【Python】実践データ分析100本ノック 第10章
この記事は、現場で即戦力として活躍することを目指して作られた現場のデータ分析の実践書である「Python 実践データ分析 100本ノック(秀和システム社)」で学んだことをまとめています。
ただし、本を参考にして自分なりに構成などを変更している部分が多々あるため、ご注意ください。細かい解説などは是非本をお手に取って読まれてください。

【リンク紹介】
・【一覧】Python実践データ分析100本ノック
・これまで書いたシリーズ記事一覧
目的
文章から必要な情報を取得する手法、取得した情報から特徴量を算出してデータ分析を行うための数値化を行う手法等を学ぶ
Import
# 必要に応じてインストールを行う
# テキストでは以下の入力が書かれていたが、自分の環境ではエラーとなった
# !pip install mecab-python3 unidic-lite
!pip install --upgrade pip
!pip3 install mecab-python3 unidic-lite
%%time
import numpy as np
import pandas as pd
from gc import collect # ガーベッジコレクション
from colorama import Fore, Style, init # Pythonの文字色指定ライブラリ
from IPython.display import display_html, clear_output
import matplotlib.pyplot as plt
%matplotlib inline
import MeCab # 形態素解析
%%time
# テキスト出力の設定
def PrintColor(text:str, color = Fore.GREEN, style = Style.BRIGHT):
print(style + color + text + Style.RESET_ALL);
# displayの表示設定
pd.set_option('display.max_columns', 50);
pd.set_option('display.max_rows', 50);
print()
collect()
Knock91:データを読み込んで把握する
不動産企業が実施したアンケートを分析していきます。まずはキャンペーン期間で集めた顧客満足度アンケートを読み込みます。
%%time
"""データ読み込み"""
# 2019年1月から4月に集めた顧客満足度アンケートのデータ
survey = pd.read_csv('survey.csv')
"""読み込んだデータを確認"""
PrintColor(f'\n len(survey): {len(survey)}')
PrintColor(f'\n survey:2019年1月~4月に集めた顧客満足度アンケート')
display(survey.head())
print()
collect()
%%time
"""欠損値の確認"""
PrintColor(f'\n 欠損値の確認')
display(survey.isna().sum())
print()
collect()
%%time
"""欠損値の除去"""
survey = survey.dropna()
PrintColor(f'\n 欠損値処理後の確認')
display(survey.isna().sum())
print()
collect()
Knock92:不要な文字を除去する
【Python】実践データ分析100本ノック 第2章のKnock16のときと同様にreplace()関数を用いて、不要な文字を削除していきます。
%%time
# テキストでは試しにAAを消すために記述されているが、実際括弧とまとめて削除されるため、なくてもよい
#survey['comment'] = survey['comment'].str.replace('AA', '')
survey['comment'] = survey['comment'].str.replace('\(.+?\)', '', regex = True) # 半角括弧
survey['comment'] = survey['comment'].str.replace('\(.+?\)', '', regex = True) # 全角括弧
PrintColor(f'\n survey:不要な文字を削除')
display(survey.head())
print()
collect()
Knock93:文字数をカウントしてヒストグラムを表示する
%%time
survey['length'] = survey['comment'].str.len()
PrintColor(f'\n survey')
display(survey.head())
print()
collect()
%%time
"""アンケートのコメントの文字数をヒストグラムで表示"""
plt.hist(survey['length'],
bins = 20,
rwidth = 0.9,
color = '#47845E', # 緑青色
)
plt.xlabel('word count')
plt.ylabel('count')
# グラフを保存
plt.savefig('Knock93.png')
plt.show()
print()
collect()
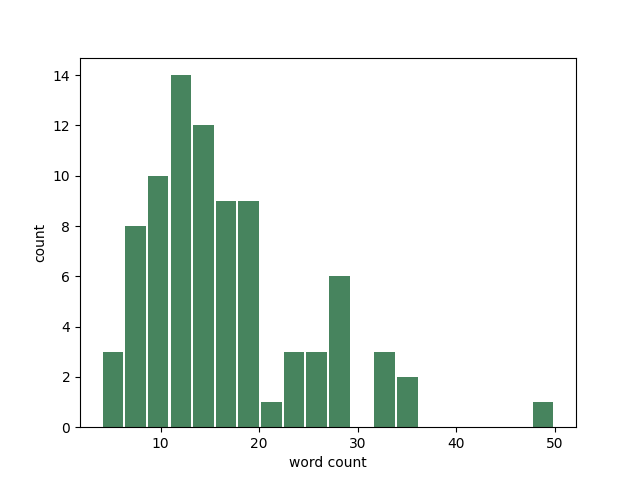
ヒスとグラム参考資料
Knock94:形態素解析で文章を分割する
MeCabを用いて形態素解析を行います。まずは簡単な例文で使用方法を確認します。
なお、MeCabについては以下を参考にしました。
%%time
# Taggerクラスをインスタンス化
tagger = MeCab.Tagger()
text = 'すもももももももものうち'
"""形態素解析の実行"""
words = tagger.parse(text)
"""解析結果の確認"""
display(words)
print()
collect()
%%time
"""形態素解析の実行(単語ごとに区切る)"""
words = tagger.parse(text).splitlines()
"""解析結果の確認"""
display(words)
print()
collect()
%%time
"""分割した単語のみを抽出する"""
# 単語の格納リストの作成
words_arr = []
for i in words:
if i == 'EOS' :
continue # 今回はEOSの位置関係上、breakに置き換えても同じ結果となる
word_tmp = i.split()[0]
