#1「〜の冗長化」で見ていくインフラ構成のおさらい
はじめに
業務で3年間オンプレに触れてきて、複雑なインフラの構成って「〜の冗長化」って観点で見ていけば順を追っておさらいできると感じたので記事書いていきます。(こう思った経緯などは次項の自分語りで記載するので良ければ見てください!)
想定としては、インフラ構成としてWEBページを配信するシステム構築を例に、データセンターにOS・ソフトウェアを設定した筐体一台からスタートし、「〜の冗長化」って観点で筐体やOS等が増え、なんやかんやで仮想基盤が出てきて、最終的にパブリッククラウドだとこうなる!を一つずつ説明するというものです。
インフラ構成だけでなく技術要素や運用、tipsについても書きたいと思っていますが、色々書きたいので記事は複数に分ける予定で、今回の記事では今後どういう風に記事を書いていくかの導入を書いていきます。
記事の目的
- インフラに興味ある学生に対して、少しでも興味関心や理解向上の一助
- パブリッククラウド(AWS、GCP、Azure等)のみを触ってきた方々への、オンプレの説明
- 現在もしくは過去にオンプレ触ってきた偉大な方々に、ノスタルジーに浸ってもらったりご指摘や昔話を聞きたい
前置きとして自分語り(読み飛ばし可)
SIerでオンプレのエンプラでインフラしてるエンジニアです。流通系顧客の基幹システム&その他システムのどインフラ設計・構築・維持管理を3年間しており、データセンターファシリティ・NW・仮想基盤・サーバ・DBといったアプリより下のレイヤーで色々やってます。簡単に書くと、設計・構築フェーズではお客さんのシステムが集約されてる田舎のデータセンターに(オンプレたる所以)、色んな大企業が商業向けに作ってる凄い物理筐体を選別・搬入し(エンテープライズ略してエンプラたる所以)、お客さんのNWに繋げるために事前に設定追加したL2,L3スイッチのポートと接続してOSやミドルウェア導入等等等等。。。をして(インフラたる所以)、最終的にアプリケーションが使えるように基盤の準備頑張る!ということしてます。運用では、24時間365日稼働するエンプラシステム達が毎日のように悲鳴をあげるのでそのお守りをします。。。初めて直面するエラーや障害もよくあるので正直一番辛かったです。。。(その分馬力や瞬発力もついた気がしますが、まぁ結果論かなと)
ただ、念願叶い来月から晴れて部署移動をすることになったので、頭の中の整理やエンジニアらしくアプトプットをするために、業務で忙殺された副産物である大量のインプットを吐き出す目的で記事を書いていきます。
