爆誕‼️爆速ClaudeCode‼️
Claude Code で Cerebras の Qwen-3-Coder-480B を動かし爆速開発する方法。(Docker不要・プロジェクト設定不要・サブエージェント対応)
最短ゴール
-
cc→ 公式 Claude Code をそのまま -
ccq→ LiteLLM 経由で Cerebras / Qwen-3-Coder-480B を使用 - サブエージェント(Task ツール)まで確実に動作
- 実戦ノウハウ:OpenAI SDK のピン留め / system配列の安全な正規化 /
NO_PROXY明示
TL;DR
-
Claude Code は Anthropic Messages API(
/v1/messages)で話す -
LiteLLM Proxy に Unified
/v1/messagesで投げ、**Cerebras(OpenAI互換)**にブリッジ -
必須ポイント 3つ
- OpenAI SDK を 1.99.x に固定(互換問題回避)
-
プリコールフックでテキストだけ文字列化し、
tool_use/tool_resultなどは保持 -
起動時に
--drop_paramsは使わない(ツール定義が落ちないように)
-
推奨:ローカル接続は
NO_PROXY=127.0.0.1,localhostを明示 -
小型/高速モデルも同じ論理名へ固定(
ANTHROPIC_SMALL_FAST_MODEL)
なぜ「Qwen on Cerebras」か?
品質
最新の比較やベンダー検証では、Claude Sonnet と Qwen-3-Coder-480B のコーディング力は近接〜競合という報告が増えています(SWE-bench でも「Sonnet 4 に匹敵」との記述あり)。(Together AI)
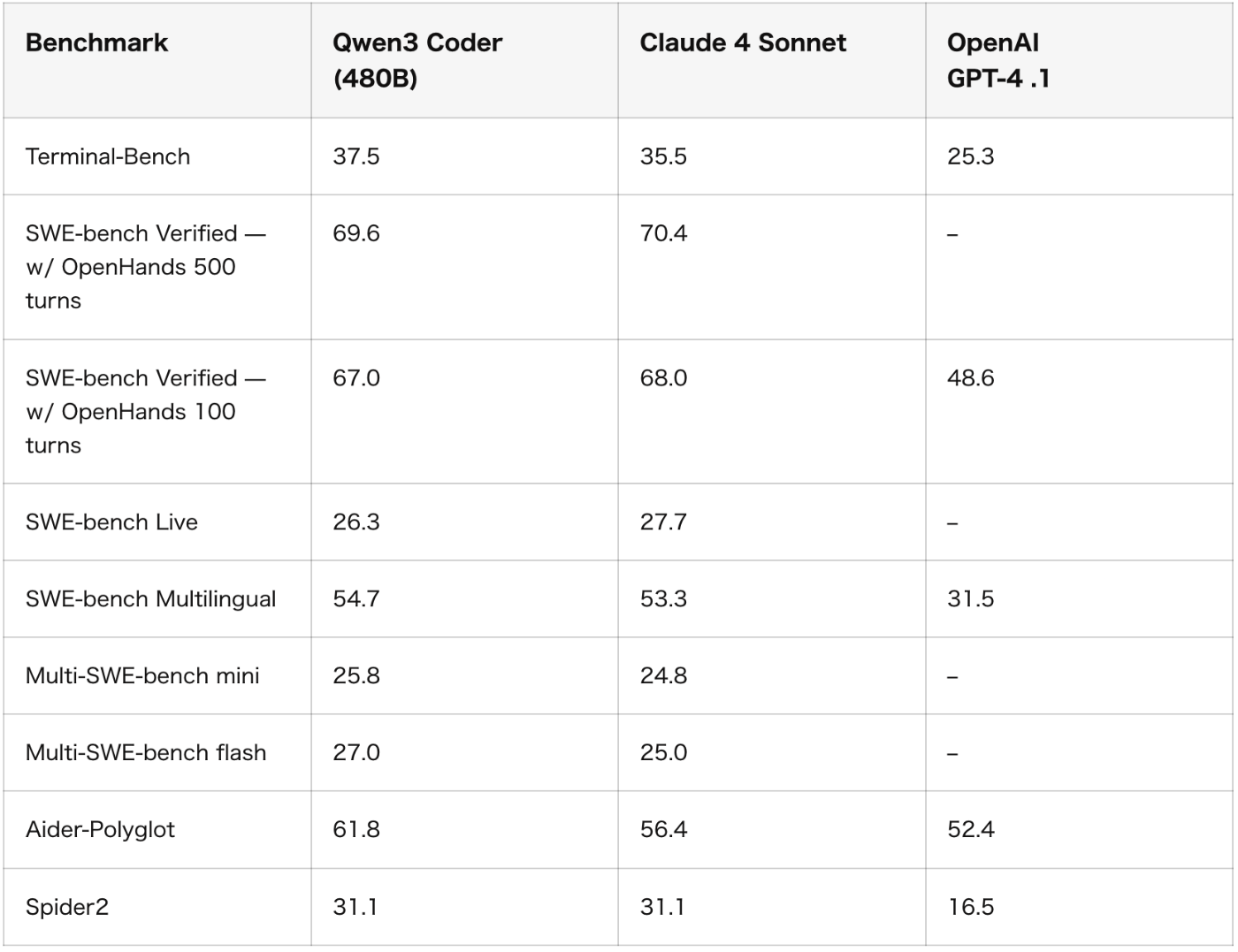

図参考:(Qwen3 Coder 完全ガイド:Claude 4・GPT-4.1 に並ぶ最強のコーディング特化AIより)
速度
Cerebras 版 Qwen-3-Coder-480B は ~2,000 tok/secを公称。外部報道でも 1,000 words/sec 級の実績が取り上げられ、現行最速クラスの選択肢です。(Cerebras, Reuters)
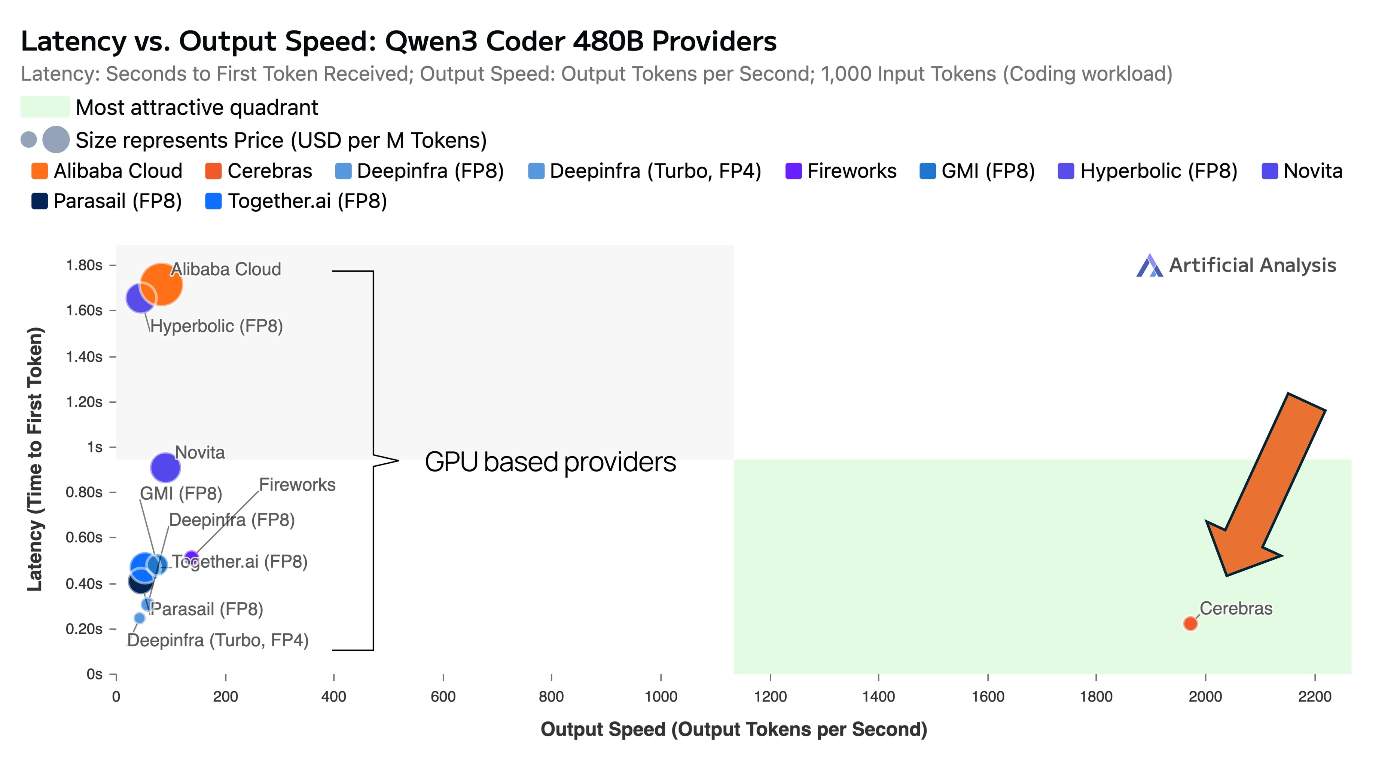
図参考:(x:Andrew Feldmanさんのポストより)
課題と目的
QwenCoder(Qwen Code CLI)では、サブエージェントがなくタスク分割が行えないため、開発精度にClaudeCodeに大きな差がある。
爆速で生成が行え、定額プランのあるCerebrasのQwen-3-Coder-480BをClaudeCode内で使用できれば、通常のClaudeCodeと同程度の精度で爆速開発ができるのでは?と考え実際に動かすことができたので設定方法を共有します。
0. 前提
- Node.js 18+
- macOS(zsh)/Windows(PowerShell)
- Cerebras の API キー取得済み
- シェルから
claudeコマンドが使用可能(@anthropic-ai/claude-code)
1. Claude Code を入れる
# macOS / Windows 共通(npmグローバル)
npm install -g @anthropic-ai/claude-code
2. LiteLLM を pipx で隔離インストール(安定版)
macOS
brew install pipx
pipx ensurepath
pipx install "litellm[proxy]==1.74.0.post2"
Windows(PowerShell)
py -m pip install --user pipx
py -m pipx ensurepath
# 新しいターミナルを開く
pipx install "litellm[proxy]==1.74.0.post2"
注:この版は Unified
/v1/messages周りが安定。
3. OpenAI SDK を 1.99.x に固定(互換性バグ回避)
LiteLLM の pipx 仮想環境内の openai を固定します。
pipx runpip litellm install "openai>=1.99.1,<1.100.0"
pipx runpip litellm show openai # ← Version: 1.99.x であること
4. Cerebras キー & LiteLLM 設定
4-1. キー保存
macOS:
mkdir -p ~/.secrets ~/.config/litellm
read -s -p "Cerebras API Key: " CERE_KEY; echo
printf "%s" "$CERE_KEY" > ~/.secrets/cerebras_api_key && chmod 600 ~/.secrets/cerebras_api_key
Windows(PowerShell):
New-Item -ItemType Directory -Force $HOME\.secrets | Out-Null
$CereKey = Read-Host -AsSecureString "Cerebras API Key"
$Plain = [Runtime.InteropServices.Marshal]::PtrToStringAuto(
[Runtime.InteropServices.Marshal]::SecureStringToBSTR($CereKey)
)
Set-Content -Path "$HOME\.secrets\cerebras_api_key" -Value $Plain -NoNewline
icacls "$HOME\.secrets\cerebras_api_key" /inheritance:r /grant:r "$env:USERNAME:F" | Out-Null
4-2. ~/.config/litellm/config.yaml
model_list:
- model_name: qwen-3-coder-480b # ← Claude Code から見える論理名
litellm_params:
model: cerebras/qwen-3-coder-480b
api_base: https://api.cerebras.ai/v1
api_key: os.environ/CEREBRAS_API_KEY
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance
5. プリコールフック(全文):テキストだけ安全に文字列化
目的:
- top-level
systemが配列でも文字列化- メッセージの
contentは text-only のときのみ文字列化tool_use/tool_resultなど非textブロックは配列のまま保持(サブエージェント起動に必要)
~/.config/litellm/custom_callbacks.py を作成:
# ~/.config/litellm/custom_callbacks.py
from litellm.integrations.custom_logger import CustomLogger
from typing import Any, Dict, List, Literal, Union
ContentBlock = Dict[str, Any]
Message = Dict[str, Any]
TEXT_TYPES = {"text"}
def _stringify_text_blocks(blocks: List[ContentBlock]) -> Union[str, List[ContentBlock]]:
"""
contentブロック配列が「textのみ」のときだけ文字列へ畳み込む。
1つでもtext以外が混じっていたら配列のまま返す。
"""
if not isinstance(blocks, list):
return blocks
for b in blocks:
if not isinstance(b, dict) or b.get("type") not in TEXT_TYPES:
return blocks
return "\n".join(str(b.get("text", "")) for b in blocks if isinstance(b, dict))
def _normalize_message_content(m: Message) -> Message:
"""
- content が str: そのまま
- content が list: text-onlyなら文字列化/非text混在なら配列のまま
- content が dict: そのまま(壊さない)
- それ以外: str 化
"""
if "content" not in m:
return m
c = m["content"]
if isinstance(c, str):
return m
if isinstance(c, list):
m["content"] = _stringify_text_blocks(c)
