Automation 360で、簡単に自然言語処理を使ってみる。 [Automation360 × Amazon Comprehend]
やりたいこと
気軽にNLP(自然言語処理)のサービス使ってみたい。ということあると思います。
この記事では、自然言語処理分野の以下の処理をノーコードRPAで自動化してみます。
- 言語検出
- キーワード取得
- 固有表現の取得
- 感情の識別
使用した環境情報
RPAは、Automation 360を使用します。
どんなRPAツールでもいいですが、Automation 360は画面操作だけ(ノーコード)で、認証情報の暗号化、ロボット(=RPA)の作成が簡単にできるので選んでいます。
この記事では比較についてあまり書きません。
Automation 360ではCommunity Edition(無償評価版)が提供されていますので、それを利用しています。執筆時点では、v27相当です。
※Community Editionの使い方は割愛します。
環境情報の詳細
[Automation 360]
サーバ環境
Community Edition: Build 16603(v.27)
クライアント環境
OS: Windows 11 Pro(Automation 360の要件としては、サポート外です。)
Bot Agent: 21.230.18464
CPU: Ryzen7 5800U 8 Core
MEM: 16 GB
※今回はドメイン参加していない端末で実施しています。
[AWSアカウント]
IAMユーザ: yud(手順内で作製しています。)
イメージ図
使用した環境と、この記事で実現したい流れはこんな感じです。

事前準備
AWS環境へ接続する際の、認証情報を暗号化するために、Automation 360のCredential Vaultという機能を使用します。
ロッカーを作成し、作成したロッカーの中に認証に必要な資格情報(Access Key/SecretKey)を格納することで、勝手に暗号化情報として扱ってくれます。
IAMアカウントの作成とAccess Key, SecretKeyの取得
Amazon ComprehendにアクセスするためのIAMアカウントを作成します。
既存のIAMユーザにて、アクセスキーを作成する場合は、下部の[既存のユーザでAccess KeyとSecret Keyを作成する場合]を参照してください。
※アカウント作成には権限が必要です。
今回はAWSの画面へログインせず、API経由で操作するため、API経由専用のアカウントを作成します。
AWS Management Consoleにログインし、IAMに接続します。

IAMユーザ作成画面へ遷移します。

[ユーザ名]を入力し、AWS認証タイプにて、[アクセスキー- プログラムによるアクセス]を選択し、[次のステップ: アクセス制限]をクリックします。

ユーザに付与する権限を選択します。
ここで既存ポリシーの中で、最低限の権限に絞り、AWS Comprehendのサービスのみにアクセスできるユーザとしています。
[既存のポリシーを直接アタッチ]をクリックし、[ComprehendReadOnly]を選択します。

ユーザにタグをつけたいときは、タグを指定して、[次のステップ: 確認]をクリックします。

サマリにて、内容を確認して[ユーザの作成]をクリックする。

作成したユーザが表示されるので、アクセスキーIDと、シークレットアクセスキーを控えます。
※[.csvのダウンロード]をクリックすることで、CSVで出力することも可能です。

