SageMakerで機械学習パイプラインを実行する
はじめに
この記事は Classi developers Advent Calendar 2022 の13日目の記事です
Amazon SageMaker の機能である Amazon SageMaker Pipelines を使って、S3のデータセットから特徴量抽出し、BERTモデルを訓練するパイプラインを定義・実行する手順をまとめます
この記事の内容は書籍「実践 AWSデータサイエンス」および oreilly-japan/data-science-on-aws-jpを参考にしています
データセットを用意する
データセットにはAmazon Customer Peviews Datasetを使います
これは1995年から2015年までの間に、Amazon.comのウェブサイトに掲載された43種類の異なるカテゴリー商品に対する1億5千万件以上のカスタマーレビューから構成されているデータセットです
このデータセットにはレビューテキストreview_bodyと評価star_ratingのカラムが含まれており、review_body から star_rating を予測するBERTモデルを訓練します
今回はこのデータセットの中の「amazon_reviews_us_Digital_Software_v1_00.tsv.gz」だけ
使います
AWSコンソールのCloudShellからコマンドを実行して、S3バケットを作成しデータセットファイルをダウンロードします


# 自分のアカウントにyouichiro-amazon-reviews-pdsというS3バケットを作成する
$ aws s3 mb s3://youichiro-amazon-reviews-pds
# データセットファイルをダウンロードする
$ aws s3 cp --recursive s3://amazon-reviews-pds/tsv/ \
s3://youichiro-amazon-reviews-pds/tsv/ \
--exclude "*" --include "amazon_reviews_us_Digital_Software_v1_00.tsv.gz"
SageMaker Studioを起動する
SageMakerをセットアップします
まず、SageMakerのコンソールを開き、SageMakerドメインの作成を行います

高速セットアップで簡単に設定を行えます
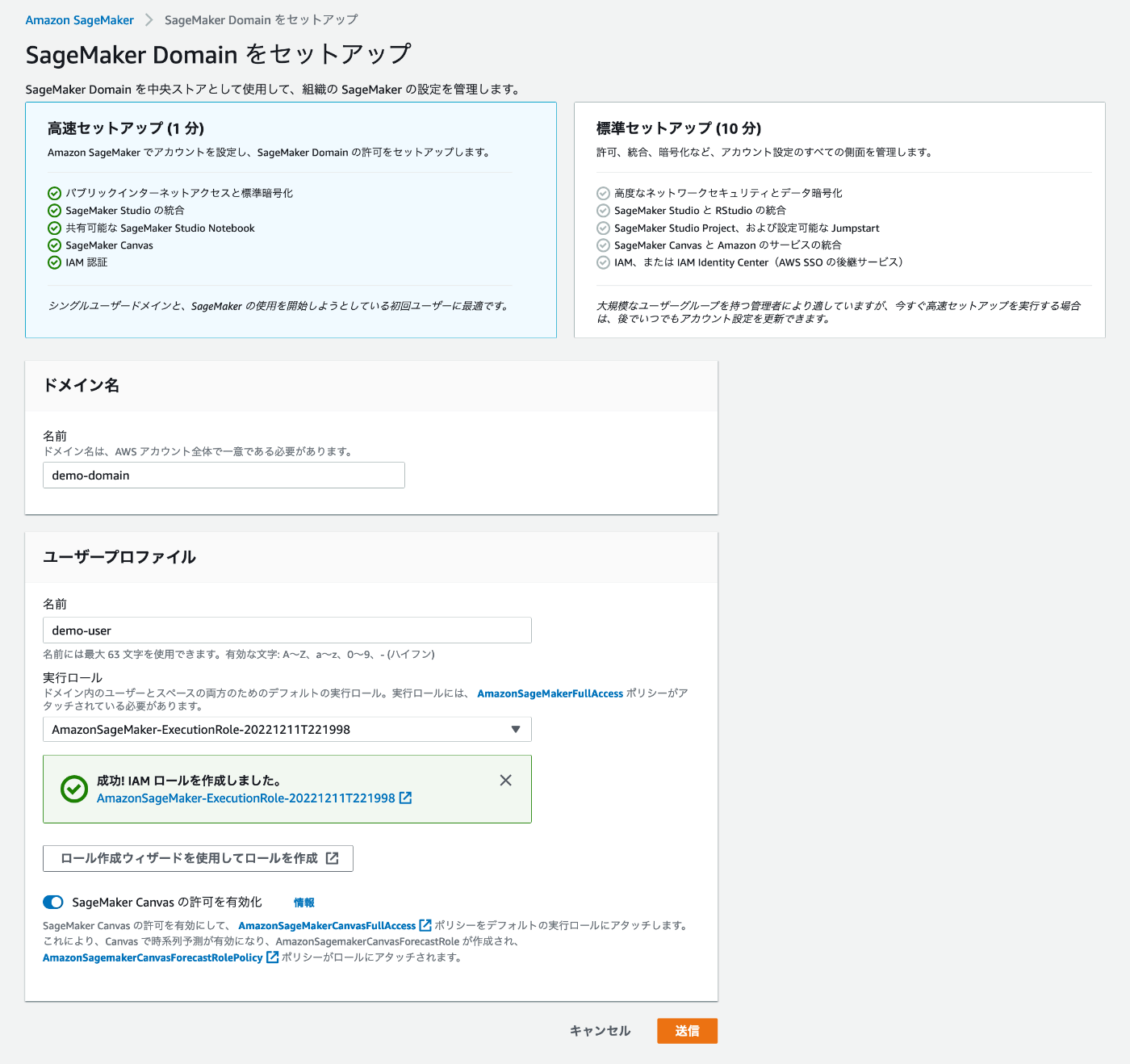
SageMakerの実行ロールを指定する必要があります。「新しいロールの作成」で作成できます。

ドメインが作成されるまで少し時間がかかります
作成されたら、ユーザープロファイルからSageMaker Studioを起動します

Launcherから「Create notebook」をクリックして新規のノートブックを起動します
このとき、Imageを「Data Science」から「TensorFlow 2.6 Python 3.8 CPU Optimized」に変更しておきます

機械学習パイプラインを定義する
この記事では、図のようなMLOps全体のうち、機械学習パイプラインの自動化の部分を構築します

出典: MLOps: 機械学習における継続的デリバリーと自動化のパイプライン#MLOps レベル 2: CI / CD パイプラインの自動化
以下のような処理をパイプライン化します
- 特徴量エンジニアリングステップ (Processing)
- データセットを入力し、それをtrain/validation/testに分割して特徴量に変換して出力します
- モデル訓練ステップ (Train)
- 特徴量を入力し、事前学習済みBERTをファインチューニングしたモデルを出力します
- モデル評価ステップ (EvaluateModel)
- 訓練したモデルとテストデータを入力し、評価メトリクスを出力します
- モデルレジストリ登録ステップ (RegisterModel)
- 訓練したモデルをモデルレジストリに登録します
- モデル検証ステップ (AccuracyCondition)
- 評価メトリクスの値が閾値を超えた場合にモデルレジストリ登録ステップを実行するようにします
0. スクリプトのダウンロード
