードを走査します。
- 各 external table を CREATE OR REPLACE で作り直し、必要に応じてメタデータも更新します。
💡 補足
この機能は、外部テーブル(例:GCSやS3上のファイル)を dbt source として扱う際に便利です。
通常は標準モードで十分ですが、スキーマやファイルパスが変更された場合は ext_full_refresh: true を付けてフルリフレッシュを行うと安全です。
dat_project.ymlでvarsで定義すると--vars "ext_full_refresh: true"毎回描かなくていいていうのと、TROCCOのdbt連携でdbt run-operationで--varsが使えないためこっちで定義する必要ある
vars:
# dbt-external-tables
ext_full_refresh: true
columnsの設定について
- もし定義するのであれば、カラムの増減がないことが保証されている必要がある
かりに、columnsがidの1つのカラムが指定される場合
columns:
- name: id
data_type: STRING
下記のクエリになり
create or replace external table `~`.`~`.`~`(
id STRING
)
options (
uris = ['gs://~_*.parquet']
, format = 'parquet'
)
idカラムしかないテーブルになる
ちなみに、nameしかない場合はエラーになるのでdata_typeも設定しましょう
そのため、カラムの増減が予想されるテーブルは、columnsを設定しない
dbt-osmosis yaml refactor
で自動でカラム情報が入る場合は、除外設定しましょう
meta:
dbt-osmosis-skip-add-columns: true
version: 2
sources:
- name: ~~
database: ~~
schema: ~~
loader: gcloud storage
meta:
dbt-osmosis-skip-add-columns: true
tables:
- name: ~~
external:
location: 'gs://~~~~.parquet'
options:
format: parquet
freshness:
warn_after: {count: 5, period: hour}
error_after: {count: 15, period: hour}
loaded_at_field: gcs_imported_at
data_tests:
- unique:
column_name: id
- not_null:
column_name: id
- data_freshness:
column_name: gcs_imported_at
error_after_count: 15
error_after_period: hour
columns: []