[閉じる]をクリックし、作成したユーザが表示されれば完了です。

既存のユーザでAccess KeyとSecret Keyを作成する場合
IAMから、IAMユーザメニューへ進み、[認証情報]タブを開きます。

[アクセスキーの作成]をクリックします。

作成したアクセスキーのアクセスキーIDと、シークレットアクセスキーを控えます。
※[.csvのダウンロード]をクリックすることで、CSVで出力することも可能です。
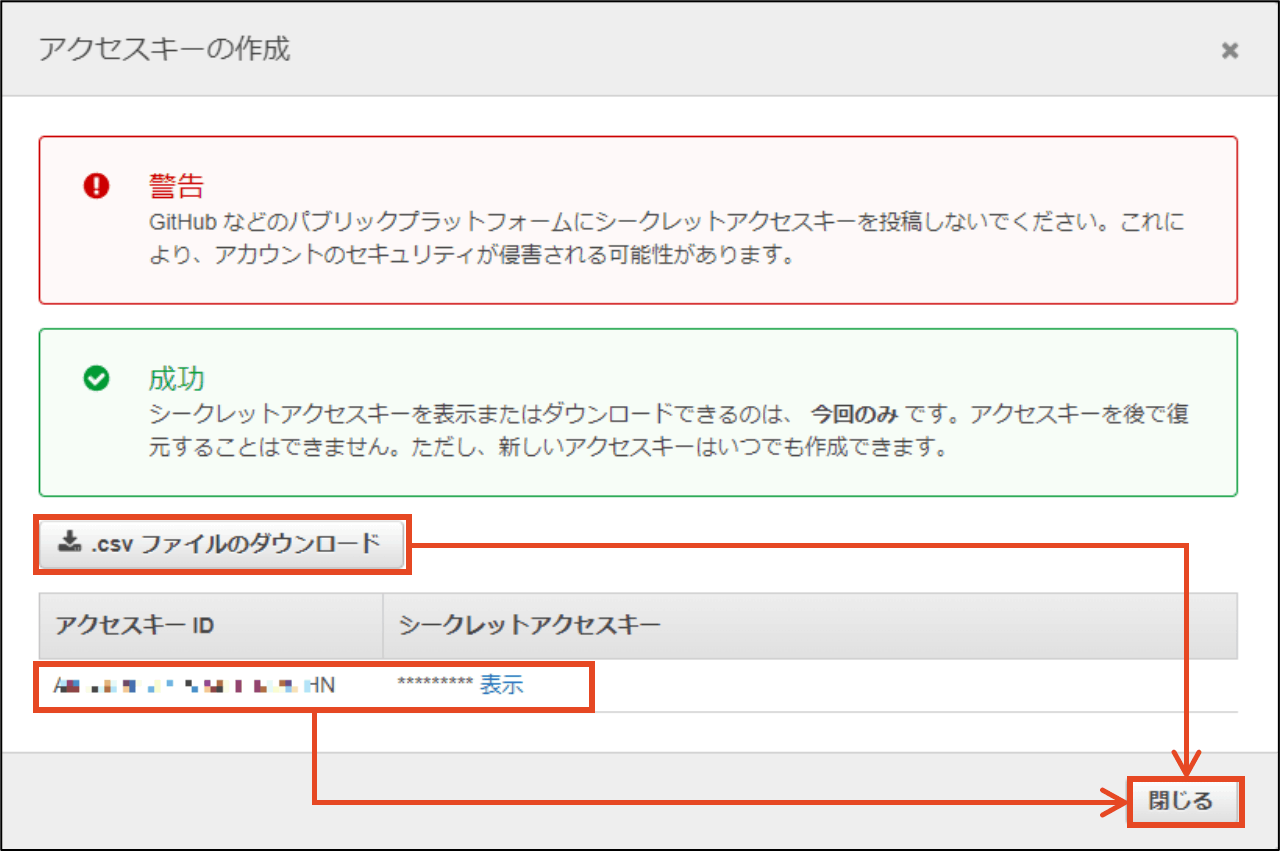
作成したアクセスキーが表示されます。

ロッカーの作成と権限付与
※本手順はロッカー作成済みの場合、スキップしても問題ありません。
Automation 360 Community Editionへログインし、メニューより資格情報を選択し、ロッカータブへ移動します。
その後、[ロッカーを作成します。]をクリックします。

ロッカー名と、説明を適当に入力し、[ロッカーを作成...]をクリックします。

ロッカーが作成されたことを確認して、ロッカーの作成は完了です。

次に、ロッカーに格納された資格情報を使用する権限を付与します。
作成したロッカー名をクリックします。

[コンシューマー]に、[CE_user]ロールを追加します。

[CE_user]の選択方法
[CE_user]に✅をつけ、[→]をクリックすると、選択済みへ移動できます。

資格情報の作成
次はAccess Key、Secret Keyを含める資格情報を作成します。
[資格情報]タブをクリックし、[資格情報を作成します。]をクリックします。

資格情報の名前と、説明を入力し、格納先のロッカーにて、先ほど作成したロッカーを選択状態にします。

ロッカーの選択方法
格納するロッカーのラジオボタンをクリックし、[→]をクリックすると、選択状態になります。

属性欄にて、ユーザ名とパスワードの2つの属性を作成します。
入力項目は、[標準]を指定して作成します。
Access Key: 作成したアクセスキーのAccess key IDを指定。
Secret Key: 作成したアクセスキーのSecret access keyを指定。
CSVでダウンロードした場合のアクセスキーの紐づけ。
CSVでダウンロードした場合、以下の割り当てとなります。