return m
if isinstance(c, dict):
return m
m["content"] = str(c)
return m
def _system_to_string(system_val: Any) -> str:
"""
top-level system を文字列に正規化(配列ならtextのjoin)。
"""
if isinstance(system_val, str):
return system_val
if isinstance(system_val, list):
out = []
for b in system_val:
if isinstance(b, dict):
if b.get("type") == "text":
out.append(str(b.get("text", "")))
elif "text" in b:
out.append(str(b["text"]))
return "\n".join(s for s in out if s)
if isinstance(system_val, dict) and "text" in system_val:
return str(system_val.get("text", ""))
return str(system_val)
class SafeAnthropicNormalizer(CustomLogger):
async def async_pre_call_hook(
self,
user_api_key_dict,
cache,
data: dict,
call_type: Literal[
"completion","text_completion","embeddings","image_generation","moderation","audio_transcription"
],
):
# 1) ほんとうに不要なメタだけ除去(tools 等は絶対に消さない)
for k in ("litellm_settings", "reasoning", "thinking", "guided_choice"):
data.pop(k, None)
# 2) top-level system を文字列に
if "system" in data:
data["system"] = _system_to_string(data["system"])
# 3) messages の content を安全に正規化
msgs = data.get("messages")
if isinstance(msgs, list):
new_msgs = []
for m in msgs:
if not isinstance(m, dict):
continue
m = dict(m)
if "role" not in m:
m["role"] = "user"
m = _normalize_message_content(m)
new_msgs.append(m)
data["messages"] = new_msgs
# 4) tools / tool_choice はそのまま通す(ここでは触らない)
return data
proxy_handler_instance = SafeAnthropicNormalizer()
6. LiteLLM を起動(--drop_params なし)
export LITELLM_MASTER_KEY="sk-local"
export CEREBRAS_API_KEY="$(cat ~/.secrets/cerebras_api_key)"
# --drop_params は付けない(ツール定義が落ちないように)
litellm --config ~/.config/litellm/config.yaml --port 4000
7. cc / ccq の2コマンド切替(小型/高速モデルの宛先も固定)
macOS(zsh)
# ~/.zshrc に追記
cc() { command claude "$@"; }
ccq() {
NO_PROXY="127.0.0.1,localhost" \
ANTHROPIC_BASE_URL="http://127.0.0.1:4000" \
ANTHROPIC_AUTH_TOKEN="sk-local" \
ANTHROPIC_SMALL_FAST_MODEL="qwen-3-coder-480b" \
claude --model qwen-3-coder-480b "$@"
}
# 反映
source ~/.zshrc
Windows(PowerShell)