今回使用する前処理・モデル訓練・モデル評価のスクリプトは「実践 AWSデータサイエンス ハンズオンワークショップ」のスクリプトを使用します
ノートブックで以下のコマンドを実行し、スクリプトをノートブック上にダウンロードしておきます
!wget -O preprocessing.py https://raw.githubusercontent.com/oreilly-japan/data-science-on-aws-jp/main/workshop/00_quickstart/preprocess-scikit-text-to-bert-feature-store.py
!wget -O train.py https://raw.githubusercontent.com/oreilly-japan/data-science-on-aws-jp/main/workshop/00_quickstart/src/tf_bert_reviews.py
!wget -O evaluation.py https://raw.githubusercontent.com/oreilly-japan/data-science-on-aws-jp/main/workshop/00_quickstart/evaluate_model_metrics.py
それぞれのスクリプトでは以下のような処理を行います
- preprocessing.py
- データセットのラベルごとのデータサイズをバランス化する
- データセットをtrain/validation/testに分割する
- データセットをTFRecord形式の特徴量ファイルに変換する
- SageMaker Feature Storeに特徴量を保存する
- train.py
- 事前学習済みBERTをファインチューニングしてモデルを保存する
- evaluation.py
- テストデータに対してモデル推論し、正解率Accuracyを計算する
1. 特徴量エンジニアリングステップ
SageMakerセッションを作成します
import sagemaker
import boto3
import datetime
sess = sagemaker.Session()
bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
sm = boto3.Session().client(service_name="sagemaker", region_name=region)
s3 = boto3.Session().client(service_name="s3", region_name=region)
featurestore_runtime = boto3.Session().client(service_name="sagemaker-featurestore-runtime", region_name=region)
timestamp = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
パイプラインで使用するデータセットやスクリプトのパス、名前を定義しておきます
# データセットのS3パス
INPUT_S3_URI = "s3://youichiro-amazon-reviews-pds/tsv/amazon_reviews_us_Digital_Software_v1_00.tsv.gz"
# 使用するスクリプトのパス
PREPROCESSING_SCRIPT_PATH="./preprocessing.py"
TRAIN_SCRIPT_PATH="./train.py"
EVALUATION_SCRIPT_PATH="./evaluation.py"
# 名前の定義
PIPELINE_NAME = f"reviews-bert-pipeline-{timestamp}"
FEATURE_STORE_OFFLINE_PREFIX=f"reviews-feature-store-{timestamp}"
FEATURE_GROUP_NAME=f"reviews-feature-group-{timestamp}"
MODEL_PACKAGE_GROUP_NAME=f"reviews-bert-model-group-{timestamp}"
パイプラインパラメータを定義します