属性の追加方法
[+]アイコンをクリックすると、属性欄を増やすことができます。

👇

属性を入力したら、ページ最上部の[資格情報作成]をクリックします。

資格情報が作成されたことを確認し、完了です。

これでAWS Comprehendへ接続するアクセスキーを暗号化して使う準備が整いました。
AWS Comprehend NLPパッケージを使ってみる。
接続までできたので、実際にパッケージを使っていきます。
以下のマニュアルを参照しています。
アクションの設定で出てくる各項目について。
-
Region
接続するAmazon Comprehend サービスのエンドポイントを指定します。
日本の場合、以下になります。
ap-northeast-1[東京]
※大阪リージョンは、[Amazon Comprehend]サービスが執筆時点(2023年1月現在)提供されていないため、使用できません。
他の地域は、以下です。
https://docs.aws.amazon.com/general/latest/gr/rande.html#regional-endpoints -
Language Code
処理する言語、読み取った文字の言語コードを指定します。
日本語の場合、[ja]を指定します。
英語の場合、[en]を指定します。
他の言語は以下の通りです。
https://docs.aws.amazon.com/comprehend/latest/dg/how-languages.html -
Access Key
事前準備にて作成したアクセスキーの情報を使用します。 -
Secret Key
事前準備にて作成したアクセスキーの情報を使用します。
資格情報の指定方法
資格情報を指定する一例です。
[資格情報]項目が選択されていることを確認し、[選択]をクリックします。

各項目を選択します。

ロッカー:本手順内で作成したロッカーを選択します。
資格情報:本手順内で作成した資格情報を選択します。
属性:本手順内で作成したAccess Key、またはSecret Keyを項目に合わせて、指定します。

Get key phrase(キーフレーズ抽出)
主要なポイントを識別し、キーフレーズのリストを返します。たとえば、入力テキストがバスケット ボールの試合に関するものである場合、このアクションはチームの名前、会場の名前、および最終スコアを返します。
読み込ませた文字列のキーフレーズを抽出できます。
とりあえず、使ってみます。
[Get key phrases]アクションを配置し、アクションプロパティを設定します。
- Input Text
キーフレーズを抽出したい文字列を指定します。
今回は、Wikiよりこの説明文を読み込ませています。
クジラの発声は幾つかの目的を果たすと考えられている。ザトウクジラなどの特定の種に属するクジラはクジラの歌として知られるメロディのような音を発して交信する。クジラは種によって極めて大きな音を発する。ザトウクジラの発する音はクリック音などの突発音であるが、ハクジラ類は2万ワットの音(+73dBmまたは+43dBw)を発するソナーを使用し、その音は遠方からでも聞こえるとされる。
捕獲されたクジラは人間のスピーチを模倣することで知られている。科学者にはクジラは人間との意思伝達を強く希望するが、人間とは異なる発声構造を持つため相当な努力を払って人間のスピーチを模倣するという説を提唱する者もいる。
クジラはホイッスルとクリックスと呼ばれる音響信号を発する。クリックスは広帯域での急速な突発音で、ソナーに使用されるが、低い周波数帯の発声はコミュニケーションのような非エコロケーション用途に使用されることがある。例としてベルーガが発するパルス音がある。一連のクリック音のパルスは35-50ミリセカンドの間隔で発せられ、一般的にクリック音の間隔はターゲットに対する音の往復時間より多少長い。ホイッスルは狭帯域の周波数変調(FM)信号で、交信などのコミュニケーションの目的に使用される。
引用:Wiki(クジラ-コミュニケーション)https://ja.wikipedia.org/wiki/クジラ
※他のプロパティは上述した通りです。

変数の作成方法
[変数を作成]アイコンをクリックします。

[変数名]を入力し、[作成して選択]をクリックします。

変数が選択状態になりますので、完了です。

結果はメッセージボックスに表示してみます。
[メッセージ ボックス]アクションを配置し、[表示するメッセージを入力]欄に、結果を格納したリスト変数を文字列に変換した形式で出力します。

変数の指定方法
下記をそのまま入力します。(コピーして貼り付けてもらうといいと思います。)
$キーフレーズリスト.LegacyAutomation:listToString$
※変数名を変更している場合は、「キーフレーズ」の部分を変数名に変更してください。
Botを実行すると、検出した言語を取得することができます。

