Kotlin DataFrameを使えばCSVやJSONをいい感じに扱えそう

Kotlin DataFrame とは
JetBrains社純正のデータ操作ライブラリです。CSV,JSONなどをいい感じに扱えるようです。
ということで、この記事では手始めにCSVで検証してみようと思います。
導入
今回はKotlin DSLで検証を行うため、以下の設定をbuild.gradle.ktsに追加します。
dependencies {
implementation("org.jetbrains.kotlinx:dataframe:0.13.1")
}
あとはファイルを準備します。これはGitHubにサンプルを用意してくれているので、ありがたく使わせていただくことにします。
今回ファイルはプロジェクト直下に配置しておくことにします。
いろいろ試す
findAll
何はともあれ、まずはファイルを読み取って表示してみます。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.print
import org.jetbrains.kotlinx.dataframe.io.read
fun main(args: Array<String>) {
val df = DataFrame.read("titanic.csv", delimiter = ';')
df.print()
}
うまい具合に整形して表示されました。

select
射影を行うにはselectを使います。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.print
import org.jetbrains.kotlinx.dataframe.api.select
import org.jetbrains.kotlinx.dataframe.io.read
fun main(args: Array<String>) {
val df = DataFrame.read("titanic.csv", delimiter = ';')
df.select("pclass", "name", "sex").print()
}

またこのコードから、DataFrameはselectした結果として新しいDataFrameを返していることがわかりました。
filter
選択を行うにはfilterを使います。
filterの中で選択対象の列名またはインデックスを指定し、あとは適当に条件を書きます。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.filter
import org.jetbrains.kotlinx.dataframe.api.print
import org.jetbrains.kotlinx.dataframe.api.select
import org.jetbrains.kotlinx.dataframe.io.read
fun main(args: Array<String>) {
val df = DataFrame.read("titanic.csv", delimiter = ';')
df.select("pclass", "name", "sex")
.filter { it["sex"] == "male" }
.print()
}
sort
昇順ソートにはsortByを、降順ソートにはsortByDescを使います。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.print
import org.jetbrains.kotlinx.dataframe.api.select
import org.jetbrains.kotlinx.dataframe.api.sortBy
import org.jetbrains.kotlinx.dataframe.io.read
fun main(args: Array<String>) {
val df = DataFrame.read("titanic.csv", delimiter = ';')
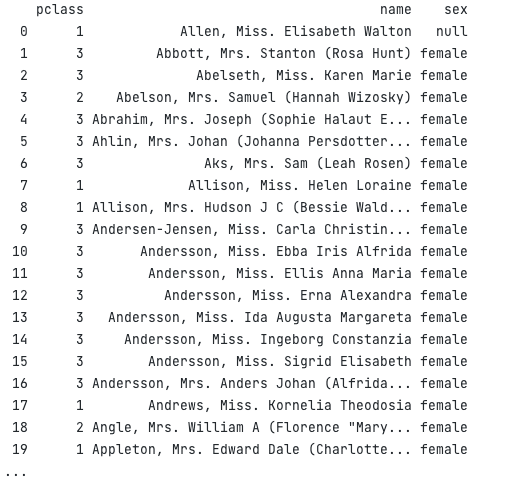
df.select("pclass", "name", "sex")
.sortBy("sex", "name")
.print()
}
grouping
集計にはgroupByやpivot、countなどを使います。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.*
import org.jetbrains.kotlinx.dataframe.io.read
fun main(args: Array<String>) {
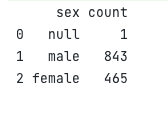
val df = DataFrame.read("titanic.csv", delimiter = ';')
df.groupBy("sex").count().print()
}
書き出し
メモリ上でいろいろと操作した結果をディスクに保存することも、writeXXXを利用することで可能です。
import org.jetbrains.kotlinx.dataframe.DataFrame
import org.jetbrains.kotlinx.dataframe.api.*
import org.jetbrains.kotlinx.dataframe.io.read
import org.jetbrains.kotlinx.dataframe.io.writeCSV
import java.io.File
fun main(args: Array<String>) {
val df = DataFrame.read("titanic.csv", delimiter = ';')
val outFile = File("selected_titanic.csv")
df.select("pclass", "name", "sex")
.sortBy("sex", "name")
.writeCSV(outFile)
}
デフォルトはカンマ区切りで出力してくれます。

おわりに
元のデータが1300行くらいだったのですが、その程度であれば単純な読み込みや集計であれば体感かなり高速にレスポンスがきました。
プロダクトで採用するのを抜きにしても、簡単なツールでCSVを扱いたいときなどにはうってつけかもしれません。
Exposedを使ってるのならばなおさらで、ソレと近い記述感でデータを扱うことができました。
一方でJSONに対する操作については、入れ子があったりするのでもう少し工夫が必要そうです。
そっちの詳細については、JetBrainsのブログに記載されておりますのでぜひご参照ください。
📢 Kobe.tsというTypeScriptコミュニティを主催しています
フロント・バックエンドに限らず、周辺知識も含めてTypeScriptの勉強会を主催しています。
毎朝オフラインでもくもくしたり、神戸を中心に関西でLTもしています。
盛り上がってる感を出していきたいので、良ければメンバーにだけでもなってください😣
Discussion