GraphQL と Apollo Clientの相性が良くないという勘違い
REST APIに代わるAPI規格として普及しつつあるGraphQL。
主にReactで利用されている印象ですが、Vueでも対応するライブラリがあるということで、最近、Vue Apollo + Composition APIの組み合わせで開発を行ってみました。かなり気に入っています。
ただ、使っていく中でどうしても気になったことというか、「GraphQLとApollo Clientのコンセプト、矛盾してない?」と思ったので、書いてみます。
※全然的外れなことを書いているかもしれず、どちらかというと悩み相談的なニュアンスなので、間違っていたらぜひご指摘お願いします!
※4/10追記:コメントにて@necocoaさんより無事にGraphQL/Apollo Client/GraphQL Code Generatorの正しい使い方を教えて頂くことができました。記事の内容を訂正しようとすると丸ごと書き直す必要があるため、タイトルを除いて初稿のままにしておきますので、「こんな風に感じる初心者もいるんだな」くらいの目線で流し読みして頂きつつ、コメントまで必ずご確認ください。
TL;DR
- GraphQLで欲しい値だけを指定して取得すると、同じモデルでもTypeScriptの型をクエリごとに書き分ける必要がある
- Apollo Clientにキャッシュされているデータにどの値が保持されているかも曖昧になる
- 自動生成された型を活かそうとするとREST APIのように全部の値を取りに行くことになってしまうのではないか
GraphQLの特徴
まず最初に、GraphQLの何が優れているのかについて。
GraphQLの特徴を分解する ~API インターフェース・Universal BFF・API Gateway~ - Qiita
上記の記事を参考に、主にフロントエンドから利用する場合の良さに絞って書いてみると、自分なりに整理してみます。
- クライアントが取得するデータを自由に指定出来る
- 必要なデータをクライアントサイドで指定できるので、サーバー側で追加開発を行ったり、必要のないデータを常に返したり、エンドポイントを増やしたりする必要がない
- 1つのリクエストで必要な情報を一気に取得できる
- TypeScriptとの相性が良い
- サーバーサイドで定義したSchemaがそのままドキュメントになる
- Schemaから型定義を自動生成することができる
- Apollo Clientが優秀
- Apollo Client自身がキャッシュ管理の機能を持つ(VuexやReduxを置き換えられる)
- TypeNameとIDを元に差分を自動更新してくれるため、「queryで取得した配列データの一部をmutationで更新した時」に、再度queryを取得したり自分で置き換えを行う必要がない
このように利点が豊富にあり、どれも、既存のREST APIが抱えていた問題点に対するアンサーになっていることがわかります。
私自身もGraphQLを数ヶ月書いてみて、この利点を概ね享受できているし、REST APIよりも便利だなと感じています。
が、使っていくうちにちょっとした問題が出てきました。
queryで必要なパラメータのみを指定すると、Schemaから自動生成された型と一致しなくなる
例えばブログの記事を以下のようなSchemaで定義します。
type Post {
id: ID!
category: String
body: String!
user: User!
createdAt: Date!
updatedAt: Date!
}
このSchemaからgraphql-codegen を使ってTypeScript用の型を自動生成すると以下のようになります。
export type Post = {
__typename?: 'Post'
id: Scalars['ID']
category?: Maybe<Scalars['String']>
body: Scalars['String']
user: User
createdAt: Scalars['Date']
updatedAt: Scalars['Date']
}
ここでundefinedの可能性があるのはcategoryだけとなっています。
しかし実際には、GraphQLのqueryで指定していない値は取得されていないので、
gql`
query Posts {
posts {
id
category
body
}
}
`
このようなクエリで取得したデータに、自動生成したPost型を当てはめることができません。常に存在しているはずのcreatedAtがundefinedだからです。当てはめることはできますが、ランタイムエラーの危険性が生じます。
implements Partial<Post> のように自分で定義し直すことはできるものの、クエリごとに書き直すなら自動生成の恩恵をそんなに受けられていないような気がします。
queryごとに要求するクエリが違うと差分更新が部分的にしか機能しない
例えばWordPressの管理画面のように一覧画面と編集画面があって、
一覧画面から記事を選択し、編集画面でmutationを使って更新してから一覧画面に戻る、という操作。
gql`
mutation updatePost (input: $post) {
