Kria Robotics Stack(ROS2をFPGAで高速化)



はじめに
前回、Kria Robotics Stack を使ってFPGAでROS2を動かしてみましたが、処理性能がCPUよりも遅い結果となってしまいました。
今回は、FPGAでROS2をどのように最適化してくのかを見ていこうと思います。
データフロー最適化
今回もvaddを使って色々と確認していきます。
void vadd(
const unsigned int *in1, // Read-Only Vector 1
const unsigned int *in2, // Read-Only Vector 2
unsigned int *out, // Output Result
int size // Size in integer
)
簡単に説明すると、高位合成したvaddをFPGAにオフロードし、CPUからFPGAにin1とin2のデータを渡し、処理結果outを受け取るという構成になります。
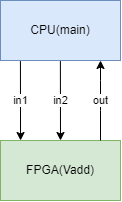
これまで試してきたケースにおけるデータ受け渡しのタイミングは以下の図の様になります。

これをin1、in2をそれぞれ個別のポートを準備して並列でデータ転送するように最適化をしてみます。イメージ的には以下の様になるのでデータ転送時間が短くなるはずです。

データ転送ポートはHLSのINTERFACEプラグマで個別に指定可能です。
in1のポートをaximm1、in2のポートをaximm2として、個別にポートを指定します。
extern "C" {
void vadd(
const unsigned int *in1, // Read-Only Vector 1
const unsigned int *in2, // Read-Only Vector 2
unsigned int *out, // Output Result
int size // Size in integer
)
{
#pragma HLS INTERFACE m_axi port=in1 bundle=aximm1
#pragma HLS INTERFACE m_axi port=in2 bundle=aximm2
#pragma HLS INTERFACE m_axi port=out bundle=aximm1
for (int j = 0; j < size; ++j) { // stupidly iterate over
// it to generate load
#pragma HLS loop_tripcount min = c_size max = c_size
for (int i = 0; i < size; ++i) {
#pragma HLS loop_tripcount min = c_size max = c_size
out[i] = in1[i] + in2[i];
}
}
}
}
続いてこちらをビルドして動作確認をしていきます。
前回同様に以下を実行してSDカードイメージを作成してEtcherで書き込みます。
$ source /tools/Xilinx/Vitis/2021.2/settings64.sh
$ source /opt/ros/rolling/setup.bash
$ export PATH="/usr/bin":$PATH
$ colcon build --merge-install
$ source install/setup.bash
$ colcon acceleration select kv260
$ colcon build --build-base=build-kv260 --install-base=install-kv260 --merge-install --mixin kv260 --packages-select ament_acceleration ament_vitis vitis_common ros2acceleration accelerated_doublevadd_publisher
$ cd ~/krs_ws/build-kv260/accelerated_doublevadd_publisher
$ bootgen -arch zynqmp -image vadd_accelerated.bif -o ./package/BOOT.BIN
$ cd ~/krs_ws
$ colcon acceleration linux vanilla --install-dir install-kv260
SDカードをkv260ボードに差し込み電源を入れ、ターミナルから以下のコマンドを打ち込みます。
$ sudo su
$ source /usr/bin/ros_setup.bash
$ . /krs_ws/local_setup.bash
$ ros2 acceleration stop; ros2 acceleration start
$ ros2 acceleration list
$ ros2 acceleration select accelerated_doublevadd_publisher
$ cd /krs_ws/lib/accelerated_doublevadd_publisher
$ cp vadd_accelerated.xclbin vadd.xclbin
$ ros2 topic hz /vector_acceleration --window 10 &
$ ros2 run accelerated_doublevadd_publisher accelerated_doublevadd_publisher
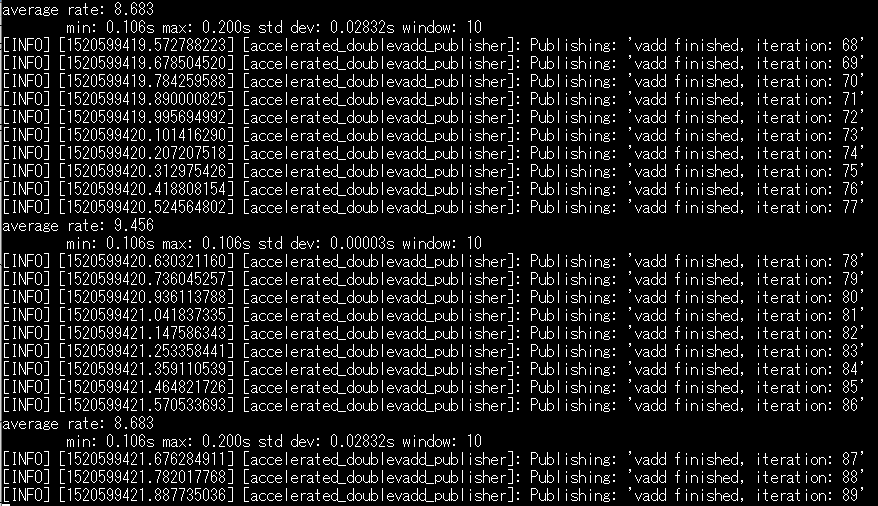
実行結果は以下の通りaverage_rate=8.6になりました。
プラグマを一か所指定するだけで、前回のaverage_rate=2.1から大きく性能改善できていることが分かります。
データ並列演算
次は演算処理の高速化に着目してみます。
これまで同一クロックサイクル辺り1個の加算だけだったのを、ループを展開して同一クロックサイクル内で16個同時に加算実行するように変更してみます。

