Google Prompt Engineering を読む
原文
これを読んで雑に日本語のメモを残していく。
Introduction
Yout don't need to be a data scientist or a machine learning engineer - everyone can write a prompt.
データサイエンティストやMLエンジニアになる必要はない。みんなプロンプトをかける。
however this
whitepaper focuses on writing prompts for the Gemini model within Vertex AI or by using
the API, because by prompting the model directly you will have access to the configuration
such as temperature etc.
ここではGeminiやVertex AIについてのpromptingについて論じる。理由は、モデルによって最適なPromptは異なってくるから。
Prompt engineering
それ以前に自分がやりたいことに対する最適なモデルを選ぶことからプロンプトエンジニアリングは始まっている。
モデルを選択したら、モデルの構成を理解する必要がある。最適なプロンプトエンジニアリングのためには最適なLLM構成を設定する必要がある。
Temperaturesが低ければ決定的なアウトプットを出力し、高ければランダム性の高いアウトプットを出力する。
Prompting techniques
General prompting / zero shot
zero shotは最もシンプルなプロンプトだ。それはLLMが考えるための最初の指示を与えるものに過ぎない。zero shotがうまく機能しない場合、デモや例を追加で与えるのが良い。これは“one-shot”や “few-shot” プロンプトと言われるものである。
One-shot & few-shot
AI Modelに対するプロンプトを作るとき、例を提供すると効果的だ。これらの例はモデルがあなたの訪ねていることを理解するのに役立つ。
one-shot promptは一つの例、few-shotはいくつか少数の例を提供するものである。
System, contextual and role prompting
System, contextual and role prompting はLLMにテキストを生成させるための用いられる手法だが、それぞれに異なる側面がある。
System Prompting
モデルが行うべき全体像を定義する。
Contextual Prompting
現在の会話またはタスクの背景を伝える
Role prompting
モデルに役割を与え、それに関連する知識と行動を出力するように伝える
Step-back prompting
Step-back8 prompting is a technique for improving the performance by prompting the LLM
to first consider a general question related to the specific task at hand, and then feeding the
answer to that general question into a subsequent prompt for the specific task. This ‘step
back’ allows the LLM to activate relevant background knowledge and reasoning processes
before attempting to solve the specific problem.
ステップバック8プロンプトは、LLMにまず特定のタスクに関連する一般的な質問を検討させ、次にその一般的な質問への回答を特定のタスクのための後続のプロンプトに入力させることで、パフォーマンスを向上させる手法。
この「ステップバック」により、LLMは特定の問題の解決を試みる前に、関連する背景知識と推論プロセスを活性化することができる。
It can help to mitigate biases in LLM responses, by focusing on general principles instead of
specific details, step-back prompting.
具体的な詳細ではなく、一般的な原則に焦点を当て、一歩引いたプロンプトを出すことで、LLMの回答におけるバイアスを軽減するのに役立つ。
ここには引いてきてないけど、元文章ではシューティングゲームの新しいシナリオに関して一般的な原則をLLMに聞いた上で、今回欲しいシナリオをそれに基づかせて引き出そうとしている。
Chain of Thought (CoT)
Chain of Thought (CoT) 9 prompting is a technique for improving the reasoning capabilities
of LLMs by generating intermediate reasoning steps. This helps the LLM generate more
accurate answers.You can combine it with few-shot prompting to get better results on more
complex tasks that require reasoning before responding as it’s a challenge with a zero-shot
chain of thought.
中間的な推論ステップを生成することで、LLMの推論能力を向上させる手法。これはLLMにより正確な答えを生成させるのに役立つ。回答前に推論が必要となるより複雑なタスクでは、これをfew-shot promptingと組み合わせることで、より良い結果を得ることができる。
これは労力がかからない割に効果的な手法。ただしデメリットもある。
The LLM response includes the chain of thought reasoning, which means more output
tokens, which means predictions cost more money and take longer.
