dbt docs の custom overview を触ってみた
はじめに
社内で dbt docs を公開している場合、利用者にとってわかりやすい説明や関連リンクをテキスト領域に追加することで、ドキュメントの理解を促進できます。特に以下の2つの領域を活用することで、ドキュメント全体をより見やすく、親しみやすくすることが可能です
- Custom overview(トップページ)
- Custom project-level overview(プロジェクトフォルダをクリックしたときに表示されるページ)
しかし、各モデルのディスクリプション(description)に関する情報は多くある一方で、Custom overview に関する記事はあまり多くありません。
そこで本記事では、Custom overview や Custom project-level overview の編集で、社内向け dbt docs をより充実させるためのメモを共有します。(どちらかというとつまずきポイントの共有がメインです)
Custom overview
これは、dbt docs を開いた時にトップページに表示れてる文章です。
models/overview.mdに下記のように記載することで内容を編集できます。
{% docs __overview__ %}
# Monthly Recurring Revenue (MRR) playbook.
This dbt project is a worked example to demonstrate how to model subscription
revenue. **Check out the full write-up [here](https://blog.getdbt.com/modeling-subscription-revenue/),
as well as the repo for this project [here](https://github.com/dbt-labs/mrr-playbook/).**
...
{% enddocs %}
ここには、社内リンクなどを整備して、wiki的な利用もありだと思います。
- 現状は素朴にデフォルトのトップページテキストを日本語訳して載せていますが、今後の内容の拡充をしていきたいです。
overview.md
{% docs __overview__ %}
### Welcome!
dbtプロジェクトの自動生成ドキュメントへようこそ!
### Navigation
ウィンドウの左側にあるプロジェクトとデータベースのナビゲーションタブを使って、プロジェクト内のモデルを調べることができます。
#### Project Tab
プロジェクトタブはdbtプロジェクトのディレクトリ構造を反映しています。このタブでは、dbtプロジェクトで定義されたすべてのモデル、およびdbtパッケージからインポートされたモデルを見ることができます。
#### Database Tab
データベースタブにもモデルが表示されますが、よりデータベースエクスプローラーに近い形式で 表示されます。このビューには、データベーススキーマにグループ化されたリレーション(テーブルとビュー)が表示されます。エフェメラルモデルはデータベースに存在しないため、このインターフェースには表示されないことに注意してください。
### グラフ探索
ページの右下にある青いアイコンをクリックすると、モデルの系統グラフを見ることができます。
モデルのページでは、探索中のモデルの直接の親と子が表示されます。この血統ペインの右上にある「展開」ボタンをクリックすると、現在調べているモデルを構築するために使用された、あるいは構築されたすべてのモデルを見ることができます。
一度展開されると、`--select` や `--exclude` のモデル選択構文を使って、グラフ内のモデルをフィルタリングすることができるようになります。モデル選択の詳細については、dbtの[ドキュメント](https://docs.getdbt.com/reference/node-selection/syntax)を参照してください。
また、モデルを右クリックすることで、グラフをインタラクティブにフィルタリングしたり、探索したりすることもできます。
------
### More information
- [What is dbt](https://docs.getdbt.com/docs/introduction)?