CPUからFPGAに送るデータは1データ辺り4バイト(32ビット)なので、これを16並列にした場合だと合計512ビットのデータを同時に扱うことになります。
m_axiポートの帯域が512ビットなので、同時に16個のデータ転送が一番効率が良いのでこのようにしています。
この場合のHLSコードを見てみます。
extern "C" {
void vadd(
const unsigned int *in1, // Read-Only Vector 1
const unsigned int *in2, // Read-Only Vector 2
unsigned int *out, // Output Result
int size // Size in integer
)
{
#pragma HLS INTERFACE m_axi port=in1 bundle=aximm1
#pragma HLS INTERFACE m_axi port=in2 bundle=aximm2
#pragma HLS INTERFACE m_axi port=out bundle=aximm1
for (int j = 0; j <size; ++j) { // stupidly iterate over
// it to generate load
#pragma HLS loop_tripcount min = c_size max = c_size
for (int i = 0; i<(size/16)*16; ++i) {
#pragma HLS UNROLL factor=16
#pragma HLS loop_tripcount min = c_size max = c_size
out[i] = in1[i] + in2[i];
}
}
}
}
HLSのUNROLLプラグマで16並列でループアンロールを指定します。
こちらについてもビルドして動作確認をしていきます。
前回同様に以下を実行してSDカードイメージを作成してEtcherで書き込みます。
$ source /tools/Xilinx/Vitis/2021.2/settings64.sh
$ source /opt/ros/rolling/setup.bash
$ export PATH="/usr/bin":$PATH
$ colcon build --merge-install
$ source install/setup.bash
$ colcon acceleration select kv260
$ colcon build --build-base=build-kv260 --install-base=install-kv260 --merge-install --mixin kv260 --packages-select ament_acceleration ament_vitis vitis_common ros2acceleration tracetools_acceleration faster_doublevadd_publisher
$ cd ~/krs_ws/build-kv260/faster_doublevadd_publisher
$ bootgen -arch zynqmp -image vadd_faster.bif -o ./package/BOOT.BIN
$ cd ~/krs_ws
$ colcon acceleration linux vanilla --install-dir install-kv260
SDカードをkv260ボードに差し込み電源を入れ、ターミナルから以下のコマンドを打ち込みます。
$ sudo su
$ source /usr/bin/ros_setup.bash
$ . /krs_ws/local_setup.bash
$ ros2 acceleration stop; ros2 acceleration start
$ ros2 acceleration list
$ ros2 acceleration select faster_doublevadd_publisher
$ cd /krs_ws/lib/faster_doublevadd_publisher/
$ cp vadd_faster.xclbin vadd.xclbin
$ ros2 topic hz /vector_acceleration --window 10 &
$ ros2 run faster_doublevadd_publisher faster_doublevadd_publisher
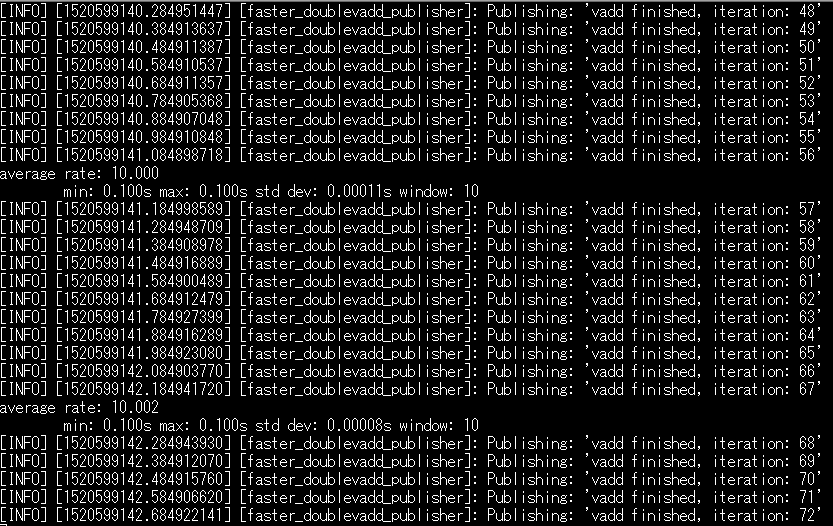
実行結果は以下の通りaverage_rate=10になり、更に性能が改善しています。
おわりに
今回はFPGAにオフロードするROS2プログラムの処理速度の改善について見ていきました。
速度改善の肝はHLSによる最適化にあるようです。
ただしHLSはプラグマを追加するだけで最適化ができるので、FPGAが解らない人にとっても馴染みやすくコーディングできるのではないでしょうか。
Discussion