メッセージボックスにリスト変数に格納されている値が出力されています。

実際は、こんな感じでリストにインデックス順で入っています。
※デバッグモードで確認しています。

キーワードっぽいものができているようです!(?)
(わかりやすいテスト用文字列が欲しいです。。)
Detect language(言語を検出)
入力されたコンテンツの言語を識別し、ISO 639-1 言語コードで返します。出力は文字列変数に格納されます。このアクションは 100 以上の言語をサポートしています。「優先言語の検出」で全リストを参照できます。
読み込ませた文字列の言語コードを取得できます。
例えば、[こんにちは]をインプットとすると、[ja]を返します。
[Hello]をインプットすると、[en]を返します。
ということで使ってみます。
[Detect language]アクションを配置し、アクションプロパティを設定します。
- Input text
言語を判定したい文字列を入力します。 - Assign the output to a string variable
言語コードの結果を確認する文字列変数を指定します。
※他のプロパティは上述した通りです。

変数の作成方法
[変数を作成]アイコンをクリックします。

[変数名]を入力し、[作成して選択]をクリックします。

変数が選択状態になりますので、完了です。

結果をメッセージボックスに表示してみます。
[メッセージ ボックス]アクションを配置し、[表示するメッセージを入力]欄に、結果を格納した文字列変数を指定します。

変数の指定方法
[値を挿入]アイコンをクリックします。
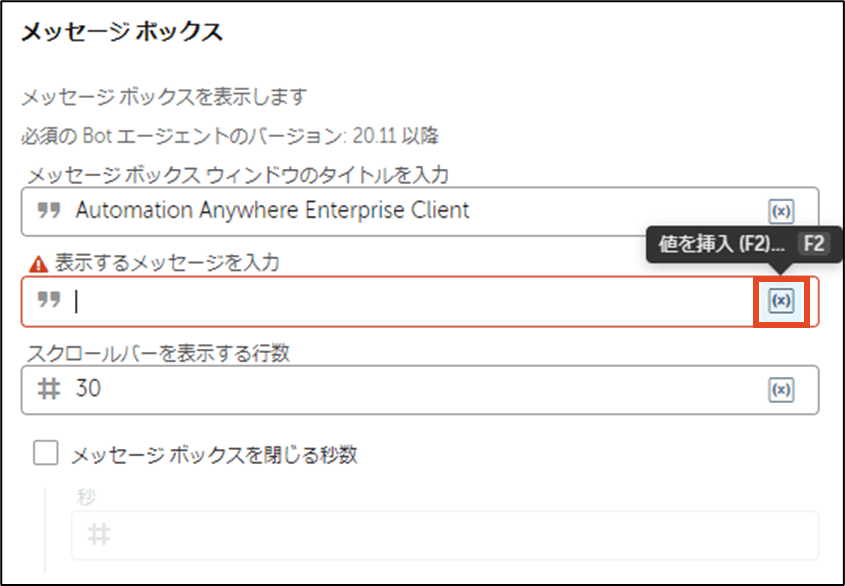
ドロップダウンより、作成した変数名を選択し、[はい、挿入]をクリックします。

変数が選択状態になりますので、完了です。

Botを実行すると、検出した言語を取得することができます。

メッセージ ボックスに検出した言語コード[ja]が出力されています。
言語を変えて実行してみます。

検出した言語コード[en]が出力されています。

これで入ってきた文字列の言語コードを取得することができました。
Get named entities(固有表現の取得)
人物、場所、組織、日時、数量、ブランド製品、書名など、入力されたコンテンツのエンティティを特定します。
出力はディクショナリ変数に格納されますが、それぞれの名前がキーで、対応するエンティティが値になります。
文字列の中から、固有表現の取得が可能です。
これも、とりあえず使ってみます。
[Get named entities]アクションを配置し、アクションプロパティを設定します。
- Input Text
固有表現を取得したい文字列を指定します。
今回は、以下を指定します。
北極商事人事部門に所属する白熊白夫です。北海道に住んでいます。

変数の作成方法
[ディクショナリ]をクリックした後、[変数を作成]アイコンをクリックします。

[変数名]を入力し、[作成して選択]をクリックします。

作成した変数が選択状態になりますので、完了です。

結果をメッセージボックスに表示してみます。
[メッセージ ボックス]アクションを配置し、[表示するメッセージを入力]欄に、結果を格納したディクショナリ変数を文字へ変換して指定します。

