TROCCOのカスタム変数を活用したdbtによる増分更新
この記事は TROCCO® Advent Calendar 2024 2日目 と dbt Advent Calendar 2024 2日目 シリーズ2 の記事です。
思いがけず2つのアドベントカレンダーにリンクことになった
はじめに
TROCCOのカスタム変数機能を活用したdbtによる増分更新の紹介をします。
※ dbtに関しての細かな説明は割愛しています、、、
増分更新の概要
増分更新では、データ全体を処理するのではなく、変更や追加された部分のみを対象とします。このアプローチにより、以下のメリットが得られます
- 処理時間の短縮: 不必要な再処理を回避。
- 計算コストの削減: クラウド環境でのクエリ実行コストが抑えられる。
TROCCOのカスタム変数機能とdbtの連携
カスタム変数機能の活用
TROCCOのカスタム変数機能を利用することで、dbt実行時に動的に値を設定できます。たとえば、増分更新期間(start_date や end_date)を変数で指定可能です。
dbtの増分更新モード
- dbtでは
is_incremental()という関数を用いて、増分更新用のクエリを定義できます。 - TROCCOのカスタム変数を使用するメリット : TROCCOのカスタム変数で更新期間を指定していると、データが欠損した場合TROCCOからデータ更新期間を変更することでbackfill(埋め戻し)処理が可能です。
TROCCOのカスタム変数機能を活用することで、dbtで増分更新の期間を簡単に設定できます。ここでは、具体的な設定例を見ていきます。
使用例
-
CURRENT_DATEを使用パターン(Before)
{% if is_incremental() %}
WHERE DATE(created_at) = CURRENT_DATE('Asia/Tokyo') - 1
{% endif %}
- TROCCOのカスタム変数を使用パターン(After)
{% if is_incremental() %}
WHERE DATE(created_at) BETWEEN '{{ var('start_date') }}' AND '{{ var('end_date') }}'
{% endif %}
検証パターン
増分更新において、考えられる典型的な検証パターンとして、以下の3つを確認します。それぞれのパターンに通して、TROCCOのカスタム変数機能を活用したdbtによる増分更新の紹介していきます。
- ソースデータの前日データが入ってない状態
- ソースデータの前日データが更新された状態
- ソースデータのデータ欠損が修正された状態
検証環境
dbt=1.8.2
dbt-bigquery=1.8.1
TROCCO
BigQuery
作業日
SELECT CURRENT_DATE('Asia/Tokyo') AS today
| today |
|---|
| 2024-11-07 |
1. ソースデータの前日データが入ってない状態(サンプルデータ作成)
- 期待される結果 : ターゲットテーブルには変更がないこと。
データの特徴
- データの欠損日:2024-11-02、2024-11-03
- データの未更新日(前日):2024-11-06
サンプルデータ作成
以下のSQL文でサンプルデータを作成します。
CREATE OR REPLACE TABLE `work.customer` (
name STRING
, age INT64
, created_at TIMESTAMP
) AS (
SELECT *
FROM UNNEST (
ARRAY<STRUCT<
name STRING
, age INT64
, created_at TIMESTAMP
>> [
('田中太郎', 45, '2024-11-01 10:00:00')
, ('佐藤花子', 25, '2024-11-01 14:30:00')
, ('鈴木一郎', 30, '2024-11-02 09:15:00')
, ('高橋美紀', 27, '2024-11-04 07:25:00')
, ('渡辺陽一', null, '2024-11-04 16:50:00')
, ('加藤隆', 22, '2024-11-05 10:05:00')
]
)
)
customer テーブル(ソースデータ)
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
dbtの設定
version: 2
sources:
- name: work # データソースの名前
schema: work # スキーマ名
tables:
- name: customer # テーブル名
{{ config(
materialized = 'incremental',
incremental_strategy = 'insert_overwrite',
partition_by = {
'field': 'created_at',