パイプラインパラメータを定義しておくことで、パイプラインを実行するときにパイプライン定義を変更することなく値を変更することができます
from sagemaker.workflow.parameters import ParameterString, ParameterInteger, ParameterFloat
processing_instance_type = ParameterString(name="ProcessingInstanceType", default_value="ml.c5.2xlarge")
processing_instance_count = ParameterInteger(name="ProcessingInstanceCount", default_value=1)
train_instance_type = ParameterString(name="TrainInstanceType", default_value="ml.c5.9xlarge")
train_instance_count = ParameterInteger(name="TrainInstanceCount", default_value=1)
特徴量エンジニアリング処理を実行するプロセッサーを定義します
このプロセッサーは次のProcessingStepで使用します
from sagemaker.sklearn.processing import SKLearnProcessor
processor = SKLearnProcessor(
framework_version="0.23-1",
role=role,
instance_type=processing_instance_type,
instance_count=processing_instance_count,
env={"AWS_DEFAULT_REGION": region},
)
SKLearnProcessorはscikit-learnがインストールされているDockerイメージを使いたいときに指定するプロセッサーです (参考: Data Processing with scikit-learn)
独自のDockerイメージを使う場合はScriptProcessorを指定します
特徴量エンジニアリングステップを定義します
ProcessingStepに前処理スクリプトのパス、入力データ、出力データ、プロセッサー、スクリプトの引数を指定しています
from sagemaker.processing import ProcessingInput, ProcessingOutput
from sagemaker.workflow.steps import ProcessingStep
processing_step = ProcessingStep(
name="Processing",
code=PREPROCESSING_SCRIPT_PATH,
processor=processor,
inputs=[
ProcessingInput(input_name="input", source=INPUT_S3_URI, destination="/opt/ml/processing/input/data/"),
],
outputs=[
ProcessingOutput(output_name="train", source="/opt/ml/processing/output/bert/train"),
ProcessingOutput(output_name="validation", source="/opt/ml/processing/output/bert/validation"),
ProcessingOutput(output_name="test", source="/opt/ml/processing/output/bert/test"),
],
job_arguments=[
"--feature-store-offline-prefix",
FEATURE_STORE_OFFLINE_PREFIX,
"--feature-group-name",
FEATURE_GROUP_NAME,
],
)
2. モデル訓練ステップを定義する
モデルの訓練を行うジョブ(estimator)を定義します
from sagemaker.tensorflow import TensorFlow
