【図で解説】Firestoreでできること・できないこと
Firestoreとは
Google社が提供するNoSQL型のデータベースです。
特徴として、リアルタイムのデータを受信できる、つまりDB側のデータが変更されるとすぐに、クライアント側に反映される仕組みを提供しています。
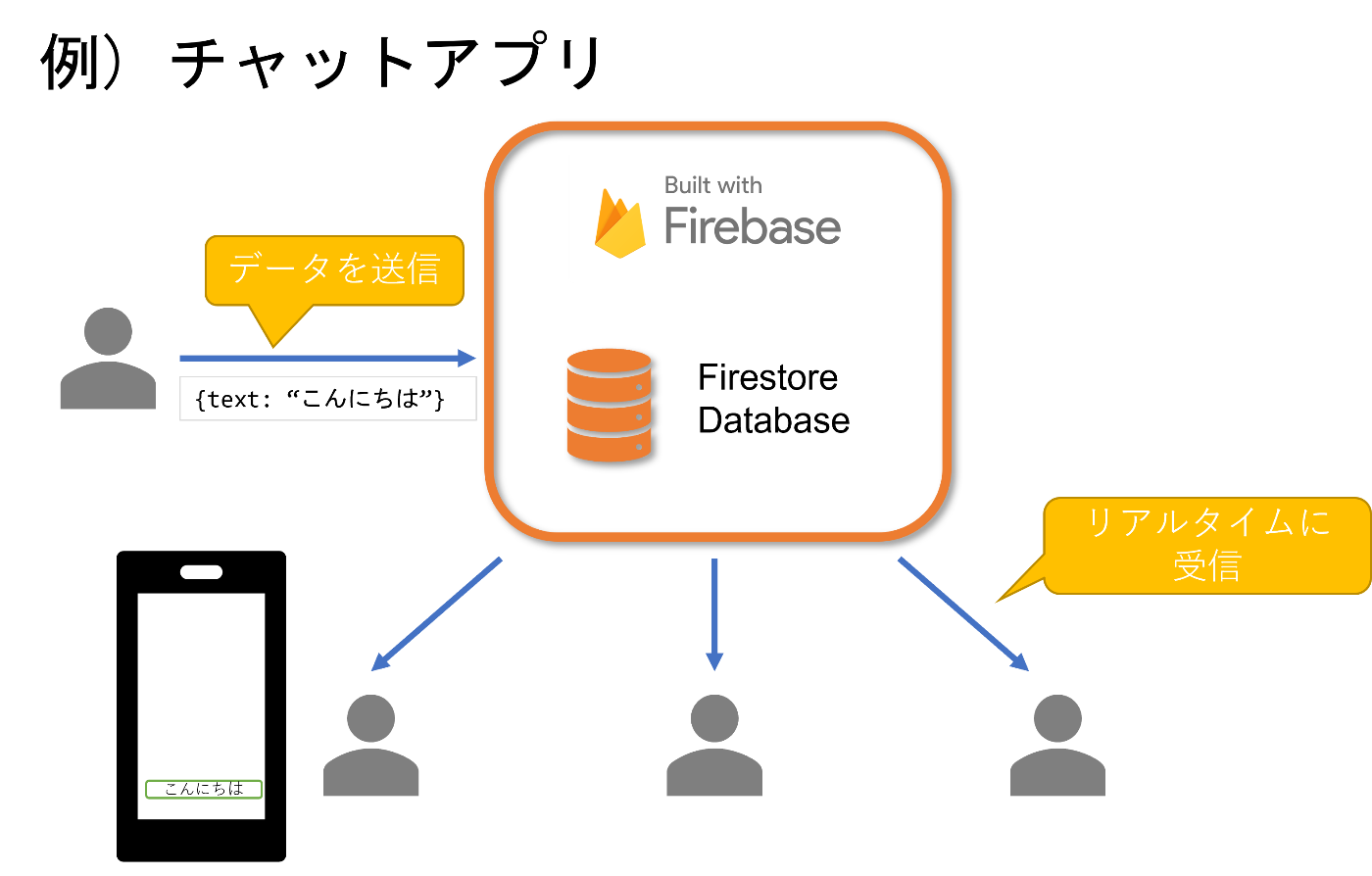
FirestoreはNoSQLの1つ
NoSQLとはざっくり言えば、RDB以外のデータベース製品です。FirestoreもNoSQLの1つです。Firestoreのデータ構造は、個人的な印象でいえば階層化されているKVSです。
KVSとは
KVS(Key-Value Store)とは、JavaでいうMap、Pythonでいう辞書、PHPでいう連想配列にあたるデータ構造です。キーとそれに紐づけられたデータを管理します。
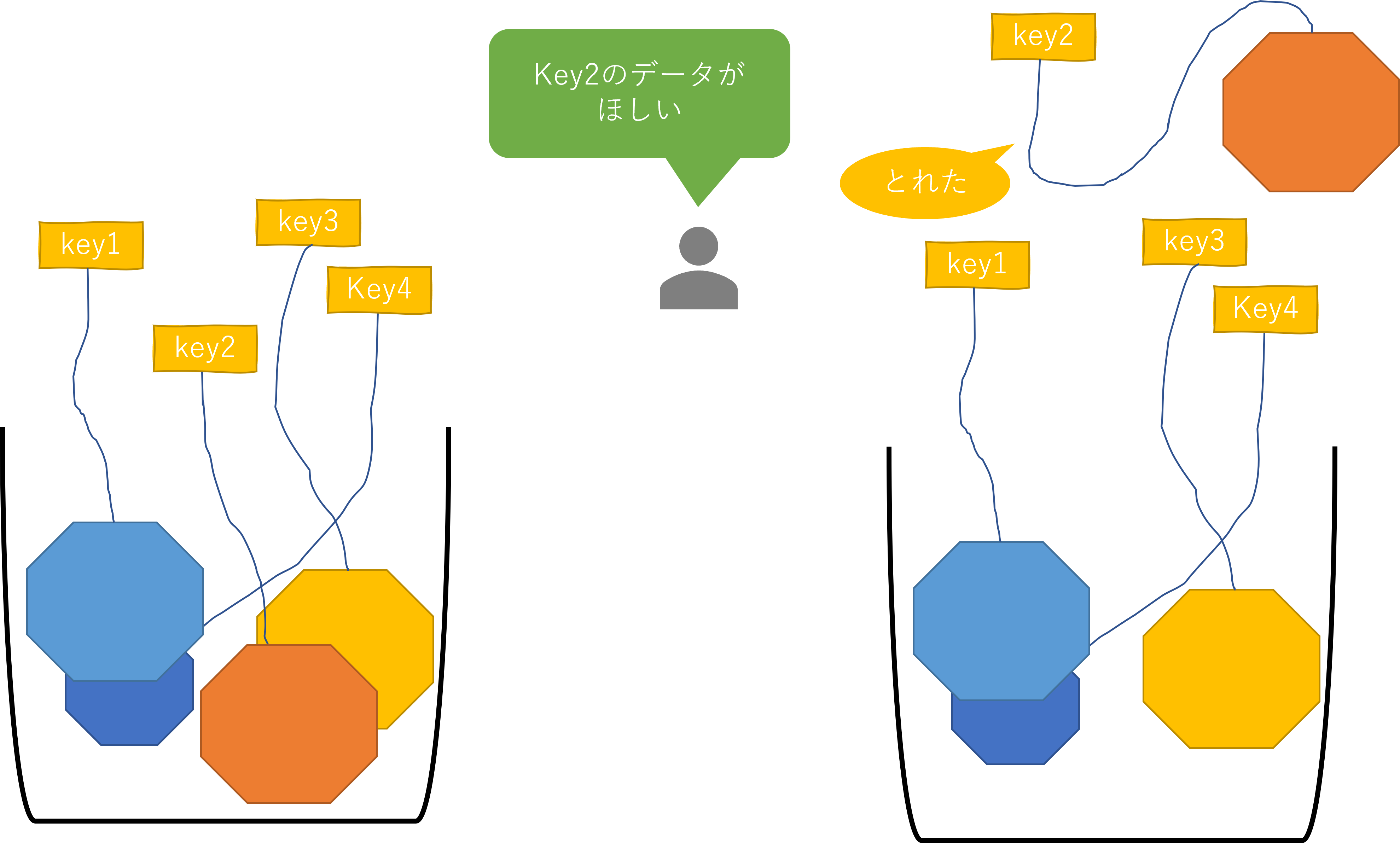
KVSは一般的に逆引きに弱いです。逆引きとは、条件を満たすデータを取得することです。例えば、ユーザIDがキーで名前と電話番号が関連付けられたデータのとき、名前が"鈴木"で始まるデータをとるという操作です。
