BigQuery テーブル比較で使っているクエリ集
この記事はBigQuery Advent Calendar 2024 2日目の記事です。
はじめに
BigQuery テーブル比較でよく使っているクエリをまとめました。
ハッシュ値によるテーブルの一致判定をしています。
サンプルテーブル
まずは、比較用にサンプルテーブルを2つ用意します。数値を変えて挙動確認が出来ます。
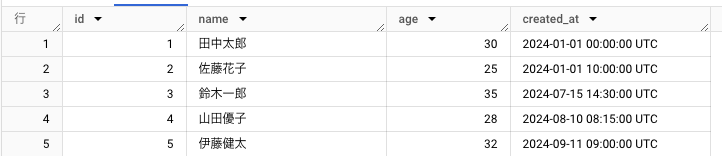
サンプルテーブル①
`プロジェクトID.データセットID.test_01`
CREATE OR REPLACE TABLE `プロジェクトID.データセットID.test_01`
PARTITION BY DATE(created_at)
CLUSTER BY age, name
OPTIONS (
description = "サンプルのユーザーデータ"
) AS (
SELECT 1 AS id, '田中太郎' AS name, 30 AS age, TIMESTAMP('2024-01-01 00:00:00') AS created_at
UNION ALL SELECT 2, '佐藤花子', 25, TIMESTAMP('2024-01-01 10:00:00')
UNION ALL SELECT 3, '鈴木一郎', 35, TIMESTAMP('2024-07-15 14:30:00')
UNION ALL SELECT 4, '山田優子', 28, TIMESTAMP('2024-08-10 08:15:00')
UNION ALL SELECT 5, '伊藤健太', 32, TIMESTAMP('2024-09-11 09:00:00')
);
-- id カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_01`
ALTER COLUMN id
SET OPTIONS (description = "ユーザーの一意の識別子");
-- name カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_01`
ALTER COLUMN name
SET OPTIONS (description = "ユーザーの氏名");
-- age カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_01`
ALTER COLUMN age
SET OPTIONS (description = "ユーザーの年齢");
-- created_at カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_01`
ALTER COLUMN created_at
SET OPTIONS (description = "レコードの作成日時");
サンプルテーブル②
`プロジェクトID.データセットID.test_02`
CREATE OR REPLACE TABLE `プロジェクトID.データセットID.test_02`
PARTITION BY DATE(created_at)
CLUSTER BY age, name
OPTIONS (
description = "サンプルのユーザーデータ"
) AS (
SELECT 1 AS id, '田中太郎' AS name, 30 AS age, TIMESTAMP('2024-01-01 00:00:00') AS created_at
UNION ALL SELECT 2, '佐藤花子', 25, TIMESTAMP('2024-01-01 10:00:00')
UNION ALL SELECT 3, '鈴木一郎', 35, TIMESTAMP('2024-07-15 14:30:00')
UNION ALL SELECT 4, '山田優子', 28, TIMESTAMP('2024-08-10 08:15:00')
UNION ALL SELECT 5, '伊藤健太', 32, TIMESTAMP('2024-09-11 09:00:00')
);
-- id カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_02`
ALTER COLUMN id
SET OPTIONS (description = "ユーザーの一意の識別子");
-- name カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_02`
ALTER COLUMN name
SET OPTIONS (description = "ユーザーの氏名");
-- age カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_02`
ALTER COLUMN age
SET OPTIONS (description = "ユーザーの年齢");
-- created_at カラムの説明追加
ALTER TABLE `プロジェクトID.データセットID.test_02`
ALTER COLUMN created_at
SET OPTIONS (description = "レコードの作成日時");

一致しているかどうかを確認する(ハッシュ値によるテーブルの一致判定)
テーブルの内容が完全に一致している場合、are_tables_identical は TRUE を返し、違いがあれば FALSE を返します。
WITH new_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_01`
)
,old_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_02`
)
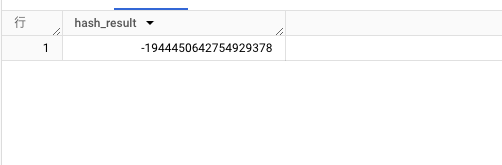
SELECT COUNT(DISTINCT hash_result) = 1 AS are_tables_identical
FROM (
SELECT BIT_XOR(FARM_FINGERPRINT(TO_JSON_STRING(new_table))) AS hash_result
FROM new_table
UNION ALL
SELECT BIT_XOR(FARM_FINGERPRINT(TO_JSON_STRING(old_table))) AS hash_result
FROM old_table
) AS hashes
このクエリは、new_table と old_table が同一であるかどうかを判定するために、それぞれのテーブルから JSON 文字列を生成し、FARM_FINGERPRINT 関数を使用してハッシュ値を作成し、BIT_XOR 関数でハッシュ値を集計することで比較しています。
クエリの説明
-
new_tableとold_tableの作成-
new_tableとold_tableにtest_01とtest_02の内容を格納しています。
-
WITH new_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_01`
)
,old_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_02`
)
-
TO_JSON_STRING関数- 各テーブルの行を JSON 形式の文字列に変換します。
SELECT TO_JSON_STRING(new_table) AS hash_result
FROM new_table

3. FARM_FINGERPRINT 関数
- JSON 文字列からハッシュ値を生成します。
SELECT FARM_FINGERPRINT(TO_JSON_STRING(new_table)) AS hash_result
FROM new_table