- Read the [dbt viewpoint](https://docs.getdbt.com/docs/viewpoint)
- [Installation](https://docs.getdbt.com/docs/installation)
- Join the [dbt Community](https://www.getdbt.com/community/) for questions and discussion
{% enddocs %}

- 他社事例だと、ER図を載せることも
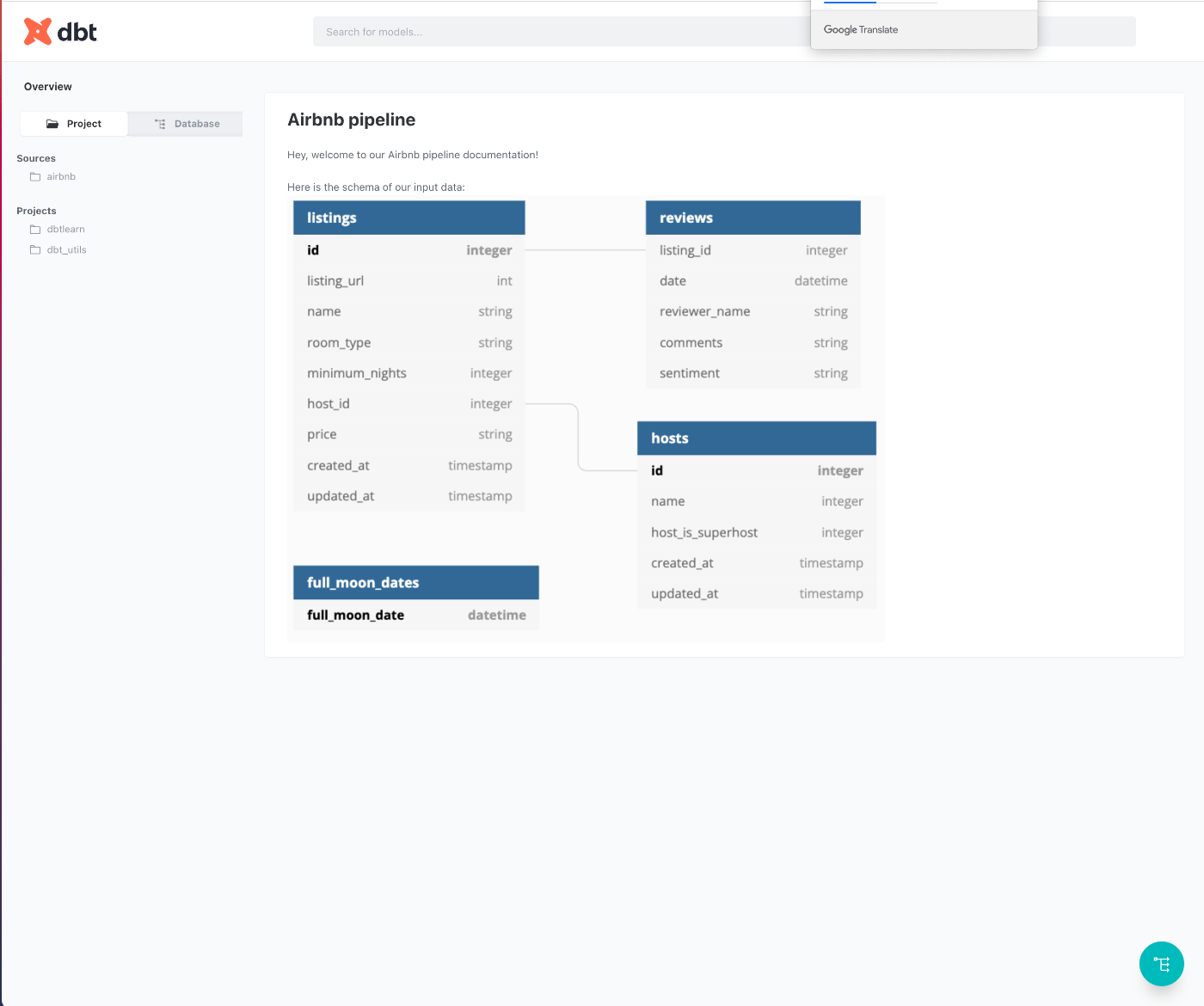
Custom project-level overview
Custom project-level overview はプロジェクトフォルダをクリックしたときに表示されるページです。下記のサイドバーには、自身のdbt プロジェクトの他に、dbt depsでインストールされるパッケージがリストで表示されます。

dbt プロジェクト
dbt プロジェクトのマークダウンでは、各モデルごとに BigQuery テーブルへのリンクや、dbt Docs 上のモデル定義へのリンクを一覧化しています。
これにより、dbt Docs から直接 BigQuery にアクセスしたり、モデルのディスクリプションを確認して内容を把握することができます。

dbt プロジェクトのマークダウン作成スクリプト
import json
import pandas as pd
from dbt.cli.main import dbtRunner, dbtRunnerResult
from typing import Optional
# cd dbt_project/ && dbt docs generate && dbt docs serve
# 定数
DBT_DOCS_PATH = "#!/{resource_type}/{unique_id}"
BQ_TABLE_PATH = "[■](https://console.cloud.google.com/bigquery?p={project_id}&d={dataset_id}&t={table_id}&page=table)"
BQ_DATASET_PATH = "[{schema}](https://console.cloud.google.com/bigquery?p={project_id}&d={dataset_id}&page=dataset)"
def run_dbt_command(cli_args: list) -> dbtRunnerResult:
"""dbtコマンドを実行し、結果を返す"""
dbt = dbtRunner()
res: dbtRunnerResult = dbt.invoke(cli_args)
if not res.success:
raise RuntimeError(f"dbt command execution failed: {res.exception}")
if not res.result:
print("Execution result is empty")
return None
return res
def list_models_as_df(
select: str = "dbt_project",
project_dir: str = "./dbt_project",
profiles_dir: Optional[str] = None,
target: Optional[str] = None,
) -> pd.DataFrame:
"""dbtのモデル一覧をDataFrameで取得"""
cli_args = [
"ls",
"--select",
select,
"--resource-type",
"model",
"--output",
"json",
"--output-keys",
"package_name",
"name",
"database",
"schema",
"alias",
"resource_type",
"unique_id",
"description",
]
if project_dir:
cli_args.extend(["--project-dir", project_dir])
if profiles_dir:
cli_args.extend(["--profiles-dir", profiles_dir])
if target:
cli_args.extend(["--target", target])