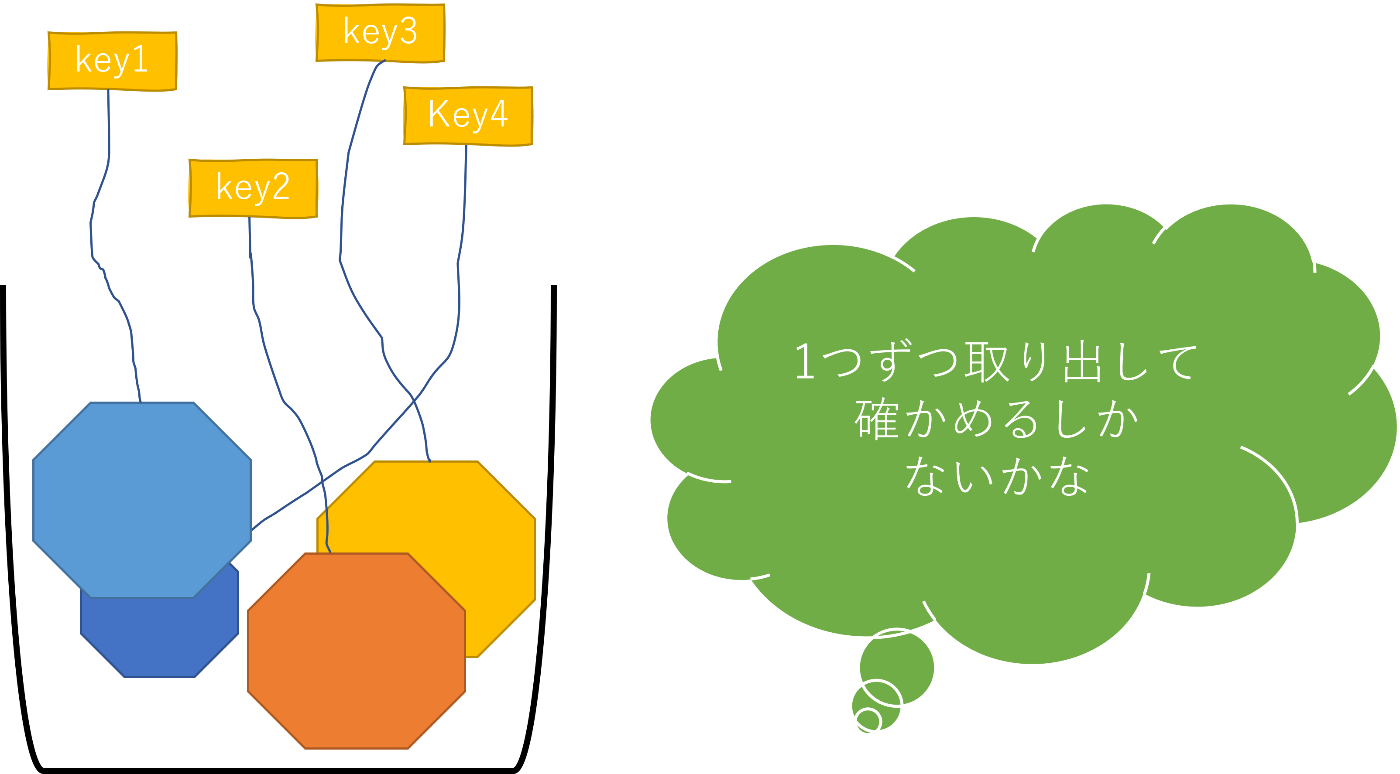
逆引きに対応するため、Firestoreではインデックスを作成することができます。フィールド単位のインデックスは自動で作成されます。ただし、すべての逆引きのケースに対応できるわけではありません。詳しくは以下をご覧ください。
Firestoreのデータ構造
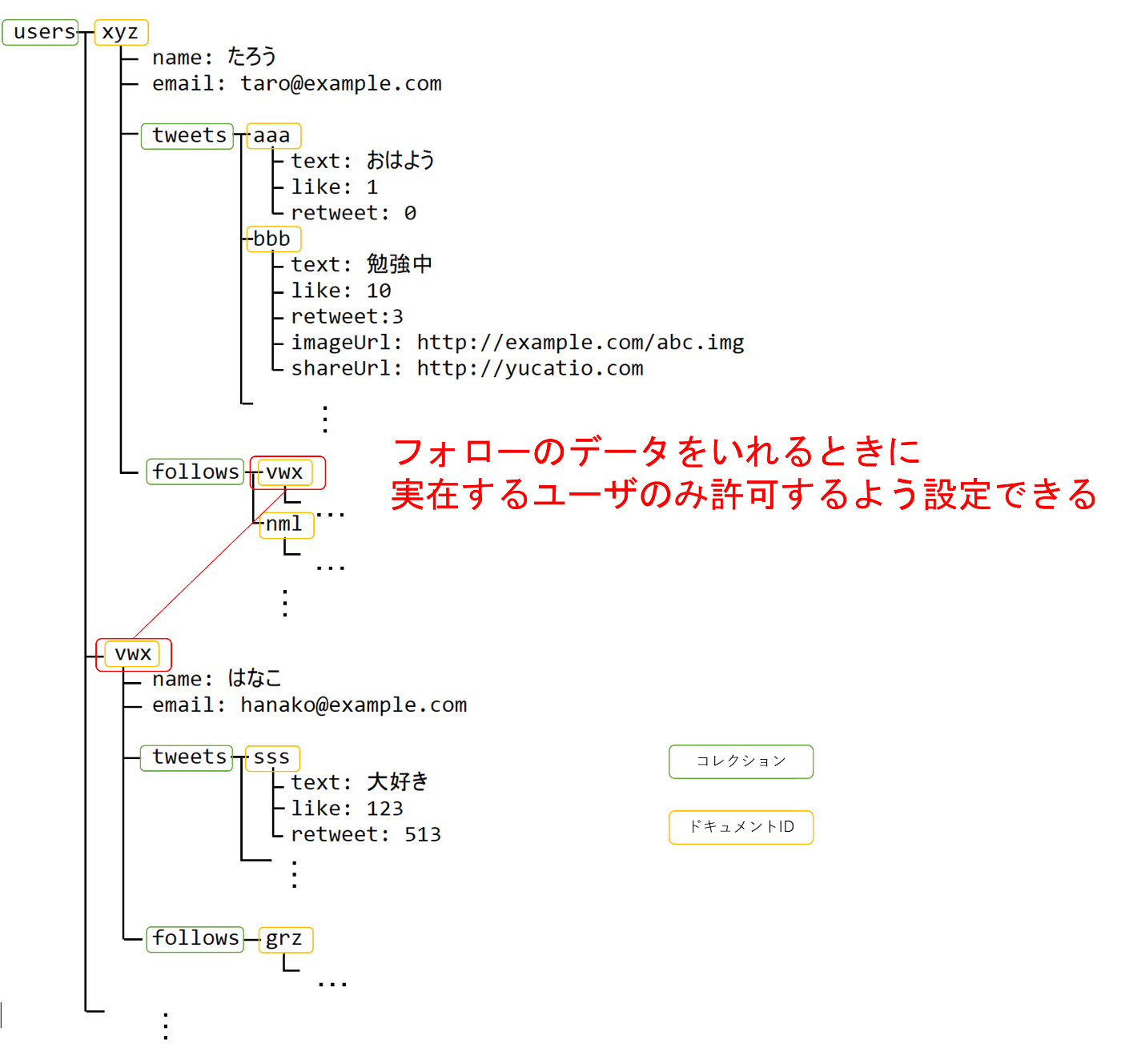
Firestoreのデータ構造はRESTのパスのような構造のようになります。例えば、twitterのような投稿システムを考えてみましょう。各ツイートのパスを
/user/{user_id}/tweets/{tweet_id}
のように定義しましょう。
このとき、usersやtweetsの部分をコレクション、{user_id}や{tweet_id}の部分をドキュメントIDと言います。/user/{user_id}や/user/{user_id}/tweets/{tweet_id}で取得されるデータをドキュメントといいます。
