大規模言語モデルの圧縮技術BitNet
最近公開されたMicrosoftの研究チームによる、大規模言語モデルの計算コストを削減する研究が、その革新的な手法で業界内外から大きな注目を集めています。この研究に興味を持ち、その背後にある技術やアプローチを深く掘り下げてみることにしました。
記事:
-
Microsoftが1.58ビットの大規模言語モデルをリリース、行列計算を足し算にできて計算コスト激減へ
https://gigazine.net/news/20240229-microsoft-1bit-llm/ -
1ビットLLMの衝撃! 70Bで8.9倍高速 全ての推論を加算のみで!GPU不要になる可能性も
https://wirelesswire.jp/2024/02/86094/
論文:
- Hongyu Wang et al.: BitNet: Scaling 1-bit Transformers for Large Language Models, arXiv:2310.11453
https://arxiv.org/abs/2310.11453 - Shuming Ma et al.: The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits, arXiv.2402.17764
https://arxiv.org/abs/2402.17764
背景
大規模言語モデルの進化に伴い、その巨大なモデルサイズが新たな課題として現れています。たとえば、GPT-4では5000億から1兆のパラメータが使用され、その前のバージョンであるGPT-3.5では約3550億のパラメータが使用されていました。さらに、MetaのLLaMaモデルは70億から650億のパラメータを用いています。
これらの大規模モデルを運用するには、高性能な計算資源が必要であり、推論プロセスは時間がかかり、消費電力も増加します。これが、大規模言語モデルの適用範囲を制限する一因となっています。
このモデルサイズの問題に対処するために、モデルパラメータを圧縮してメモリ使用量と計算コストを削減しつつ、推論精度を保持する研究が進められています。
2つの研究の方向性: post-trainingとquantization-aware training
モデルパラメータの圧縮に関する研究には、主に2つのアプローチが存在します。
第一のアプローチは、学習が完了した後にパラメータを離散化して圧縮する手法です。この手法は「post-training」として知られ、そのシンプルさから実装が容易な利点があります。しかし、学習過程で圧縮を考慮していないため、推論精度の低下が懸念されます。
第二のアプローチは、学習プロセス中にパラメータを圧縮することで、圧縮された状態での学習を可能にする手法です。この手法は「quantization-aware training」と呼ばれ、post-trainingに比べて推論精度が向上することが特徴です。しかし、モデルサイズを小さくするほど、高精度を実現するためのパラメータの最適化がより困難になるという課題があります。
手法の解説
BitNetの基本的なアイデアは、TransformerのAttention機構に入力と重みを離散化するBitLinearを導入することです。TransformerのAttention機構では、入力が3つのLinear Layerを通じてそれぞれ異なる出力Q、K、Vに変換されます。一方、BitNetでは、これらのLinear Layerに代えてBitLinearを利用します。

重み行列の圧縮
BitLinear(論文[1])では、重み行列
ここで、
そして、
により計算されます。この方法により、重みの各要素を+1と-1の二値に変換します。
入力行列の圧縮
入力行列
具体的には、
ここで、
とし、
上記の計算により得られた
論文[2]では、
結果
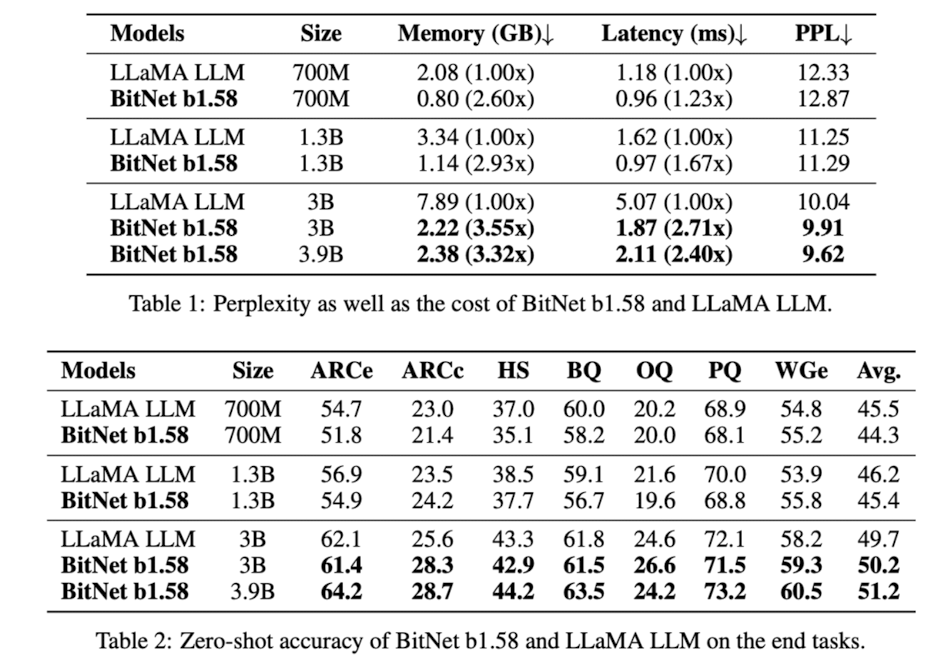
LLaMAとの精度比較では、ほとんどのデータセット上でLLaMAと同等かそれをわずかに上回る精度を達成しており、メモリ効率やレイテンシーの面では顕著な有効性を示しています。


Discussion