より多くの出力を必要とすることから、より多くの時間と費用がかかる。
Prompt Example
When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step
by step.
Output Example
1. Let’s assume my current age is “x” years.
2. When I was 3 years old, my age was 3 years.
3. My partner’s age at that time was 3 times my age, which means my partner’s
age was 3 * 3 = 9 years.
4. Now, I am 20 years old, which means my age has increased by 20 - 3 = 17
years since I was 3 years old.
5. Since my partner’s age was 9 years when I was 3 years old, and my age has
increased by 17 years, my partner’s age must have also increased by 17 years.
6. Therefore, my partner’s current age is 9 + 17 = 26 years.
So, my partner is 26 years old.
ちなみに段階的に考えさせる前は63歳とかいう馬鹿げた答えを返してくる。
ここの例はzoro-shotと言われるものだが、次の例のようにfew-shotに改善することでLLMの出力量を減らすことができる。
Prompt Example
Q: When my brother was 2 years old, I was double his age. Now
I am 40 years old. How old is my brother? Let's think step
by step.
A: When my brother was 2 years, I was 2 * 2 = 4 years old.
That's an age difference of 2 years and I am older. Now I am 40
years old, so my brother is 40 - 2 = 38 years old. The answer
is 38.
Q: When I was 3 years old, my partner was 3 times my age. Now,
I am 20 years old. How old is my partner? Let's think step
by step.
A:
つまり自分達の方で段階的に誘導していってるわけですよと。なるほどなぁ
余談だけど面白いなと思った話
As a matter of fact, LLMs often struggle with
mathematical tasks and can provide incorrect answers – even for a task as simple as
multiplying two numbers. This is because they are trained on large volumes of text and math
may require a different approach
Self-consistency
Self-consistency11 combines
sampling and majority voting to generate diverse reasoning paths and select the most
consistent answer
Self-consistencyはサンプリングと多数決を組み合わせて多様な推論経路を生成し、最も一貫性のある答えを選択する。
It follows the following steps:
Generating diverse reasoning paths: The LLM is provided with the same prompt multipletimes. A high temperature setting encourages the model to generate different reasoning
paths and perspectives on the problem.
2. Extract the answer from each generated response.
3. Choose the most common answer.
Tree of Thoughts
CoTとself-concistency promptingを一般化したもの。これによりLLMは単一の直線的な思考の連鎖をたどるのではなく、複数の異なる推論経路を同時に探索できるようになる。
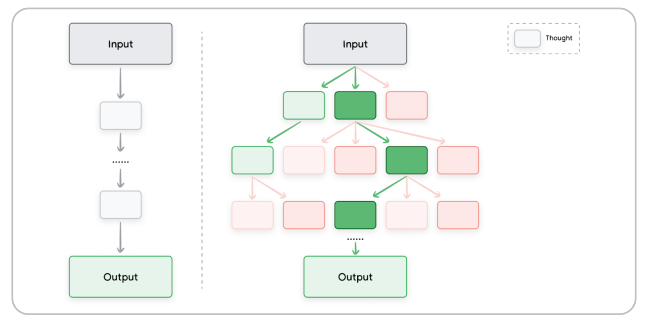
これはサンプルpromptが載ってない。けど意味はなんとなくわかる。CoFしつつself-concistency promptingすることで複数の出力を繋げながらLLMに考えさせられるってことを言ってるらしい。その結果が上の図に現れていると読める。
今日はここまで。明日はCode promptingから読んでいく。
Code prompting
Prompts for writing code
プロンプトの機密性を重視する場合はGoogle Acountに紐づいたVertex AI Studioで書く方が良い。Vertex AI StudioはTemperatureの設定も可能。
ただしLLMはトレーニングデータを推論して繰り返すことができないため、生成されたコードは毎度テストする必要がある。(同じものを作ってもらうにしても)
Prompts for explaining code
特に目新しいことはなし。コードを説明してもらうのにも使えるよってだけ。
Prompts for translating code
ここも特に新しいことはなし。サンプルではbashで生成されたファイル名変更のためのスクリプトをPythonに翻訳してもらっている。
Prompts for debugging and reviewing code
これも特に新しいことはない。エラーが出た時にエラーを渡してLLMに直してもらうっていう話。
Best Practices
Provide examples
ベストなプラクティスはプロンプト内に例を提供すること。
Design with simplicity
モデルも自分も簡潔で明確で簡単に理解できるプロンプトであること。
BEFORE:
I am visiting New York right now, and I'd like to hear more about great
locations. I am with two 3 year old kids. Where should we go during
our vacation?