このようなパスで表されるとき、実際のデータはこのような階層データになっています(followsコレクションも追加しています)
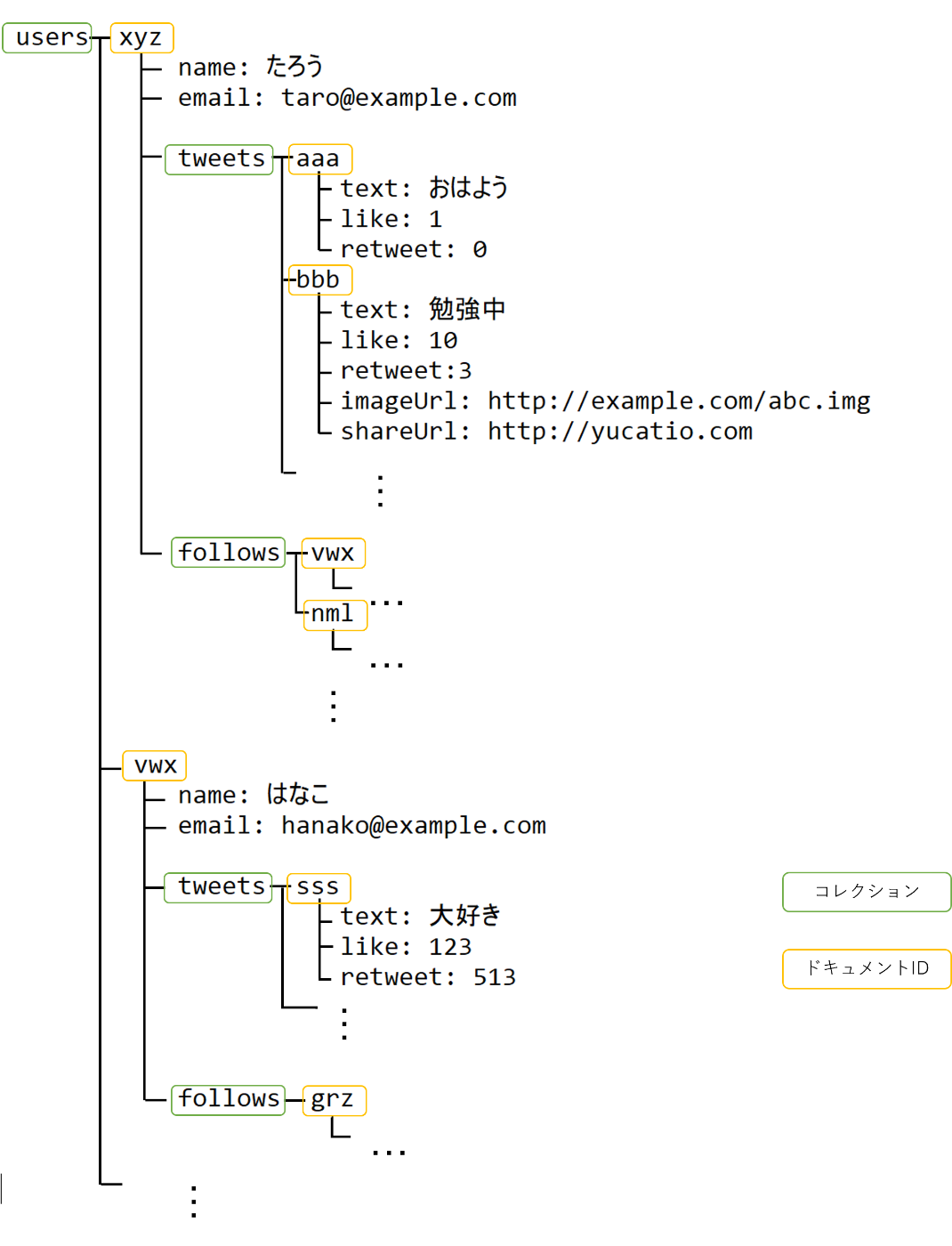
以下ではこのデータ構造の時にできることとできないことを見ていきます。
検索系
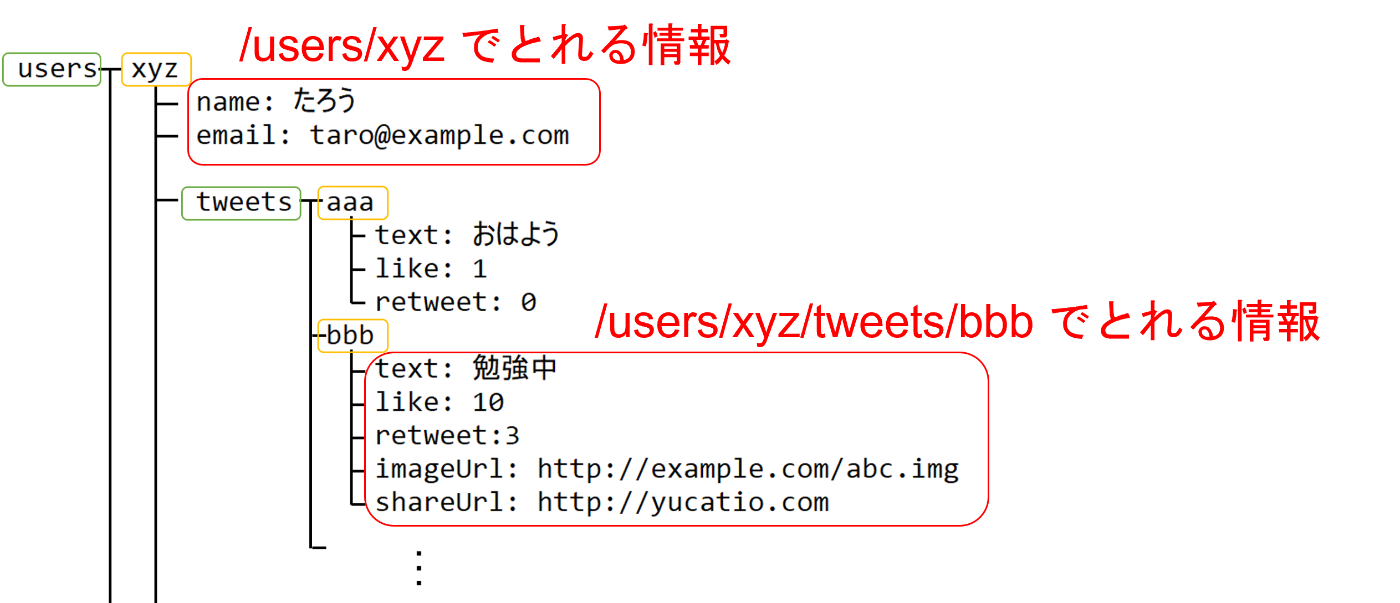
IDでの検索
FirestoreではドキュメントIDを指定し、データを取得する処理を簡単に書くことができます。
IDに紐づくデータを全て取得 : 〇
SQLでいうところのselect * from {table_name} where id={id}に相当するデータが取れます。
ちなみに親のドキュメントID(以下の例では/users/xys)を指定した場合、サブコレクションのデータは取得されません。
IDに紐づくデータを一部取得 : ×
SQLでいうところのselect aaa, bbb from {table_name} where id={id} のように、フィールドのうちの一部のみを取得することはできません。