変数の指定方法
下記をそのまま入力します。(コピーして貼り付けてもらうといいと思います。)
$固有表現一覧.LegacyAutomation:dictionaryToString$
※変数名を変更している場合は、「固有表現一覧」の部分を変数名に変更してください。
Botを実行すると、文章に含まれている固有表現を取得することができます。

メッセージボックスに検出できた固有表現とエンティティが紐づいて出力されています。

ちなみに、ディクショナリのままみるとこんな感じです。
KeyとValueで紐づいて格納されています。
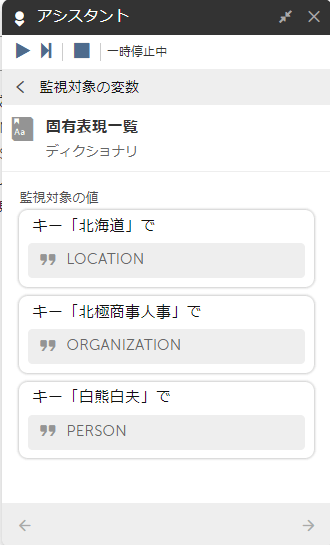
思ったより取れたので感動です・・・!
Get sentiment(感情の検出)
入力されたコンテンツを分析し、可能な限り包括的な感情とスコアを返します。ディクショナ?リ値の出力例:
POSITIVE {Positive: 0.66238534,Negative: 0.0013064129,Neutral: 0.33621928,Mixed: 8.892125E-5}
出力は、2 つのキーとそれに対応する値を含むディクショナリ変数、sentiment および score に格納されます。
一番わくわくする機能です。
読み込ませた文章からPositive, Negative, Neutral, Mixedの4つの感情スコアを取得します。
取得したスコアから感情分析ができたりします。
早速使ってみます。
[Get named entities]アクションを配置し、アクションプロパティを設定します。
- Input Text
感情スコアを取得したい文字列を指定します。
今回は、Automation Anywhere Japan 公式HPに記載されている以下を指定してみます。
Automation 360 は世界中のトップ企業で利用されている最先端のインテリジェント オートメーション プラットフォームです。
エンドツーエンドの自動化を実現する、世界でも類を見ないクラウド ネイティブの Web ベース プラットフォーム。自動化プロセスの量は倍増し、従来型 RPA システムのインフラストラクチャに比べわずかなコストで、スケーリングは 3 倍にも高速化されます。
<引用:https://jp.automationanywhere.com/products/automation-360>

変数の作成方法
[ディクショナリ]をクリックした後、[変数を作成]アイコンをクリックします。

[変数名]を入力し、[作成して選択]をクリックします。

作成した変数が選択状態になりますので、完了です。

結果をメッセージボックスに表示してみます。
[メッセージ ボックス]アクションを配置し、[表示するメッセージを入力]欄に、結果を格納したディクショナリ変数を文字へ変換して指定します。

変数の指定方法
下記をそのまま入力します。(コピーして貼り付けてもらうといいと思います。)
$検出した感情スコア.LegacyAutomation:dictionaryToString$
※変数名を変更している場合は、「検出した感情スコア」の部分を変数名に変更してください。
Botを実行すると、文章から感情スコアを取得することができます。

メッセージボックスに全体の感情と詳細なスコアが出力されています。

ディクショナリのままみるとこんな感じです。
KeyとValueで紐づいて格納されています。

説明文になるので、Neutralとなりましたが、詳細なスコアを見ると、Positiveが高めに出ているので、明るめな説明文であることが分かります。(暗くはないことが分かります。)
まとめ
RPA(Automation360)で自然言語を、ノーコードで使用する方法について紹介しました。
色々試してみたくなってしまうほど、簡単に自然言語処理ができてしますので、感動です。
通常Amazon Comprehendを簡単に使う場合、AWS Managementコンソールにログインして、サービスの画面を開いて、文字を入力して目視確認。。。くらいでしたが、RPAを使うことで、簡単にExcelへの転記や連続処理、他システムへの連携などできそうですね。
NLPを使う人が増えることで、アイデア数も増えるので、活用シーンも広がりそうです。
実際に使う際のユースケースもいつかは記事にしてみようと思います。
それでは。よい自動化ライフを!
Discussion