Intelligent Speech Interactionを使う
前回はCosyVoice 2を試しました。
本記事ではAlibaba Cloudが提供しているサービスの1つであるIntelligent Speech Interactionを使ってみたいと思います。
Intelligent Speech Interactionで何ができるのか
おおまかには音声認識、音声合成、自然言語理解などの最先端の技術に基づいており、次の機能が提供されています。
- リアルタイム音声認識: 音声データストリームをリアルタイムでテキストに変換
- 短文認識: 音声検索、音声コマンド入力、ショートメッセージなど向けの短い音声テキスト変換
- 録音ファイル認識: ユーザーがアップロードした音声ファイルをテキストに変換
- 音声合成: 最大100,000文字までのテキストを自然な音声に変換(さまざまな話者、発話速度、イントネーション、音量などの調整が可能)
- 自己学習型プラットフォーム: ユースケースに合わせた認識精度の向上のためのモデルカスタマイズ機能
また、上記は多言語対応で、順次その他の言語も追加されていく予定だそうです。
- 中国語
- 広東語
- 英語
- 日本語
- 韓国語
- フランス語
- インドネシア語
特徴としては高い認識精度と処理速度、多種多様な業界向けに利用できる製品設計である点などメリットが多そうです。
実際に使ってみる
前回CosyVoice 2を試したときはTTS(Text-to-Speech)を試しました。ここでもTTSを使ってみたいと思います。
Intelligent Speech Interactionへアクセスする
次のURLからアクセスできます
https://nls-portal.console.aliyun.com
未アクティベートであるメッセージが表示されるので迷わずActivate Nowをクリックします。