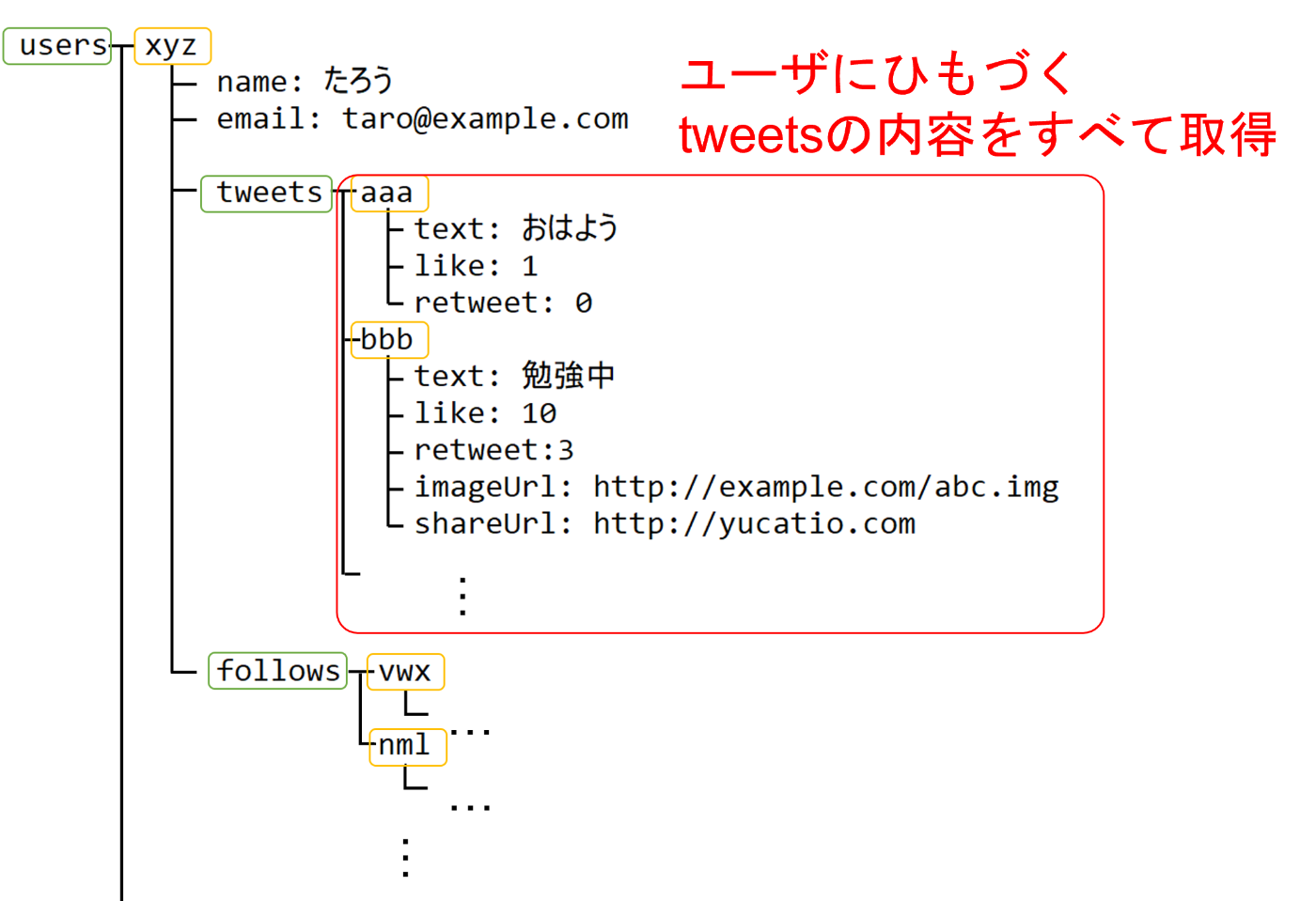
(サブ)コレクションに紐づくデータを全部取得
あるユーザのtweetの全てを取得することは可能です。検索条件を指定することも可能です(以下の逆引きのところで指定できるもののみ)。
逆引き(検索クエリ)
Firestoreはデフォルトでは各フィールドに対してインデックスが張られているため、逆引きが可能です。また、複合インデックスを作成することも可能です。
また、比較演算子には < <= == => > などが使えます。
単一フィールドに対する検索クエリ : 〇
クエリに含まれるフィールドが1つであれば検索できます。
例えば、
- like数が10以上50以下のtweetを抽出する
- imageが存在するtweetを検索する
- share_urlが"https://yucatio.com"か"https://zennn.dev"であるtweetを検索する
などはそれぞれ検索が可能です。
複数フィールドに対する検索クエリ : △