function cc { param([Parameter(ValueFromRemainingArguments=$true)][string[]]$Args); claude @Args }
function ccq {
param([Parameter(ValueFromRemainingArguments=$true)][string[]]$Args)
$env:NO_PROXY = "127.0.0.1,localhost"
$env:ANTHROPIC_BASE_URL = "http://127.0.0.1:4000"
$env:ANTHROPIC_AUTH_TOKEN = "sk-local"
$env:ANTHROPIC_SMALL_FAST_MODEL = "qwen-3-coder-480b"
claude --model qwen-3-coder-480b @Args
Remove-Item Env:NO_PROXY,Env:ANTHROPIC_BASE_URL,Env:ANTHROPIC_AUTH_TOKEN,Env:ANTHROPIC_SMALL_FAST_MODEL -ErrorAction SilentlyContinue
}
8. 使い方
-
LiteLLM を起動したターミナルを開いたままにする(セクション6)
-
別ターミナルで:
cc # 通常Claude ccq # Qwen(Cerebras 経由) -
任意で:
claude --version claude config list
9. 動作確認
9-1. Unified /v1/messages 疎通
curl -sS http://127.0.0.1:4000/v1/messages \
-H "content-type: application/json" \
-H "Authorization: Bearer sk-local" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model":"qwen-3-coder-480b",
"max_tokens":16,
"system":[{"type":"text","text":"You are a helpful assistant."}],
"messages":[{"role":"user","content":"ping"}]
}'
JSON が返れば OK(system を配列で送ってもフックが安全に正規化)。
9-2. サブエージェント(Task ツール)往復
-
ccqで起動し、/agentsなどを実行 -
claude --verboseで、メイン応答内にtool_use(name: "Task") が現れ、直後のリクエストにtool_resultが含まれていることを確認 - これでサブエージェントが実行され、完了まで流れます
10. よくあるエラーと対処
| 症状 / ログ | 原因 | 対処 |
|---|---|---|
401 Unauthorized |
キー不一致 |
LITELLM_MASTER_KEY="sk-local" と ANTHROPIC_AUTH_TOKEN="sk-local" を一致。Cerebras キーも確認 |
Connection error / fetch failed |
ゲートウェイ未起動 / ポート違い / プロキシが127.0.0.1を奪う | LiteLLM を起動・ポート確認、NO_PROXY=127.0.0.1,localhost を明示 |
ImportError: ResponseTextConfig(起動前に落ちる) |
OpenAI SDK 1.100.0+ と LiteLLM 1.74系の互換問題 | pipx runpip litellm install "openai>=1.99.1,<1.100.0" |
| サブエージェントが始まらない(静かに終わる) |
--drop_params により tools 等が落ちる / tool_use が返らない |
--drop_params を使わない。プリコールフックはtext-onlyだけ文字列化に限定 |
| バックグラウンド呼び出しで即失敗 | 小型/高速モデルの宛先未設定 |
ANTHROPIC_SMALL_FAST_MODEL="qwen-3-coder-480b" を設定 |
model_not_found |
論理名の不一致 |
config.yaml の model_list.model_name と claude --model を一致 |
11. 仕組みの全体像
Claude Code (Anthropic /v1/messages)