Activate Nowをクリック

サービスが有効化されました。

日本語ページはまだ工事中だそうで、表示言語をENに切り替えました。

プロジェクトを作成する
サイドバーからプロジェクトへ飛び、

新しいプロジェクトを作成します。
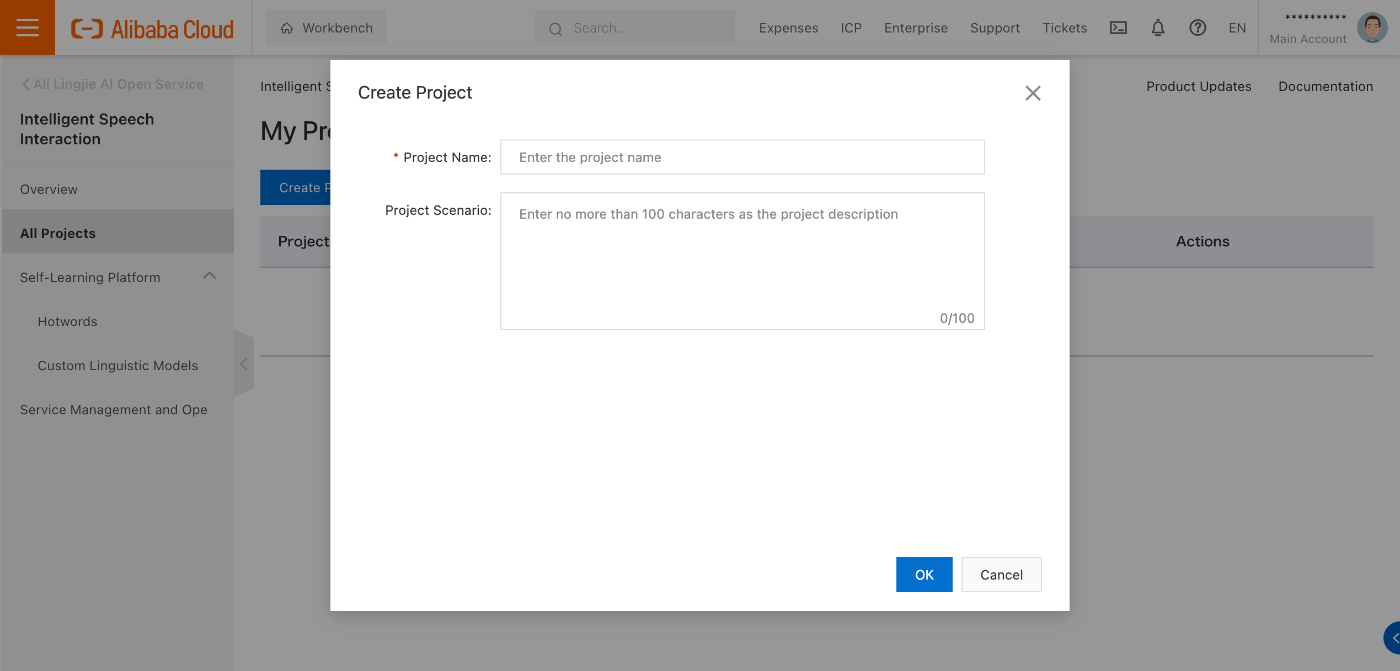
ここで表示されるAppkeyはAPIアクセス時に指定する値です(今回はAlibaba Cloudコンソール内で試すだけなので不必要ですがマスクしています)。
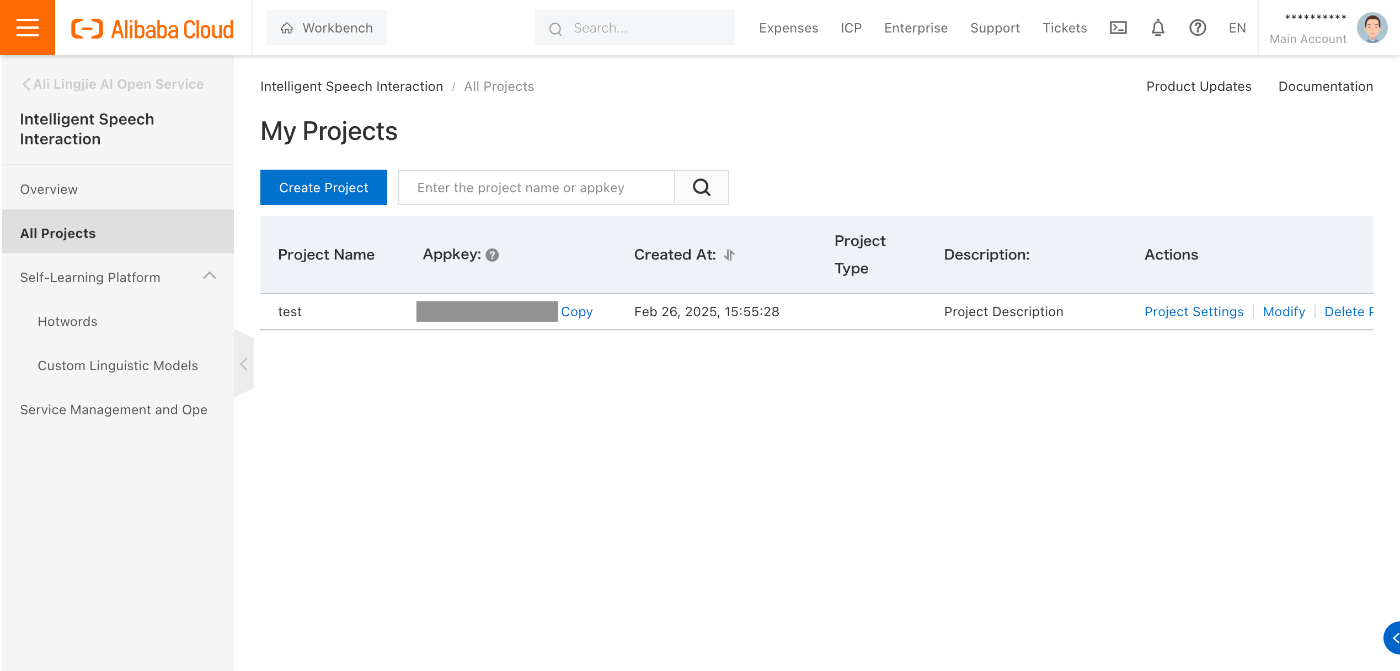
プロジェクト設定ページへアクセスする
早速読み上げを試せそうな……