複数フィールドに対する検索には大きな制限があり、==での比較は複数のフィールドにまたがって行えますが、範囲検索(< <= >= >で検索するもの)は1つのフィールドに対してしか発行することはできません。
できること:
- messageが"おはよう"のものでlike数が10以上50以下のもの
- 範囲検索が1つのフィールドに対してなのでOK
できないこと:
- like数が50以上かつretweetが100以上
- 範囲検索が2つ以上のフィールドにまたがっているのでNG
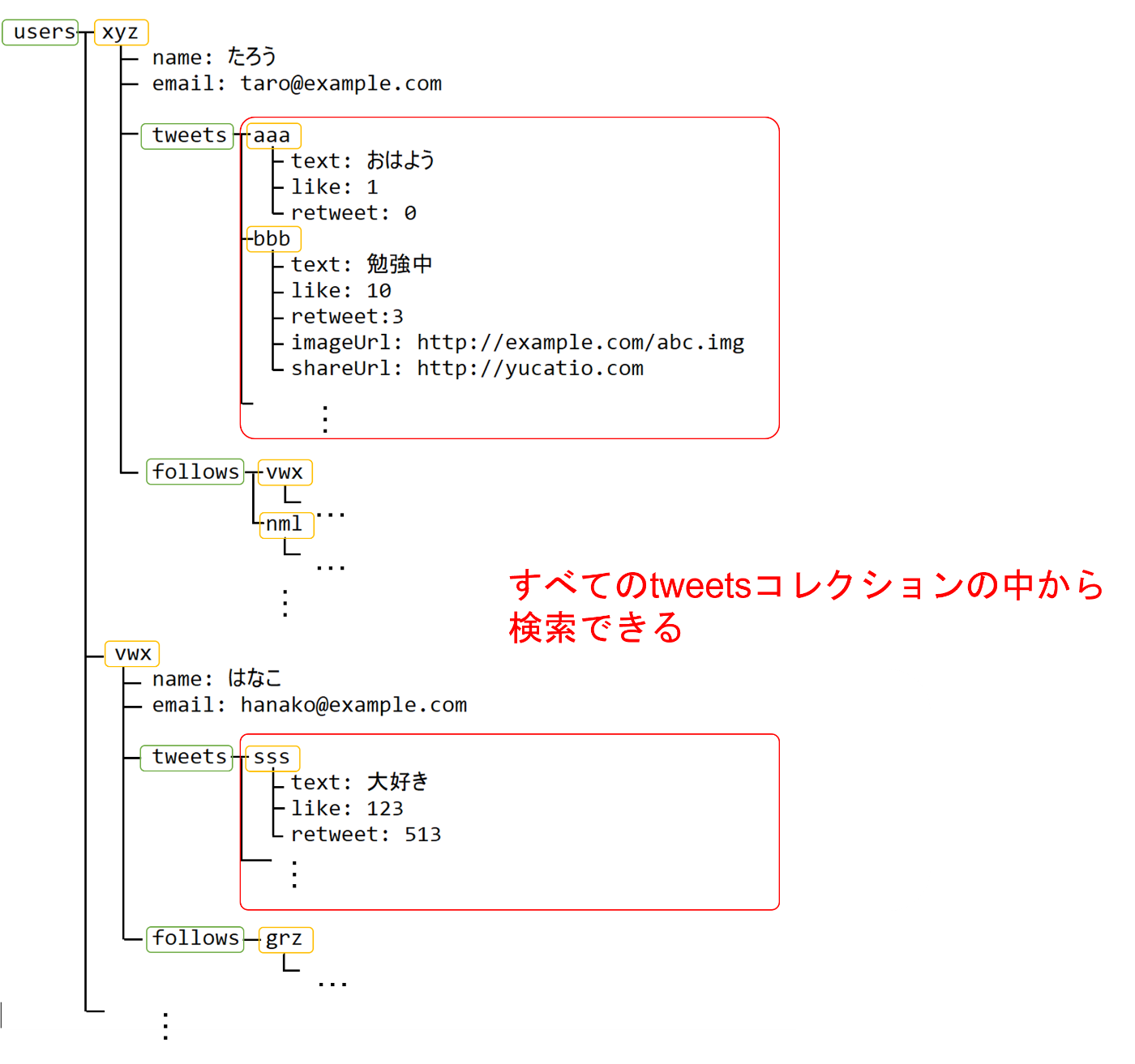
同一コレクション名で、ドキュメントをまたいだ検索 : 〇
全ユーザのtweetの中でlikeが100以上、のような検索はデフォルトではできませんが、インデッ
クスを追加することで可能となります。
複数フィールドで検索できない点は前述のものと同じです。
そのほか検索でできないこと
Firestoreは基本的にKVSなので、RDBでできることは基本的にできないと考えたほうがよいです。
ドキュメントのjoin : ×