│ ANTHROPIC_BASE_URL=http://127.0.0.1:4000
▼
LiteLLM Proxy (Unified /v1/messages)
- custom_callbacks.py で安全な正規化(text-onlyだけ文字列化)
▼
Cerebras (OpenAI互換 API)
- model: cerebras/qwen-3-coder-480b
12. macOS 向け「一気貼り」
既に Node/pipx がある人向け。途中で聞かれたら y で。
# Claude Code
npm install -g @anthropic-ai/claude-code
# LiteLLM(固定版)
brew install pipx
pipx ensurepath
pipx install "litellm[proxy]==1.74.0.post2"
pipx runpip litellm install "openai>=1.99.1,<1.100.0"
# 秘匿キー
mkdir -p ~/.secrets ~/.config/litellm
read -s -p "Cerebras API Key: " CERE_KEY; echo
printf "%s" "$CERE_KEY" > ~/.secrets/cerebras_api_key && chmod 600 ~/.secrets/cerebras_api_key
# LiteLLM 設定
cat > ~/.config/litellm/config.yaml <<'YAML'
model_list:
- model_name: qwen-3-coder-480b
litellm_params:
model: cerebras/qwen-3-coder-480b
api_base: https://api.cerebras.ai/v1
api_key: os.environ/CEREBRAS_API_KEY
litellm_settings:
callbacks: custom_callbacks.proxy_handler_instance
YAML
# プリコールフック(安全版)
cat > ~/.config/litellm/custom_callbacks.py <<'PY'
from litellm.integrations.custom_logger import CustomLogger
from typing import Any, Dict, List, Literal, Union
ContentBlock = Dict[str, Any]
Message = Dict[str, Any]
TEXT_TYPES = {"text"}
def _stringify_text_blocks(blocks: List[ContentBlock]) -> Union[str, List[ContentBlock]]:
if not isinstance(blocks, list):
return blocks
for b in blocks:
if not isinstance(b, dict) or b.get("type") not in TEXT_TYPES:
return blocks
return "\n".join(str(b.get("text", "")) for b in blocks if isinstance(b, dict))
def _normalize_message_content(m: Message) -> Message:
if "content" not in m:
return m
c = m["content"]
if isinstance(c, str):
return m
if isinstance(c, list):
m["content"] = _stringify_text_blocks(c); return m
if isinstance(c, dict):
return m
m["content"] = str(c); return m
def _system_to_string(system_val: Any) -> str:
if isinstance(system_val, str):
return system_val
if isinstance(system_val, list):
out = []
for b in system_val:
if isinstance(b, dict):
if b.get("type") == "text":
out.append(str(b.get("text", "")))