metrics_definitions = [
{"Name": "train:loss", "Regex": "loss: ([0-9\\.]+)"},
{"Name": "train:accuracy", "Regex": "accuracy: ([0-9\\.]+)"},
{"Name": "validation:loss", "Regex": "val_loss: ([0-9\\.]+)"},
{"Name": "validation:accuracy", "Regex": "val_accuracy: ([0-9\\.]+)"},
]
estimator = TensorFlow(
entry_point=TRAIN_SCRIPT_PATH,
role=role,
instance_count=train_instance_count,
instance_type=train_instance_type,
volume_size=256,
py_version="py37",
framework_version="2.3.1",
hyperparameters={
"epochs": "1",
"learning_rate": "0.00001",
"epsilon": "0.00000001",
"train_batch_size": "128",
"validation_batch_size": "128",
"test_batch_size": "128",
"train_steps_per_epoch": "50",
"validation_steps": "50",
"test_steps": "50",
"max_seq_length": 64,
"freeze_bert_layer": "False",
"enable_sagemaker_debugger": "True",
"enable_checkpointing": "True",
"enable_tensorboard": "True",
"run_validation": "True",
"run_test": "False",
"run_sample_predictions": "False",
},
input_mode="File",
metric_definitions=metrics_definitions,
)
モデル訓練ステップを定義します
TrainingStepに入力データと先ほど定義したestimatorを指定します
from sagemaker.inputs import TrainingInput
from sagemaker.workflow.steps import TrainingStep
training_step = TrainingStep(
name="Train",
estimator=estimator,
inputs={
"train": TrainingInput(
s3_data=processing_step.properties.ProcessingOutputConfig.Outputs["train"].S3Output.S3Uri,
content_type="text/csv",
),
"validation": TrainingInput(
s3_data=processing_step.properties.ProcessingOutputConfig.Outputs["validation"].S3Output.S3Uri,
content_type="text/csv",
),
"test": TrainingInput(
s3_data=processing_step.properties.ProcessingOutputConfig.Outputs["test"].S3Output.S3Uri,
content_type="text/csv",
),
},
)
3. モデル評価ステップを定義する
モデル評価処理を実行するプロセッサーを定義します
from sagemaker.sklearn.processing import SKLearnProcessor
evaluation_processor = SKLearnProcessor(
framework_version="0.23-1",
role=role,