4. BIT_XOR 関数
- 各テーブルの全ての行のハッシュ値を集計して単一のハッシュ値を生成します。
SELECT BIT_XOR(FARM_FINGERPRINT(TO_JSON_STRING(new_table))) AS hash_result
FROM new_table
5. 結果の比較
- それぞれの集計ハッシュ値を比較し、
COUNT(DISTINCT hash_result) = 1でテーブルの内容が同一かどうかを判定します。もし一致すればTRUEを返します。
注意点
- テーブルの内容が異なる場合は
FALSEが返されます。 - テーブルの行順や列順が異なっていても、このクエリはデータの内容そのものを比較しているため、順序の影響を受けません。
結果
テーブルの内容が完全に一致している場合、are_tables_identical は TRUE

一致していない場合、are_tables_identical は FALSE

参考
dbt-audit-helperでquick_are_relations_identicalを使用したときにBigQueryに投げられるクエリを参考。
他にも、日常使い出来そうなクエリがあるので要チェックです!
一致していないレコードを確認する
このクエリを実行すると、以下の2つの結果が得られます:
-
new_tableからold_tableに存在しない行:-
new_tableに存在し、old_tableに存在しない行が抽出され、source_tableカラムには'new_table'が表示されます。
-
-
old_tableからnew_tableに存在しない行:-
old_tableに存在し、new_tableに存在しない行が抽出され、source_tableカラムには'old_table'が表示されます。
-
-
テーブル一致している場合
- テーブル一致している場合は「表示するデータはありません。」と表示される
WITH new_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_01`
),
old_table AS (
SELECT * FROM `プロジェクトID.データセットID.test_02`
)
SELECT 'new_table' AS source_table,*
FROM (SELECT * FROM new_table EXCEPT DISTINCT SELECT * FROM old_table)
UNION ALL
SELECT 'old_table' AS source_table,*
FROM (SELECT * FROM old_table EXCEPT DISTINCT SELECT * FROM new_table)
結果
テーブル一致している場合は「表示するデータはありません。」と表示

一致していない場合は差分を表示

テーブル情報を比較
INFORMATION_SCHEMA.TABLESを並べただけ
SELECT 'new_table' AS source_table,*
FROM `プロジェクトID.データセットID.INFORMATION_SCHEMA.TABLES`
WHERE table_name = 'test_01'
UNION ALL
SELECT 'old_table' AS source_table,*
FROM `プロジェクトID.データセットID.INFORMATION_SCHEMA.TABLES`
WHERE table_name = 'test_02'
結果

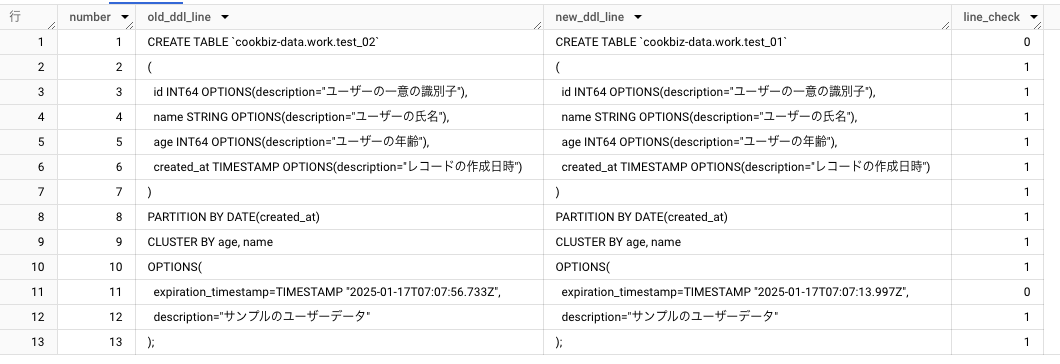
DDL(データ定義言語)の比較
このクエリは、2つのテーブル (test_02 と test_01) のDDL(データ定義言語)を行ごとに比較し、各行が一致しているかどうかを確認します。
WITH old_table_lines AS (
SELECT
line AS old_line,
ROW_NUMBER() OVER () AS line_number
FROM `プロジェクトID.データセットID.INFORMATION_SCHEMA.TABLES` AS old_table,
UNNEST(SPLIT(old_table.ddl, '\n')) AS line
WHERE old_table.table_name = 'test_02'
),
new_table_lines AS (
SELECT
line AS new_line,
ROW_NUMBER() OVER () AS line_number
FROM `プロジェクトID.データセットID.INFORMATION_SCHEMA.TABLES` AS new_table,
UNNEST(SPLIT(new_table.ddl, '\n')) AS line
WHERE new_table.table_name = 'test_01'
)
SELECT
old_table_lines.line_number AS number
,old_table_lines.old_line AS old_ddl_line
,new_table_lines.new_line AS new_ddl_line
,IF(old_table_lines.old_line = new_table_lines.new_line, 1, 0) AS line_check
FROM old_table_lines
FULL OUTER JOIN new_table_lines
ON old_table_lines.line_number = new_table_lines.line_number
ORDER BY number;
結果
比較結果
おわりに
一致しているかどうかを確認する→一致していないレコードを確認するのクエリは頻繁に使っています。使いたい時にどこにメモったか忘れるので記事化しました。参考までに、、、
2024/12/05追記
こういうアドバイスありがたい!
参考
Discussion