🎥
GPT-4o(omni)を使って動画を解釈させる
1. イントロ
1-1. 本記事の内容
- 2024/05/14にOpenAIからGPT-4 omniなるモデルが発表された
- 動画・テキスト・音声を解釈できるモデルのため、これを用いて動画の実況ができるかを見てみることにした
- ※ 執筆(2024/05/15)時点では、音声解釈のAPI受け口は提供されていない
1-2. GPT-4o について
- クロスモーダルAI
- 入力:動画/画像・テキスト・音声
- 出力:動画/画像・テキスト・音声
- レイテンシの改善
- 20言語におけるトークン数の圧縮
- テキストやオーディオ翻訳の項目において性能改善
2. 実際に使ってみる
- 対象動画はyoutube-8Mデータセットの内容を対象とする
- google colabで実装
- LangChainですでにラップされているようなので、
langchain==0.1.20を利用
2-1. セットアップ
- インストール
! pip install langchain==0.1.20
! pip install yt-dlp youtube-dl
! pip install langchain_openai
必要なモジュールインポート+APIキー設定
import os
from google.colab import userdata
import cv2
import numpy as np
import base64
from glob import glob
import time
from IPython.display import display, Image, clear_output
from pathlib import Path
os.environ["OPENAI_API_KEY"] = userdata.get('OPENAI_API_KEY')
import cv2
import yt_dlp
2-2. まずは静止画の解釈(Image2Text)から
- 画像のエンコード関数定義
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
- 画像推論
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
encimg = encode_image("path/to/image.jpg") # 今回は図形画像のサンプル
output = llm.invoke([
HumanMessage(
content=[
{"type":"text", "text":"この画像は何を描画していますか?詳しく述べてください"},
{"type":"image_url", "image_url":
dict(url=f"data:image/png;base64,{encimg}")
}
]
)
])
print(output.content)
- 結果
| Image | GPT-4 omni answer |
|---|---|
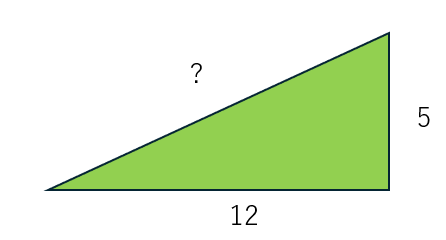 |
この画像は直角三角形を描いています。底辺の長さ(隣辺)は12単位、高さ(対辺)は5単位です。 斜辺(直角に対する辺)は疑問符で示されています。 斜辺の長さ ここで、 この三角形の場合: したがって、 |
問題なく図形認識・推論できている。今回のモデルは自然画像だけでなく、OCR性能も強化されているらしい.
2-3. 動画を解釈させる
- 動画をフレームに分割する関数の定義
- 全フレームを用いるわけではなくframe_stepごとにフレームをエンコーディング
def get_video_frames(youtube_url: str, frame_step: int = 50) -> list:
ydl_opts = {
'format': 'best',
'quiet': True
}
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
info = ydl.extract_info(youtube_url, download=False)
video_url = info['url']
cap = cv2.VideoCapture(video_url)
count = 0
frames = []
while True:
ret, frame = cap.read()
if not ret:
break
if count % frame_step == 0:
_, buffer = cv2.imencode(".jpg", frame) # 文字列にエンコーディング
frames.append(base64.b64encode(buffer).decode("utf-8"))
count +=1
cap.release()
return frames
- 動画のフレーム分割実行
- 今回はyoutube-8Mの対象動画から選定
frames = get_video_frames("yotubeのURL")
コマ送りにして確認
for frame in frames:
clear_output(wait=True)
display(Image(data=base64.b64decode(frame)))
time.sleep(0.2)
- 動画の内容を解釈させてみる
llm = ChatOpenAI(model="gpt-4o")
res = llm.invoke([
SystemMessage(
content="あなたは動画の実況者です。提供された動画の要約を生成してください"
),
HumanMessage(
content=[
{"type":"text", "text":"これらは動画のフレームです。"},
*map(lambda x: {"type": "image_url",
"image_url": {"url": f'data:image/jpg;base64,{x}', "detail": "low"}}, frames)
]
)
])
print(res.content)
- 結果
この動画のフレームから、次のような内容が推測されます。
1. **ポイント集計**:
- 最初の数フレームでは、プレイヤーの総獲得ポイントが表示されています。ジョシュ・レインがトップで、ナサン・スティンソン、ケビン・ブース、クーパー・ロベラ、デビッド・ウォンなどが続いています。
2. **ラウンドの結果**:
- ラウンド#6のポイント集計が表示され、ジョシュ・レインが9ポイントでトップ、デビッド・ウォンが5ポイント、ブレント・デニソンが4ポイント、マイク・デニソンが0ポイントを獲得しています。
3. **ゲームプレイ**:
- 多くのフレームは、4人のプレイヤーが「マリオカート」のレースをしているシーンを示しています。キャラクターには、ヨッシー、キノピオ、ピーチ姫、クッパが含まれています。
- プレイヤーは3ラップのレースを行っており、アイテムや障害物を使用しつつ競っています。
- 最後の数フレームで、レースの順位が表示され、ヨッシー、キノピオ、ピーチ姫、クッパの順で結果が示されています。
4. **総合結果**:
- 最後にラウンド#6の更新されたポイント集計が表示され、ジョシュ・レインがさらにポイントを獲得し、総ポイントが199に増加しています。
全体として、この動画は「マリオカート」のトーナメントまたは競技の一部を示しており、各ラウンドの結果と総合ポイントが更新されていく様子が描かれています。
えぇ... すご...
Discussion