instance_type=processing_instance_type,
instance_count=processing_instance_count,
env={"AWS_DEFAULT_REGION": region},
max_runtime_in_seconds=7200,
)
モデル評価ステップを定義します
ProcessingStepに評価スクリプトのパス、プロセッサー、入力データ、出力データを指定しています
また、PropertyFileを定義してProcessingStepの出力ファイルを保存しておきます
ここで出力される評価メトリクスの値は、後のモデル検証ステップで閾値によって条件分岐する際に使用するためです
参考: Property Files and JsonGet
from sagemaker.workflow.properties import PropertyFile
evaluation_report = PropertyFile(name="EvaluationReport", output_name="metrics", path="evaluation.json")
evaluation_step = ProcessingStep(
name="EvaluateModel",
processor=evaluation_processor,
code=EVALUATION_SCRIPT_PATH,
inputs=[
ProcessingInput(
source=training_step.properties.ModelArtifacts.S3ModelArtifacts,
destination="/opt/ml/processing/input/model",
),
ProcessingInput(
source=processing_step.properties.ProcessingInputs["input"].S3Input.S3Uri,
destination="/opt/ml/processing/input/data",
),
],
outputs=[
ProcessingOutput(output_name="metrics", source="/opt/ml/processing/output/metrics/", s3_upload_mode="EndOfJob"),
],
property_files=[evaluation_report],
)
4. モデルレジストリ登録ステップを定義する
モデル推論を実行するためのDockerイメージを取得します
sagemaker.image_uris.retrieveでSageMakerが提供している機械学習用イメージを取得することができます
deploy_instance_type = ParameterString(name="DeployInstanceType", default_value="ml.m5.4xlarge")
inference_image_uri = sagemaker.image_uris.retrieve(
framework="tensorflow",
region=region,
version="2.3.1",
instance_type=deploy_instance_type,
image_scope="inference",
)
モデルレジストリ登録ステップを定義します
from sagemaker.model_metrics import MetricsSource, ModelMetrics
from sagemaker.workflow.step_collections import RegisterModel
model_metrics = ModelMetrics(
model_statistics=MetricsSource(
s3_uri="{}/evaluation.json".format(
evaluation_step.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"]
),
content_type="application/json"
)
)
register_step = RegisterModel(
name="RegisterModel",
estimator=estimator,