res = run_dbt_command(cli_args)
if not res or not res.result:
return pd.DataFrame()
rows = [json.loads(line) for line in res.result]
return pd.DataFrame(rows)
def process_model_info(df: pd.DataFrame) -> pd.DataFrame:
"""dbtモデル情報のDataFrameを加工"""
df["schema_name"] = df.apply(
lambda row: BQ_DATASET_PATH.format(schema=row["schema"], project_id=row["database"], dataset_id=row["schema"]),
axis=1,
)
df["DB"] = df.apply(
lambda row: BQ_TABLE_PATH.format(project_id=row["database"], dataset_id=row["schema"], table_id=row["alias"]),
axis=1,
)
df["model_name"] = df.apply(
lambda row: f'[{row["name"]}]({DBT_DOCS_PATH.format(resource_type=row["resource_type"], unique_id=row["unique_id"])})',
axis=1,
)
df["description"] = df["description"].str.replace("\n", "、").str.strip("、")
df = df[["package_name", "unique_id", "schema_name", "DB", "model_name", "description"]]
df = df.sort_values(["package_name", "unique_id"])
return df
def export_markdown_by_package(df: pd.DataFrame, output_dir: str = "./dbt_project/models"):
"""パッケージごとにMarkdownファイルを出力"""
grouped = df.groupby("package_name")
for package_name, group in grouped:
filename = f"{output_dir}/{package_name}.md"
group = group.drop(columns=["unique_id", "package_name"])
header_text = f"{{% docs __{package_name}__ %}}\n# {package_name}\n"
footer_text = "\n\n{% enddocs %}"
markdown_sections = []
for schema, schema_group in group.groupby("schema_name"):
schema_group = schema_group.drop(columns=["schema_name"])
markdown_table = schema_group.to_markdown(index=False)
markdown_sections.append(f"## {schema}\n\n{markdown_table}")
markdown_output = "\n\n".join(markdown_sections)
with open(filename, "w", encoding="utf-8") as md_file:
md_file.write(header_text)
md_file.write(markdown_output)
md_file.write(footer_text)
print(f"Created {filename}")
if __name__ == "__main__":
df = list_models_as_df()
if not df.empty:
df_processed = process_model_info(df)
export_markdown_by_package(df_processed)
else:
print("No models found.")