elif "text" in b:
out.append(str(b["text"]))
return "\n".join(s for s in out if s)
if isinstance(system_val, dict) and "text" in system_val:
return str(system_val.get("text", ""))
return str(system_val)
class SafeAnthropicNormalizer(CustomLogger):
async def async_pre_call_hook(
self, user_api_key_dict, cache, data: dict,
call_type: Literal["completion","text_completion","embeddings","image_generation","moderation","audio_transcription"],
):
for k in ("litellm_settings", "reasoning", "thinking", "guided_choice"):
data.pop(k, None)
if "system" in data:
data["system"] = _system_to_string(data["system"])
msgs = data.get("messages")
if isinstance(msgs, list):
new_msgs = []
for m in msgs:
if not isinstance(m, dict): continue
m = dict(m)
if "role" not in m: m["role"] = "user"
m = _normalize_message_content(m)
new_msgs.append(m)
data["messages"] = new_msgs
return data
proxy_handler_instance = SafeAnthropicNormalizer()
PY
# ゲートウェイ起動(--drop_params は付けない)
export LITELLM_MASTER_KEY="sk-local"
export CEREBRAS_API_KEY="$(cat ~/.secrets/cerebras_api_key)"
litellm --config ~/.config/litellm/config.yaml --port 4000
別ターミナルで zsh 関数を追加:
cat >> ~/.zshrc <<'SH'
cc() { command claude "$@"; }
ccq() {
NO_PROXY="127.0.0.1,localhost" \
ANTHROPIC_BASE_URL="http://127.0.0.1:4000" \
ANTHROPIC_AUTH_TOKEN="sk-local" \
ANTHROPIC_SMALL_FAST_MODEL="qwen-3-coder-480b" \
claude --model qwen-3-coder-480b "$@"
}
SH
source ~/.zshrc
テスト:
curl -sS http://127.0.0.1:4000/v1/messages \
-H "content-type: application/json" \
-H "Authorization: Bearer sk-local" \
-H "anthropic-version: 2023-06-01" \
-d '{"model":"qwen-3-coder-480b","max_tokens":8,"system":[{"type":"text","text":"You are a helpful assistant."}],"messages":[{"role":"user","content":"ping"}]}'
cc # 通常Claude
ccq # Qwen(Cerebras)
13. まとめ
- Claude Code を Anthropic Unified
/v1/messagesで LiteLLM に渡し、Cerebras の Qwen へブリッジ -
プリコールフックは “text-only だけ文字列化”。
tool_use/tool_resultは配列のまま保持 -
--drop_paramsは使わない(ツール関連パラメータを温存) - 小型/高速モデルの宛先も 同じ論理名に固定
- これで メイン応答もサブエージェントも 安定して動作します
Discussion