image_uri=inference_image_uri,
model_data=training_step.properties.ModelArtifacts.S3ModelArtifacts,
content_types=["application/jsonlines"],
response_types=["application/jsonlines"],
inference_instances=[deploy_instance_type],
transform_instances=["ml.m5.4xlarge"],
model_package_group_name=MODEL_PACKAGE_GROUP_NAME,
approval_status="PendingManualApproval",
model_metrics=model_metrics,
)
5. モデル検証ステップを定義する
モデル検証ステップを定義します
ConditionStepに分岐させる条件、条件を満たした/満たさなかった場合の実行ステップを指定します
ConditionGreaterThanOrEqualToでleftの値がrightの値以上かどうかを比較します
ここで先ほど作成したevaluation_reportを指定して、モデルの評価メトリクスを取得しています
from sagemaker.workflow.conditions import ConditionGreaterThanOrEqualTo
from sagemaker.workflow.condition_step import ConditionStep, JsonGet
min_accuracy_value = ParameterFloat(name="MinAccuracyValue", default_value=0.10)
minimum_accuracy_condition = ConditionGreaterThanOrEqualTo(
left=JsonGet(
step=evaluation_step,
property_file=evaluation_report,
json_path="metrics.accuracy.value",
),
right=min_accuracy_value,
)
minimum_accuracy_condition_step = ConditionStep(
name="AccuracyCondition",
conditions=[minimum_accuracy_condition],
if_steps=[register_step],
else_steps=[],
)
パイプラインを実行する
定義したステップを実行するためのパイプラインを定義します
from sagemaker.workflow.pipeline import Pipeline
pipeline = Pipeline(
name=PIPELINE_NAME,
parameters=[
processing_instance_type,
processing_instance_count,
train_instance_type,
train_instance_count,
deploy_instance_type,
min_accuracy_value,
],
steps=[processing_step, training_step, evaluation_step, minimum_accuracy_condition_step],
sagemaker_session=sess,
)
pipeline.create(role_arn=role)["PipelineArn"]
パイプラインを実行します
execution = pipeline.start()
パイプラインのステータスはサイドメニューの「Pipelines」で確認することができます
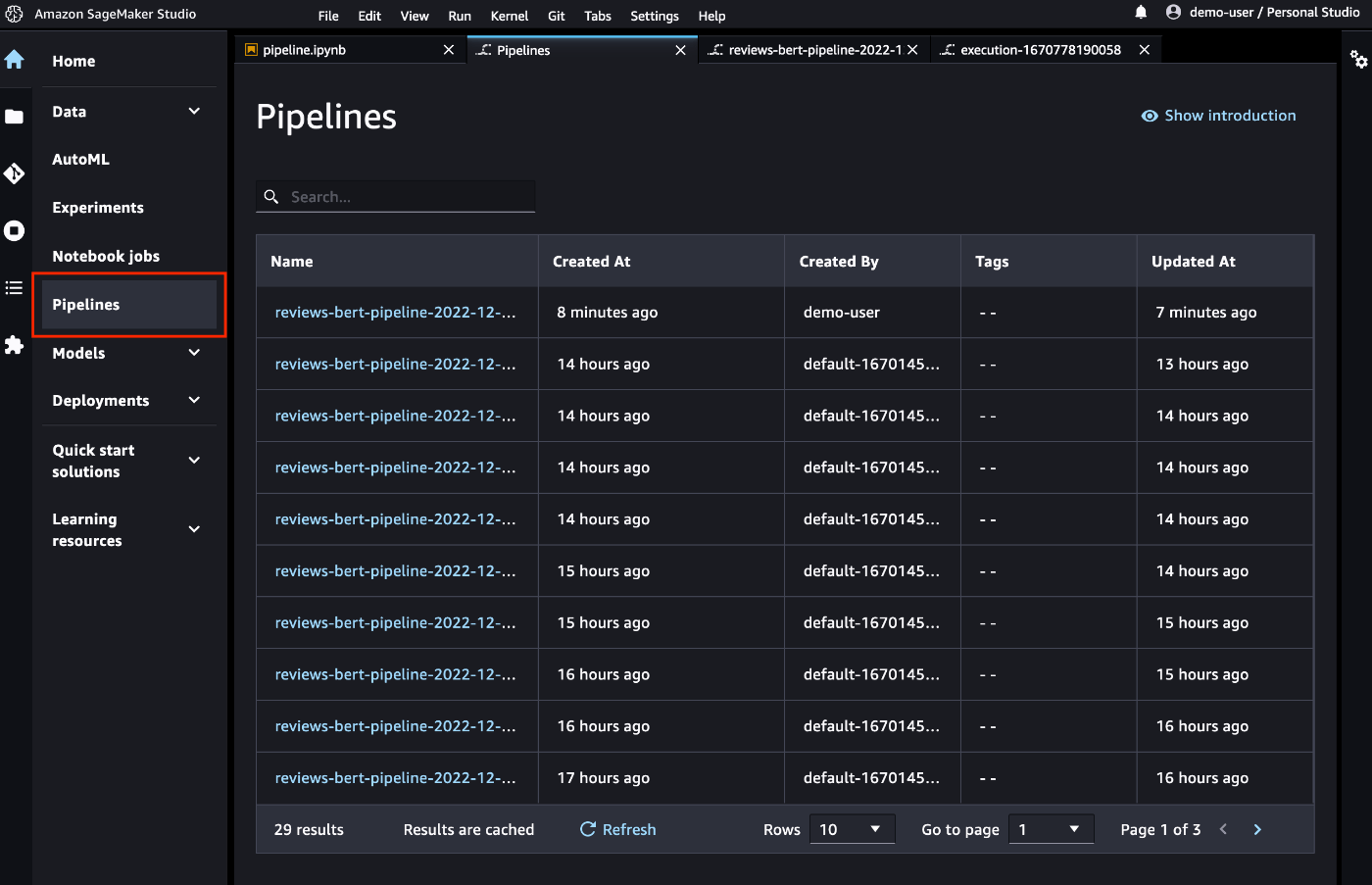
パイプラインのグラフや実行ステータス、パラメータやログなどを確認することができます

パイプライン実行が成功したら、モデルがモデルレジストリに登録されます

おわりに
モデルレジストリに登録したモデルを実際に(バッチ処理などで)使ってみるところもやってみたいと思っています
Discussion