'data_type': 'timestamp',
'granularity': 'day',
'copy_partitions': true
}
) }}
SELECT *
FROM {{ source('work', 'customer') }}
{% if is_incremental() %}
WHERE DATE(created_at) BETWEEN '{{ var('start_date') }}' AND '{{ var('end_date') }}'
{% endif %}
TROCCO(dbt連携)の設定
customer テーブルから customer_salary テーブル作成
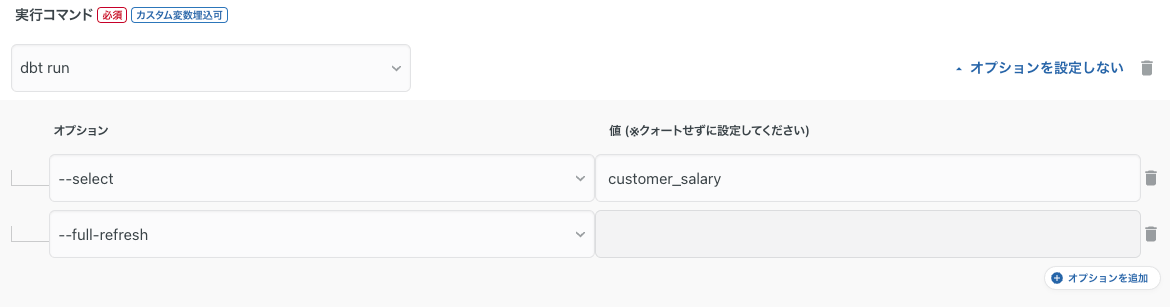
dbt run --select customer_salary --full-refresh
↓ 実行結果 ↓
customer_salary テーブル(ターゲットテーブル)
--full-refreshを指定しているため、{% if is_incremental() %}〜{% endif %}の中の条件が無視されて実行される。
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
2. ソースデータの前日データが更新された状態
- 検証目的 : ソースデータが更新された場合に、増分更新処理で最新のデータが適切に反映されることを確認します。
-
手順 : サンプルデータを再作成して、前日のデータが更新された状態を再現する
- データの未更新日(前日):2024-11-06
- 期待される結果 : ターゲットテーブルに前日データ追加されていること。
CREATE OR REPLACE TABLE `work.customer` (
name STRING
, age INT64
, created_at TIMESTAMP
) AS (
SELECT *
FROM UNNEST (
ARRAY<STRUCT<
name STRING
, age INT64
, created_at TIMESTAMP
>> [
('田中太郎', 45, '2024-11-01 10:00:00')
, ('佐藤花子', 25, '2024-11-01 14:30:00')
, ('鈴木一郎', 30, '2024-11-02 09:15:00')
, ('高橋美紀', 27, '2024-11-04 07:25:00')
, ('渡辺陽一', null, '2024-11-04 16:50:00')
, ('加藤隆', 22, '2024-11-05 10:05:00')
, ('小林健', 35, '2024-11-06 17:25:00')
, ('佐々木裕', 28, '2024-11-06 15:40:00')
]
)
)
customer テーブル(ソースデータ)
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
| 佐々木裕 | 28 | 2024-11-06 15:40:00.000000 UTC |
| 小林健 | 35 | 2024-11-06 17:25:00.000000 UTC |
dbtの設定
dbt_project.ymlに設定していないとエラーになるので設定しておく
vars:
start_date : NULL
end_date : NULL
dbtジョブ設定(TROCCO)
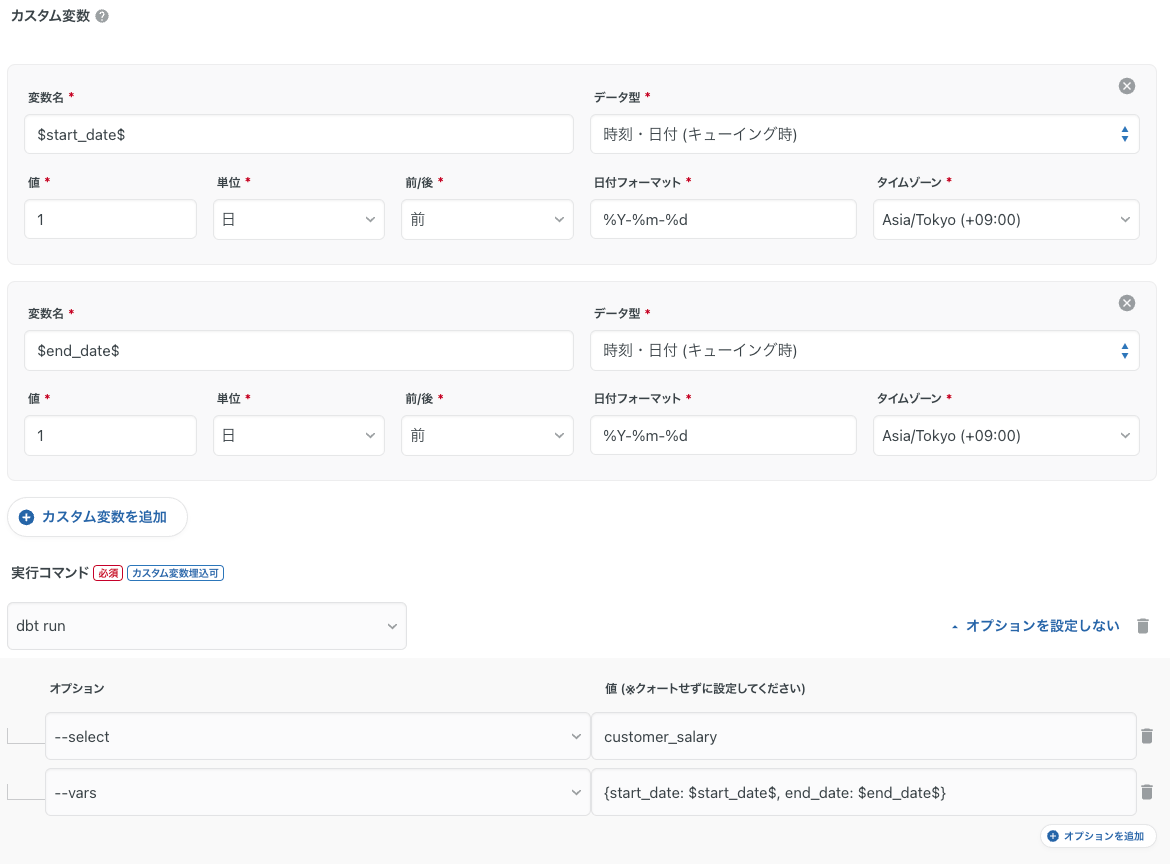
dbt run --select customer_salary --vars '{"start_date": "$start_date$", "end_date": "$end_date$"}'
実行ログ
running... dbt run --select customer_salary --vars \{start_date:\ 2024-11-06,\ end_date:\ 2024-11-06\}
[参考情報]変数の参照優先順位
- コマンドラインで指定された
--vars -
dbt_project.ymlに指定されたスコープド変数 -
dbt_project.ymlに指定されたグローバル変数 -
vars()関数の第2引数に指定されたデフォルト値
vars()関数で参照した変数が見つからなかった場合は、dbt run実行時にコンパイルエラーとなります。
↓ 実行結果 ↓
customer_salary テーブル(ターゲットテーブル)
前日データが追加された。
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
| 佐々木裕 | 28 | 2024-11-06 15:40:00.000000 UTC |
| 小林健 | 35 | 2024-11-06 17:25:00.000000 UTC |
3. ソースデータのデータ欠損が修正された状態