まずはモデルを選択しないといけないようです。

※注: ページの表示言語が日本語設定の場合、カテゴリ名やモデル名・説明が表示されないので注意(2025年2月現在)。
多言語のモデルを選択し、テキストを入力してスピーカーボタンを押すだけで即座に生成された音声が再生されます。簡単!
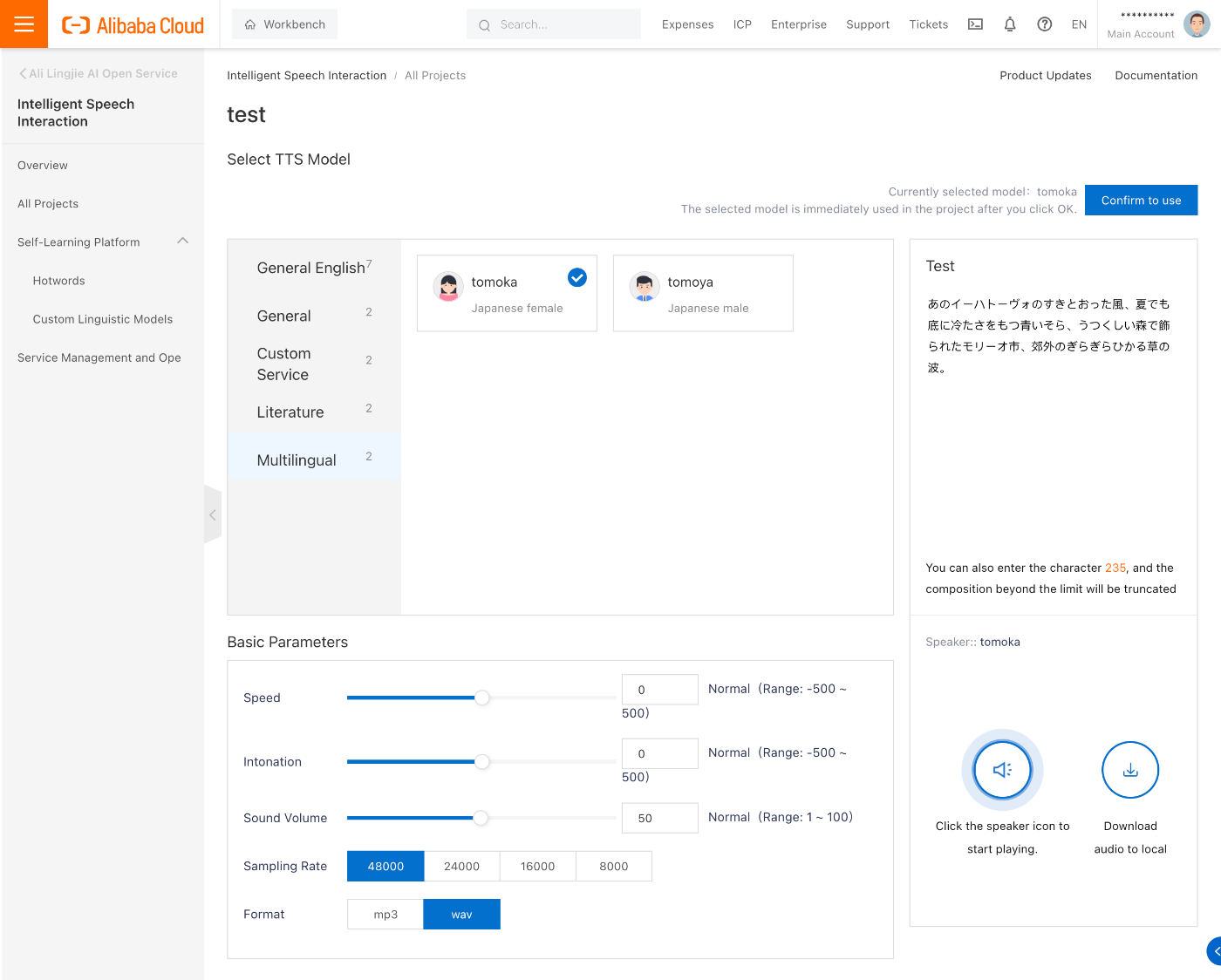
パラメーターパネル
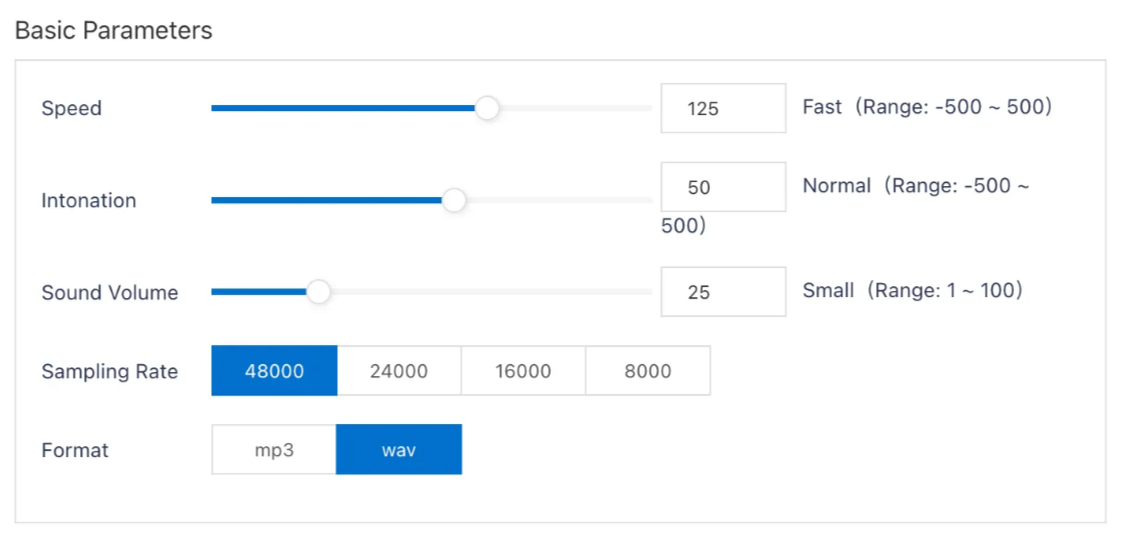
聞き取りやすさなどを確認しながら調整することができます。
思ったよりも簡単に試せてしまいました。
このサービス内でもおそらくCosyVoiceが使われていると思われるのですが、どうやらユーザーがアップロードした音声をもとに喋らせることはまだできないようです。
当然ながらAPIの仕様やSDKも提供されているので、自分たちのアプリケーションへ音声機能を組み込むことが気軽にできる良いサービスだと思いました。
Discussion