AFTER REWRITE:
Act as a travel guide for tourists. Describe great places to visit in
New York Manhattan with a 3 year old.
見てると、動詞を頭に持ってくるのがよいらしい。
Act, Analyze, Categorize, Classify, Contrast, Compare, Create, Describe, Define,
Evaluate, Extract, Find, Generate, Identify, List, Measure, Organize, Parse, Pick,
Predict, Provide, Rank, Recommend, Return, Retrieve, Rewrite, Select, Show, Sort,
Summarize, Translate, Write.
Be specific about the output
出力の内容を具体的に指示する。
DO:
Generate a 3 paragraph blog post about the top 5 video game consoles.
The blog post should be informative and engaging, and it should be
written in a conversational style.
DO NOT:
Generate a blog post about video game consoles.
Use Instructions over Constraints
制約よりも指示を使う。
指示(instructions) = 応答の望ましい形式、内容など、モデルがすべきことについてガイドするためのもの
制約(Constraints) = 制限や境界を設けるもの。モデルがすべきでないこと・避けるべきことについてガイドするためのもの。
重要なことが書かれている。
Growing research suggests that focusing on positive instructions in prompting can be more
effective than relying heavily on constraints
DO:
Generate a 1 paragraph blog post about the top 5 video game consoles.
Only discuss the console, the company who made it, the year, and total
sales.
DO NOT:
Generate a 1 paragraph blog post about the top 5 video game consoles.
Do not list video game names.
Experiment and iterate to test different combinations of instructions and constraints to find
what works best for your specific tasks, and document these.
異なる指示と施薬の組み合わせを試し、自分がやって欲しいことに最適なものを見つけそれを文書化する。
Control the max token length
LLMの出力は設定で変えるか明示的なプロンプトでコントロールすることができる。
Use variables in prompts
プロンプト内で変数を使う。これにより、再利用可能なプロンプトを作ることができる。
Experiment with input formats and writing styles
プロンプトの形式(zero shot, few shot)、ワードチョイス、モデルの設定を変えることで異なる出力になる。自分の目的に合った出力を得られるようこれらを変えてみる。
For few-shot prompting with classification tasks, mix up the classes
6つの例から始めていくのが経験則としてはよいと書かれている。
Adapt to model updates
見出し通りの意味。
Experiment with output formats
出力形式を様々試してみろといいながら、ここではJSONで出力させることが推奨されている。
Experiment together with other prompt engineers
見出しの通り。
CoT Best practices
the temperature should always set to 0.
Document the various prompt attempts
プロンプトの試行を詳細に文書化して、何がうまくいって何がうまくいかなかったのかを時間をかけて学ぶこと。
この文書で提供されている表21の内容をテンプレートとしてスプレッドシートを作ることを勧めている。

Prompt engineering is an iterative process. Craft and test different prompts, analyze,
and document the results. Refine your prompt based on the model’s performance. Keep
experimenting until you achieve the desired output. When you change a model or model
configuration, go back and keep experimenting with the previously used prompts.
プロンプトエンジニアリングは繰り返しです。作ってはテストを繰り返し、分析し、そして結果をドキュメントにする。モデルのパフォーマンスに基づいてプロンプトを洗練する。これを望ましい結果が得られるまで繰り返す。モデルもしくはモデル設定を変えた時は、また試行する。