- 検証目的 : データ欠損が修正された場合に、正しいデータがターゲットテーブルに反映されることを確認します。
-
検証目的 : データ欠損が修正された場合に、正しいデータがターゲットテーブルに反映されることを確認します。サンプルデータを再作成して、データの欠損が修正された状態を再現する
- データの欠損日:2024-11-02、2024-11-03
- 期待される結果 : 修正後の正しいデータがターゲットテーブルに反映されること。
CREATE OR REPLACE TABLE `work.customer` (
name STRING
, age INT64
, created_at TIMESTAMP
) AS (
SELECT *
FROM UNNEST (
ARRAY<STRUCT<
name STRING
, age INT64
, created_at TIMESTAMP
>> [
('田中太郎', 45, '2024-11-01 10:00:00')
, ('佐藤花子', 25, '2024-11-01 14:30:00')
, ('鈴木一郎', 30, '2024-11-02 09:15:00')
, ('山田優子', null, '2024-11-02 18:20:00')
, ('伊藤健太', 32, '2024-11-03 12:45:00')
, ('高橋美紀', 27, '2024-11-04 07:25:00')
, ('渡辺陽一', null, '2024-11-04 16:50:00')
, ('加藤隆', 22, '2024-11-05 10:05:00')
, ('小林健', 35, '2024-11-06 17:25:00')
, ('佐々木裕', 28, '2024-11-06 15:40:00')
]
)
)
customer テーブル(ソースデータ)
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 山田優子 | 2024-11-02 18:20:00.000000 UTC | |
| 伊藤健太 | 32 | 2024-11-03 12:45:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
| 佐々木裕 | 28 | 2024-11-06 15:40:00.000000 UTC |
| 小林健 | 35 | 2024-11-06 17:25:00.000000 UTC |
dbtジョブ設定(TROCCO)
データの欠損している期間をbackfill(埋め戻し)処理

dbt run --select customer_salary --vars '{"start_date": "2024-11-02", "end_date": "2024-11-03"}'
実行ログ
running... dbt run --select customer_salary --vars \{start_date:\ 2024-11-02,\ end_date:\ 2024-11-03\}
↓ 実行結果 ↓
customer_salary テーブル(ターゲットテーブル)
修正後の埋め戻しデータがターゲットテーブルに反映された。
| name | age | created_at |
|---|---|---|
| 田中太郎 | 45 | 2024-11-01 10:00:00.000000 UTC |
| 佐藤花子 | 25 | 2024-11-01 14:30:00.000000 UTC |
| 鈴木一郎 | 30 | 2024-11-02 09:15:00.000000 UTC |
| 山田優子 | 2024-11-02 18:20:00.000000 UTC | |
| 伊藤健太 | 32 | 2024-11-03 12:45:00.000000 UTC |
| 高橋美紀 | 27 | 2024-11-04 07:25:00.000000 UTC |
| 渡辺陽一 | 2024-11-04 16:50:00.000000 UTC | |
| 加藤隆 | 22 | 2024-11-05 10:05:00.000000 UTC |
| 佐々木裕 | 28 | 2024-11-06 15:40:00.000000 UTC |
| 小林健 | 35 | 2024-11-06 17:25:00.000000 UTC |
設定不良パターン
start_dateもしくはend_dateの未指定だった場合
エラー:Could not cast literal "None" to type DATE
WHERE DATE(created_at) BETWEEN 'None' AND 'None'
おわりに
TROCCOのカスタム変数を活用することで、dbtでの増分更新の設定が簡単になります。この仕組みを導入することで、データ処理の効率化やコスト削減を実現できます。興味があれば、TROCCOのカスタム変数の活用方法やdbtの応用例についてさらに探求してみてください!
参考
Discussion