ドキュメント同士をFirestore側でjoinすることはできません。クライアントサイドでjoinするか、非正規化してデータを持つ必要があります。
LIKE句検索 : ×
LIKE句検索にも対応していません。検索は別のシステムに任せましょう。
COUNT, SUMなどの集約関数 : ×
countやsumなどの集約関数もサポートされていません。クライアント側で計算するか、非正規化する、Cloud Functionsを組み合わせるなどして実現します。
更新系
transaction : 〇
Firestoreではtransaction処理を行うことができます。likeの数を1プラスするなどの動作にtransactionが使えます。(ただしこの場合はincrement機能を使ったほうがよいです)
設計系
FirestoreはDBを(アプリを介さず)そのまま外部に公開しているようなものです。悪意のあるユーザにデータを改ざんされないようにセキュリティルールを定めることができます。
データ型の指定 : 〇
Firestoreはスキーマレスですが、設定ファイルでスキーマのようなものを設定することができます。
指定できる型はboolとbytes、float、int、list、latlng(緯度経度)、number、path、map、string、timestampです。
enum型 : △
stringにはmatch関数が用意されています。この関数は正規表現で文字列がマッチするか判定します。enumのどれかに合致するかという正規表現を書けば疑似的にenumを実現できます。
// statusが"TODO"か"INPROGRESS"か"DONE"でないといけない
document.status.matches("^(TODO|IN_PROGRESS|DONE)$")
Not null制約 : 〇
ドキュメントに必ずフィールドがあることを保証することもできます。
uniq制約 : △
例えばユーザのemailを一意に制限するといった制約を持たせる設定はありません。
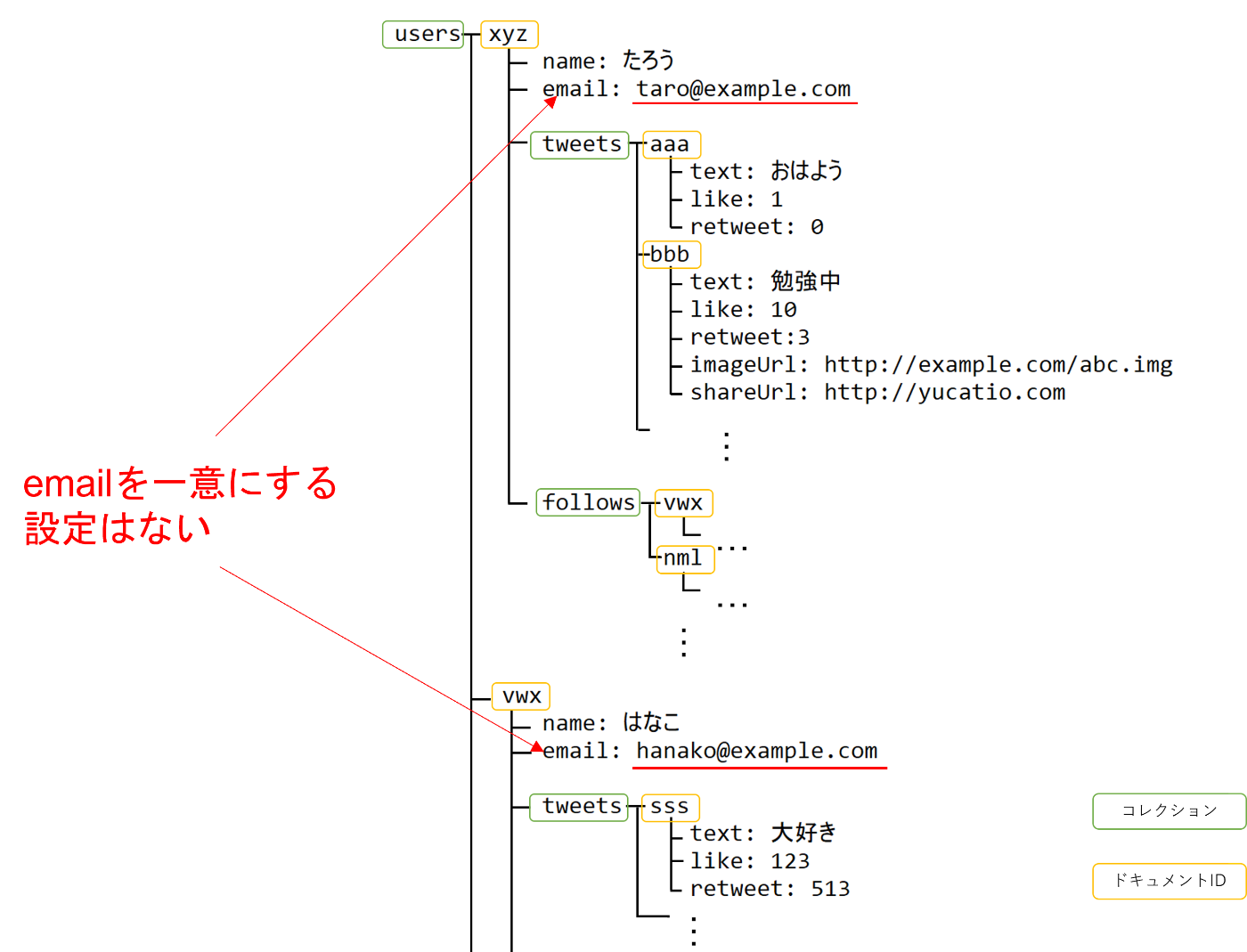
FirestoreのIDが一意になる制約と、バッチ書き込みを組み合わせると可能です。
デフォルト値 : ×
デフォルト値はサポートされていません。Cloud Functionsを組み合わせる方法でデータの作成時に値をセットすることができます(ただし、値がセットされるまで若干の遅延あり)。
外部キー制約 : 〇
例えば、フォローできるのは実在するユーザであること、といった制約を書くことができます。
フィールドの制限 : 〇
悪意のあるユーザやtypoなどによって意図しないフィールドが作成されるのを防ぐことができます。
データへのアクセス制御 : 〇
例えば、ツイートの内容を変更できるのはツイートした本人のみ、といったルールを書くことが可能です。
閲覧についても、ある特定の条件を満たす場合にのみ閲覧できるというルールを書くことができます。
一度登録したデータを変更させない : 〇
例えば、一度ツイートした内容を変更できないようにする、といったことは可能です。
終わりに
自分がFirestoreを触る前に知りたかったことをまとめてみました。
公式サイトに書かれていることと重複する内容も多いですが、なるべく図を多くしてわかりやすくしました。お役に立てれば幸いです。
Discussion