words_arr.append(word_tmp)
display(words_arr)
print()
collect()
Knock95:形態素解析で文章から「動詞・名詞」を抽出する
今度は動詞、名詞の単語のみを取得します。
%%time
text = 'すもももももももものうち'
"""形態素解析の実行"""
words = tagger.parse(text).splitlines()
"""分割した単語のみを抽出する"""
words_arr = []
parts = ['名詞', '動詞']
for i in words:
if i == 'EOS' or i == '':
continue
# 単語を格納
word_tmp = i.split()[0]
# 品詞項目を取り出す
part = i.split()[4].split('-')[0]
# partに格納した品詞が名詞ならリストに追加 ※注釈
if (part in parts):
words_arr.append(word_tmp)
display(words_arr)
print()
collect()
注釈
テキストでは、ここは次のように書かれています。
if not(part in parts): continue
words_arr.append(word_tmp)
つまり、if文の条件が「名詞や動詞でないなら」という否定条件となっています。必ずしも駄目であるわけではありませんが、今回のコードでは否定条件として記述ことに特別な要素もありませんので、わかりやすいように肯定条件文に書き直しました。
なお、この改善は
「リーダブルコード ―より良いコードを書くためのシンプルで実践的なテクニック (Theory in practice)」
を参考に行いました。興味のある方は是非お手に取ってみてください。
Knock96:形態素解析で抽出した頻出する名詞を確認する
使い方を確認したところで、今回のアンケート全体でどんな単語が含まれているかを把握します。
%%time
all_words = []
parts = ['名詞']
"""分割した単語のみを抽出する"""
for n in range(len(survey)):
text = survey['comment'].iloc[n]
words = tagger.parse(text).splitlines()
words_arr = []
for i in words:
if i == 'EOS' or i == '':
continue
# 単語を格納
word_tmp = i.split()[0]
if len(i.split()) >= 4:
# 品詞項目を取り出す
part = i.split()[4].split('-')[0]
# partに格納した品詞が名詞ならリストに追加
if (part in parts):
words_arr.append(word_tmp)
# リストを拡張する形で追加する
all_words.extend(words_arr)
display(all_words)
print()
collect()
append, extend, insertの違いについての参考資料
単語ごとに数えるために、データフレームに格納し、集計を行います。
%%time
"""データフレームの作成"""
all_words_df = pd.DataFrame({'words' : all_words,
'count' : len(all_words) * [1]
})
"""データフレームの確認"""
PrintColor(f'\n all_words_df')
display(all_words_df.head())
# 単語ごとにグループ分け
all_words_df = all_words_df.groupby('words').sum()
# count数の大きい順にソートして出力
PrintColor(f"\n all_words_df.sort_values('count', ascending = False)")
display(all_words_df.sort_values('count', ascending = False).head(20))
print()
collect()
Knock97:関係のない単語を除去する
%%time
stop_words = ['時'] # 除去ワード
all_words = []
parts = ['名詞']
for n in range(len(survey)):
text = survey['comment'].iloc[n]
"""形態素解析の実行"""
words = tagger.parse(text).splitlines()
words_arr = []
for i in words:
if i == 'EOS' or i == '':
continue
# 単語を格納
word_tmp = i.split()[0]
if len(i.split()) >= 4:
# 品詞項目を格納
part = i.split()[4].split('-')[0]
# もしstop_wordsに含まれているならスキップ
if word_tmp in stop_words:
continue
# もしpartに格納されている品詞が名詞ならリストに追加
if (part in parts):
words_arr.append(word_tmp)
# リストを拡張する形で追加する
all_words.extend(words_arr)
display(all_words)
print()
collect()
%%time
"""頻出単語を表示する"""
all_words_df = pd.DataFrame({'words' : all_words,
'count' : len(all_words) * [1]
})
all_words_df = all_words_df.groupby('words').sum()
display(all_words_df.sort_values('count', ascending = False).head(20))
print()
collect()
Knock98:顧客満足度と頻出単語の関係を見る
頻出単語と顧客満足度の関係を調べるために、comment列を取得し、形態素解析を行った単語と顧客満足度を紐づける必要があります。そこで、形態素解析と同時に顧客満足度を格納します。
%%time
stop_words = ['時'] # 除外ワード
parts = ['名詞']
all_words = []
satisfaction = [] # 顧客満足度
for n in range(len(survey)):
text = survey['comment'].iloc[n]