今後は、今回のタイトル記事を綴っていきつつ、体感したパブリッククラウドと比較した時のメリット・デメリットや、以下に書いてる業務で触れた各技術スタックや個人的に作って公開しているWEBアプリの技術や構成、AWSの資格を12冠した話などを書いていこうと思います。
データセンターファシリティ/Cisco/vShpere/Windows/Linux/AIX/Oracle/DC作業/AWS/react/typescript/golang
ちなみに今回のタイトルを記事にした理由は主に2つあり、1つ目はパブリッククラウドのみ触ってきた先輩同期後輩と業務やシステムの会話をそれぞれした時、想像以上に話が通じない部分があったので(AIXの上にDBとしてOracleのってると話したら「DBはRDSしか触ったことないがDBにOSってあるんですか?」と聞かれたり)、試行錯誤した結果少し具体的な可用性の観点で「〜の冗長性」と説明したら理解してもらえたためです。
2つ目は偉大な先輩方と話してる際に今回のブログの構想や、業務で経験した色んな話(得意分野isケーブリングや、Oracle8iを未だに使用してる等)を話したときに笑いながら面白いと言ってもらえて発表やブログ化も後押ししてもらったためです。あとみんな昔の苦労話好きみたいで思い出話に花も咲いてたので
スタートの構成
まずはスタートの構成は以下となります。

先にも述べましたが、インフラ構成と技術を順に追っていくために、WEBページを配信するシステムを題材にしていきます。上記を皆さんが実現させるなら物理サーバではなく、例えばAWSを使用して静的ページのホスティングではS3、負荷分散のためのロードバランサーではALBを使おう等を思い浮かべるのではないでしょうか。ただ、ここでは上記のように物理サーバにWEBサーバ(Apatch,Nginx等)、APサーバ(Tomcat,Puma等)、DBサーバ(Mysql,Oracle等)をインストールして設定まで行いWEBページを単に配信する「だけ」のシステムからスタートします。そこから「〜の冗長化」という観点でシステムを拡大させていって、最終的にはAWSのマネジメントサービスを使用した構成まで持っていきます。
〜の冗長化=単一障害点(SPOF)をなくすべし
先ほどのインフラ構成でWEBページを配信する「だけ」なら実現はできますが、世の中のシステムで同じインフラ構成のものは存在しないはずです。サービスは基本的には正常に提供し続ける必要があり、そのためにどんなシステムを作るときにもメインとなるサービスの機能以外に「非機能要件」を考慮する必要があります。ソシャゲやQRコードアプリを例にすると、ゲーム自体は面白く決済でも便利で文句がなくても、使えなくなったり表示が遅くなったり自分達のデータが外部に漏れたりした瞬間にみんなが困るため、非機能要件を考えるのはとても大切なことです。