post {
id
category
body
}
}
`
その画面で必要となるクエリは既に一度取得しているし、編集した記事は mutation の返り値で自動的に更新しているので、一覧画面に再度戻った際にはGraphQLにアクセスする必要がありません。
ところが、この時のmutationで指定していない値はクライアントから呼び出されないので、一覧画面に戻った時に「mutationで更新した後の内容が反映されているキー」と「mutationで更新する前に取得した内容のままになっているキー」が混在する可能性があります。
(後から取得したデータに足りない値がある場合、デフォルトでキャッシュとマージする挙動なので、消えるわけではありません)
これを判断できないのではないか、という問題です。
「mutationは更新操作なのでその操作によって変更された値は全て取得しに行くべき」という考え方なのかもしれませんが、
その数が個人ブログ程度ならともかく、一度の操作で編集される値が20個以上あるような場面では漏れが生じそうですし、
「どのプロパティに影響する操作か」を人為的に判断するのは、バグの温床になりかねず、将来的な変更があった時に更新し忘れていても自動的に気づくことができません。
mutationならまだしも、query同士だと「ページAでは税込金額を使うがページBでは税抜金額しか使わない」みたいな場面で、取得する順番によって税込と税抜がズレてしまうのではないかと思います。
確かに便利ではあるけど…
上に挙げた問題を確実に回避する方法として自分が現在行っているのは、同じデータモデルに対するquery・mutationでは常に全ての値を取得しに行くことです。
常に全てのキーを指定すれば、自動生成された型をそのまま当てはめて使うことができるし、queryによって差分が生まれることもありません。
……しかしこの使い方だと、書き方が違うだけでやっていることはほぼREST APIです。
Apollo Clientは確かにとても便利だし、この使い方であってもREST APIの上位互換的なパワーは感じられているのですが、
Apollo Clientを活かそうとするとGraphQLである必要がなく、GraphQLを活かすならApollo Clientを使わない方が良いのではないか、と思い始めています。
サーバーサイドでいちいちエンドポイントを分ける必要がないので開発効率が上がる、という文脈であれば理解できますが、
「必要な値だけを取って来れるので通信を高速化できる」という利点については、実際にそれを活かしている人は本当にいるのだろうか? というのが疑問です。
皆さんそこは割り切って使っているのでしょうか。それともVue ApolloじゃなくてReactならこんな問題は起きないのでしょうか……?
とにかく何かを見落としているのではないか、GraphQLの真の力を引き出せていないのではないかという気がしてならないので、より良い使い方をご存知の方がいたらぜひ教えて頂ければと思います。詳しい方のコメントお待ちしています。
Discussion
Apollo Clientの問題ではなさそうです。
型生成を担っているのは graphql-codegen であり、codegenにQueryを読み込ませてないので型が生成されません。
codegenを使う場合
と直接gqlを書くことはないかと思います。
.graphql ファイルにQueryを作成しcodegen経由で生成された関数を扱う形になります。
詳しい扱い方は公式や記事がたくさん上がっていると思うのでそちらを参考にされてください。
ありがとうございます!
なるほど、
.graphqlのschemaファイルはサーバーサイドで作ったファイルをそのまま読み込ませるためのものだと思っていたので、.graphqlファイルをクライアントサイドで別に作るのは完全に盲点でした…。サーバー側(例えば
graphql-ruby)で生成したSchemaファイルはあくまでドキュメントとして参考にするだけで、TypeScriptでは読み込まない、という理解で合っているでしょうか?ありがとうございます。
codegenで
を参照し型ファイルとして生成しています。
graphql-ruby側で query_type を書く.graphql内に query を書くusePostsQuery()要約するとバックとフロントでそれぞれ書く必要がありますね。
私が使っている例で恐縮ですが、Rails(graphql-ruby)を使ってる際のcodegenの設定のサンプルです。
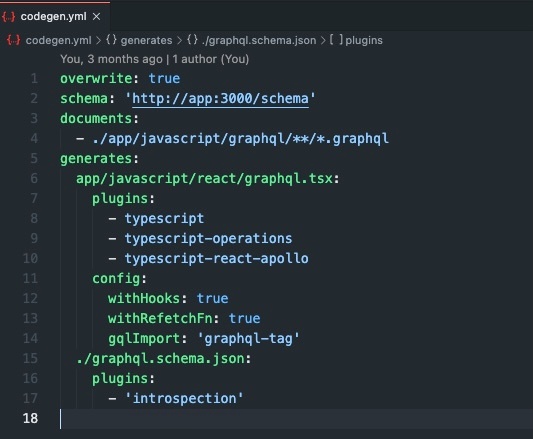
コード例までありがとうございます。
サーバー側の定義は
schemaとして読み込んだ上で、documentsにqueryやmutationを書いたファイルを別で指定すれば、queryやmutationとして使う関数まで自動生成できるのですね、ようやく理解できました! (というか公式ドキュメントをちゃんと読めば使い方も書いてありますね、すみません……。)Vue Apolloに適宜読み替えながら、クライアント側で直接
gqlを書いたりわざわざuseQueryuseMutationを呼び出していたところを無事に全部置き換えることができました。GraphQLの便利さをようやく完全に体感できた気がします、本当にありがとうございました…!!