自己紹介
ユアスタンド株式会社のプロダクトマネージャー、髙原と申します。
企画趣旨
生成AIを使ったサービス開発を題材に100日連続で記事を書こうシリーズ13日目。
これは2025/06/03ぶんの記事です。
今回の取り組み
全3回[1]に分けて、Cursorで開発した自作の音声通話サービスを紹介します。
今回は3回目、いよいよ最後です。
ミウラニュアン

アーキテクチャ
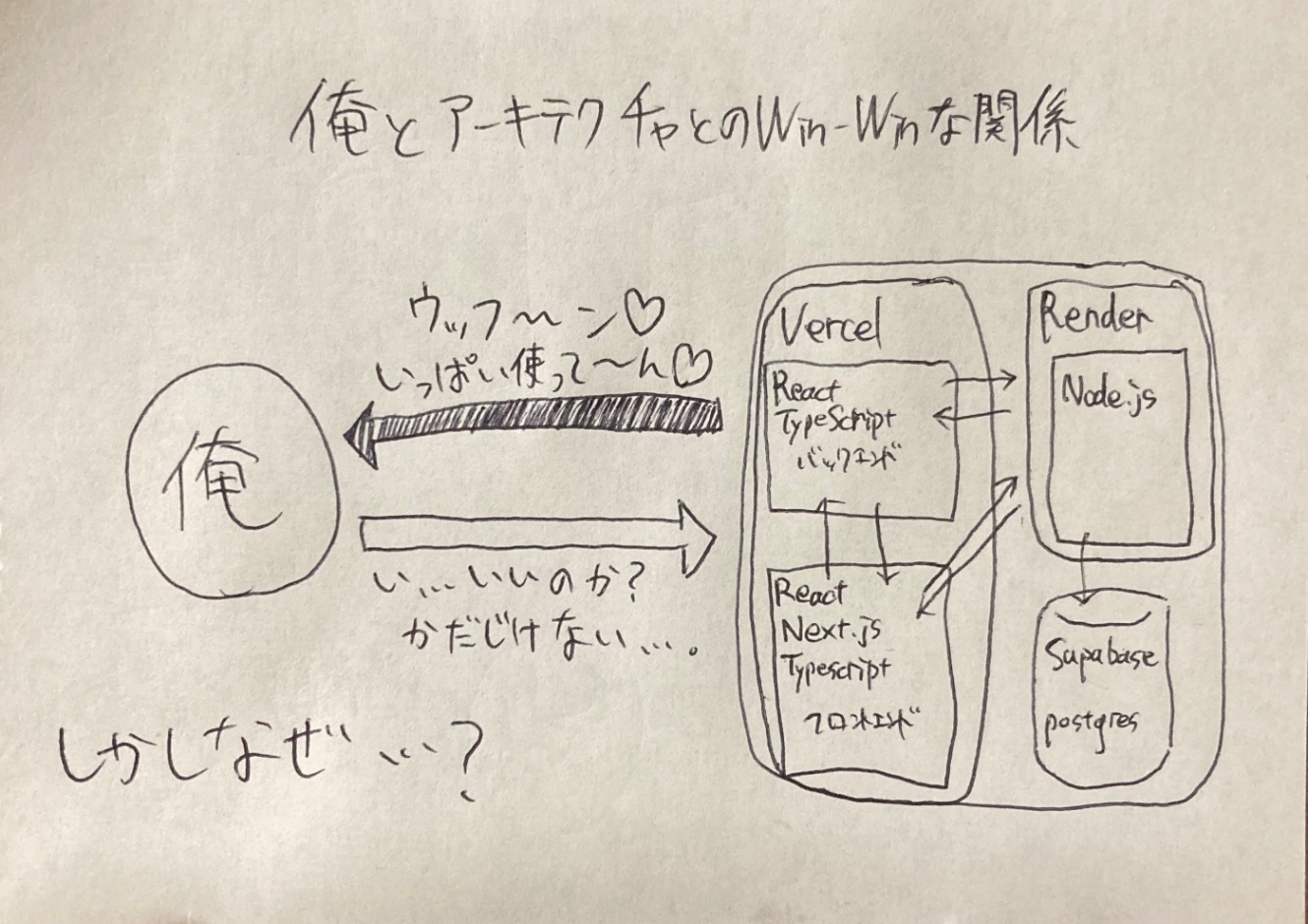
1.Vercel
言わずと知れたホスティングサービス。GitHubを連携するだけでデプロイしてくれます。
1-1.React + Next.js
今回初めてReact、並びにNext.jsに触れました。(ProviderやuseEffectの習得は骨が折れた)
フロントエンドとバックエンドの両方をVercelにホスティングしています。
1ファイルにロジックとフロントエンドを混在させるため、コンポーネント分割などのリファクタリングがしんどかったです。
1-2.WebRTC
特にライブラリなど入れずに生(?)で実装しました。
後述のシグナリングサーバーとの通信用にWebSocketを使っています。
OfferとAnswerの扱い方を今回完全に理解しました。
1-3.TailwindCSS
ビルトインされているCSSクラスが非常に強力なフレームワーク。
しかも実際に使われているクラスしか出力しないので比較的軽量らしい。
1-4.Web Speech API
ブラウザにビルトインされている音声認識のクラス SpeechRecognition()を使っています。
止めたいときに止まらない、再開したいときに再開しない、そんな扱いにくさを感じることも。でもなかなかの精度。
1-5.Web Audio API
ブラウザにビルトインされている音声操作のAPI群です。
ミウラニュアンのトップ画面ではいきなりマイクの入力ONを求められますが、このときマイクの音声を無数のバーで表現しています。
またルーム画面のボイスチェンジャーもこちらで実装しています。
2.Render
サーバーロジックのホスティングサービス。
Node.js製のサーバーを立てています。(WebRTCにおけるシグナリングサーバー)
ちなみにルーム情報はこのサーバーのメモリだけで管理しています。
無料プランでは5分間アクセスが無いとサーバーが停止されてしまう。仕方ないね
3.Supabase
データベースSaas。
会話履歴をログとして記録しています。
次回
こだわり解説編をお送りします。(3回で終わらなかった…)
-
概要と経緯編、使い方ガイド編、アーキテクチャやこだわり解説編、を予定しています。 ↩︎

Discussion