今回はその非機能要件の中でも「可用性」という項目がまさに「〜の冗長化」という観点を表しており、これを突き詰めれば正常に提供し続けられるサービスに近づきます。
突き詰めていくにはどうするかと言うと単一障害点をなくしていけば良いです。単一障害点はSPOF(Single Point of Failure )と記載されることもあり、その1箇所で障害が発生して使えなくなるとシステム全体が停止してしまう箇所を表現しています。言葉だけでなく図でも見てみると、先ほどの構成でどこか1つが故障したらサービスが停止する箇所があるか?=単一障害点があるかを見ていきます。
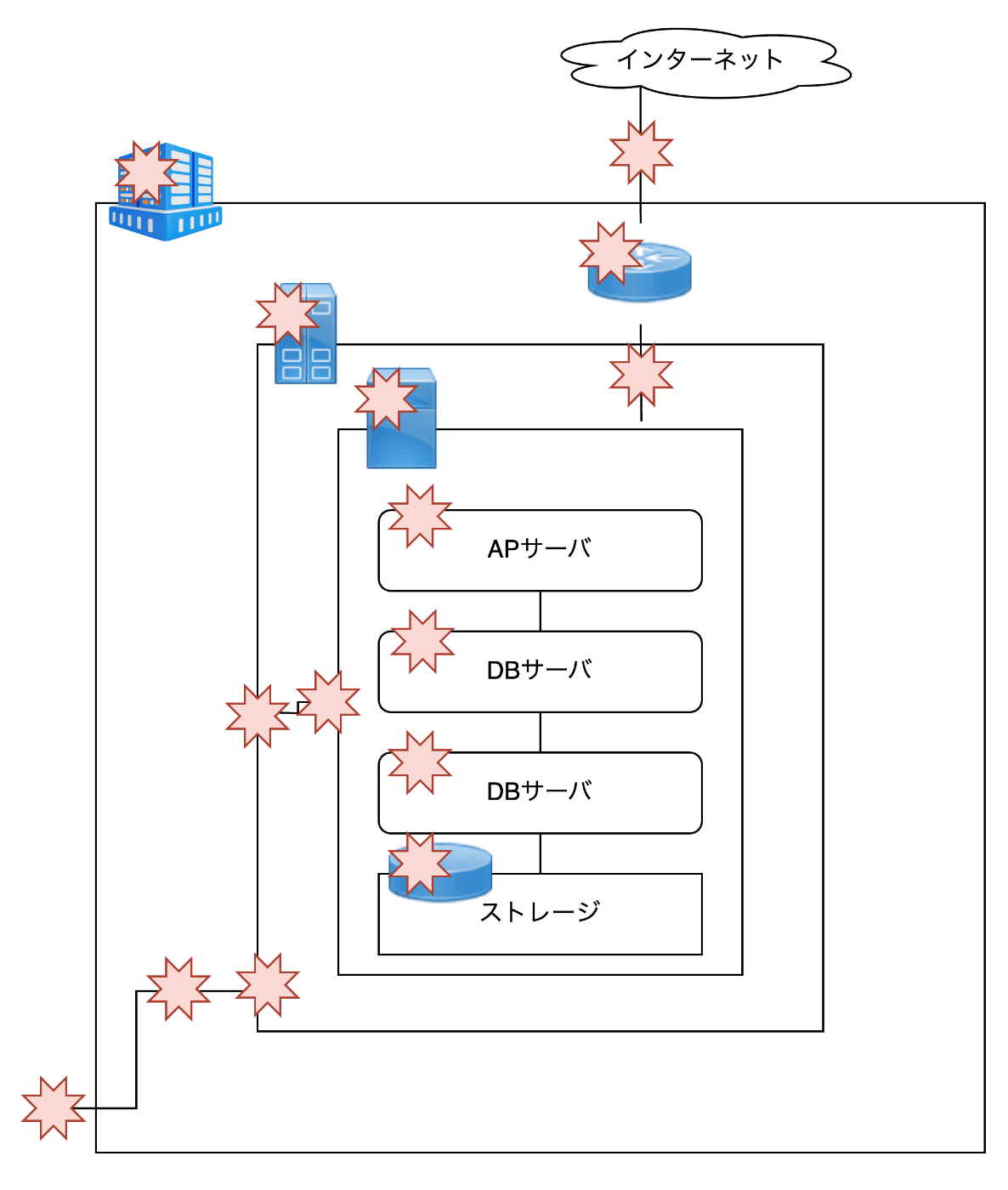
上の図の赤いマークが今回のスタート構成での単一障害点で、それを「〜の冗長性」という表現で記載したのが以下です。
- 電源系統の冗長性
- 電源の冗長性
- データセンターの冗長性
- ケーブルの冗長性
- ラックの冗長性
- 機器の冗長性
- インターフェースの冗長性
- 回線の冗長性
- 通信キャリアの冗長性
- ネットワークの冗長性
- ストレージの冗長性
- OSの冗長性
- DBの冗長性
- アプリケーションの冗長性
どうでしょうか、思ったより多いと感じたのではないでしょうか?今後の記事でこれらを改善していきWEBページを継続的に配信出来るインフラ構成に近づけていきますが、1つだけ例として「ストレージの冗長性」についてこの場で取り上げてみます。
ストレージに赤いマークがついてると思いますが、一台しかない筐体の内部にある唯一のストレージ(HDDやSSD)が物理故障したらどうなるでしょう?WEBページを配信するシステムもただHTML情報を送信するだけでなく、アクセスログだったりログイン情報等をストレージに溜め込みますので、唯一のディスクが故障すると処理ができなくなり正常に機能しなくなります。そのため「ストレージの冗長性」を考慮した構成を考えるならば、サービスで必要となるデータは筐体外に出している外部ストレージを使うSANの形態や、仮想基盤であればSDSで内部ストレージを仮想化して冗長化させたHCIを採用したりも考えられます。今後はこう言った内容を一つずつ説明しきます。
おわりに
この記事のまとめとしては
- インフラの構成や技術をおさらいするために、「〜の冗長化」って観点でシステムを見ていくよ
- 単一障害点(SPOF)をなくせば自然と「〜の冗長化」を満たせるよ
となります。良ければ次も見てください!
Discussion