dbt パッケージ
一方で、各パッケージについては、それぞれのパッケージに含まれる README.md の内容を取得・転記することで、dbt docs 上から各パッケージの概要を把握できるようにしています。
転記スクリプト
import os
from pathlib import Path
# 対象パス
packages_path = Path("dbt_project/dbt_packages")
output_path = Path("dbt_project/models")
# dbt_packages内のディレクトリ一覧を取得
folder_list = [name for name in os.listdir(packages_path) if os.path.isdir(packages_path / name)]
for folder in folder_list:
src = packages_path / folder / "README.md"
if not src.exists():
print(f"⚠️ README.md が見つかりません: {src}")
continue
dst = output_path / f"{folder}.md"
# ファイル読み込み
with src.open("r", encoding="utf-8") as f:
content = f.read()
# docs タグでラップ
wrapped_content = f"{{% docs __{folder}__ %}}\n{{% raw %}}\n" + content.strip() + "\n{% endraw %}\n{% enddocs %}\n"
# 出力先ディレクトリがなければ作成
dst.parent.mkdir(parents=True, exist_ok=True)
# ファイル書き出し
with dst.open("w", encoding="utf-8") as f:
f.write(wrapped_content)
print(f"✅ 変換完了: {dst}")

つまずきポイント
overview.md のファイル配置について
dbt_project.yml に以下の設定がある場合
docs-paths: ["docs"]
この場合、docs ブロック(例: __overview__)を含む .md ファイルは models/ フォルダではなく、docs/ フォルダ内に配置する必要があります。
ただし注意点として
-
docs-pathsを設定すると、指定したフォルダ以外の.mdファイルは無視される or エラーになる。 -
docsブロックは通常、モデル定義(.yml)の中に埋め込む形で使われることが多いため、.ymlと.mdの距離が離れると管理が煩雑になります。 - よって、特別な理由がなければ
docs-pathsの設定はしない方が無難な気がします。
overview.md のファイル分割について
前述のとおり、__overview__ や __<project_name>__ という docs ブロックは、1つのファイル内(例: overview.md)にまとめても良いですが、同じフォルダにあれば別ファイルに分割してもOK です。
{% docs __overview__ %}
# Monthly Recurring Revenue (MRR) playbook.
...
{% enddocs %}
{% docs __dbt_utils__ %}
# ユーティリティマクロ
...
{% enddocs %}
例えば、models/ フォルダ内に以下のようにファイルを分けて管理することができます
models/overview.md
{% docs __overview__ %}
# Monthly Recurring Revenue (MRR) playbook.
...
{% enddocs %}
models/dbt_utils.md
{% docs __dbt_utils__ %}
# ユーティリティマクロ
...
{% enddocs %}
dbt docs の markdown ではHTMLタグを許可していない問題💢
Issueで何度もの挙がっているがセキュリティリスク?かなんか分かりませんがHTMLタグの使用が許可されたません。
問題のコード(おそらくここ)
sanitize: trueなので<br>が使えない問題あり
これにより、HTMLタグ(例:<br>)は無視またはエスケープされ、レンダリングされません。
下記の表がそのまま表示されてしまう。これではmarkdownの表現力が半減です。
| 名前 | 説明 |
|-------|------|
| 太郎 | これは表のセル内で<br>改行をする例です |
| 花子 | 2行目も<br>改行できます |
これは、諦めるしかないです
テキスト内に jinja SQL がある場合エラーになります
下記のようにテキスト内に jinja SQL がある場合はdbt compile時にエラーになってしまいます
その場合、エスケープする必要があり、特定の範囲をまとめてエスケープしたい場合は、{% raw %} ブロックを使うことで対応できます。{% raw %} で開始し、{% endraw %} で終了位置を指定します。このブロック内の記述は、そのままの内容で表示されます。
{% docs __overview__ %}
...
### `assert_true`
Test that expr is true.
**Usage:**
```sql
{{ dbt_unittest.assert_true(true) }}
{{ dbt_unittest.assert_true(1 == 1) }}
```
...
{% enddocs %}
- コードブロックのみをエスケープ(GitLab Data Teamはこれでした)
{% docs __overview__ %}
...
### `assert_true`
Test that expr is true.
**Usage:**
```sql
{% raw %}
{{ dbt_unittest.assert_true(true) }}
{{ dbt_unittest.assert_true(1 == 1) }}
{% endraw %}
```
...
{% enddocs %}
- テキスト全体をエスケープ(自分的にはこっちが楽かな)
{% docs __overview__ %}
{% raw %}
...
### `assert_true`
Test that expr is true.
**Usage:**
```sql
{% raw %}
{{ dbt_unittest.assert_true(true) }}
{{ dbt_unittest.assert_true(1 == 1) }}
{% endraw %}
```
...
{% endraw %}
{% enddocs %}
おわりに
まだまだ改善の余地はありますが、小さな工夫を積み重ねることで、利用者にとって価値あるドキュメントに育てていければと思っています。今後も dbt docs のアップデートや、他社の事例を参考にしながら、より良い形を模索していきたいです。
参考
Discussion