"""形態素解析を実行"""
words = tagger.parse(text).splitlines()
words_arr = []
for i in words:
if i == 'EOS' or i == '':
continue
# 単語を格納
word_tmp = i.split()[0]
if len(i.split()) >= 4:
# 品詞項目を格納
part = i.split()[4].split('-')[0]
# もしstop_wordsに含まれているならスキップ
if word_tmp in stop_words:
continue
# もしpartに格納されている品詞が名詞ならリストに追加
if (part in parts):
words_arr.append(word_tmp)
# 顧客満足度を追加
satisfaction.append(survey['satisfaction'].iloc[n])
# リストを拡張する形で追加する
all_words.extend(words_arr)
"""頻出単語を表示する"""
all_words_df = pd.DataFrame({'words' : all_words,
'satisfaction' : satisfaction,
'count' : len(all_words) * [1]
})
PrintColor(f'\n all_words')
display(all_words_df.head())
print()
collect()
%%time
"""顧客満足度の集計を行う"""
words_satisfaction = all_words_df.groupby('words').mean()['satisfaction']
words_count = all_words_df.groupby('words').sum()['count']
words_df = pd.concat([words_satisfaction, words_count], axis = 1)
"""集計データの確認"""
display(words_df.head())
print()
collect()
%%time
"""さらにcountが3以上のものに絞る"""
words_df = words_df.loc[words_df['count'] >= 3]
"""絞ったデータの確認"""
# 満足度に対して降順で表示
display(words_df.sort_values('satisfaction', ascending = False).head())
# 満足度に対して昇順で表示
display(words_df.sort_values('satisfaction').head())
print()
collect()
Knock99:アンケート毎の特徴を表現する
%%time
parts = ['名詞']
all_words_df = pd.DataFrame()
satisfaction = []
for n in range(len(survey)):
text = survey['comment'].iloc[n]
"""形態素解析を実行"""
words = tagger.parse(text).splitlines()
words_df = pd.DataFrame()
for i in words:
if i == 'EOS' or i == '':
continue
# 単語を格納
word_tmp = i.split()[0]
if len(i.split()) >= 4:
# 品詞項目を格納
part = i.split()[4].split('-')[0]
# partに名詞が格納されているなら追加
if (part in parts):
# 単位を列として定義し、数値1を代入する
words_df[word_tmp] = [1]
all_words_df = pd.concat([all_words_df, words_df], ignore_index = True)
"""データの確認"""
display(all_words_df.head())
print()
collect()
%%time
# 欠損値処理
all_words_df = all_words_df.fillna(0)
"""修正後のデータの確認"""
PrintColor(f'\n all_words_df')
display(all_words_df.head())
print()
collect()
Knock100:類似アンケートを探す
%%time
# コメント列のみ表示
PrintColor(f"\n survey['comment'].iloc[2]")
print(survey['comment'].iloc[2])
target_text = all_words_df.iloc[2]
PrintColor(f"\n target_text")
display(target_text)
print()
collect()
次にコサイン類似度を用いて類似検索を行います。
%%time
"""類似度検索を行う"""
# コサイン類似度を格納するリストを作成
cos_sim = []
for i in range(len(all_words_df)):
cos_text = all_words_df.iloc[i]
# コサイン類似度の計算式
cos = np.dot(target_text, cos_text) / (np.linalg.norm(target_text) * np.linalg.norm(cos_text))
cos_sim.append(cos)
# テキストではall_words_dfに直接追加しているが、再実行でエラーが出るため、新しくデータフレームを作成
all_words_df_w_cos_sim = all_words_df.copy()
all_words_df_w_cos_sim['cos_sim'] = cos_sim
PrintColor(f'\n all_words_df_w_cos_sim')
display(all_words_df_w_cos_sim.sort_values('cos_sim', ascending = False).head())
print()
collect()
print(survey['comment'].iloc[2])
print(survey['comment'].iloc[24])
print(survey['comment'].iloc[15])
print(survey['comment'].iloc[33])
ご協力のほどよろしくお願いします。
Discussion