🕌
wandbを試す
wandbのインストールとログイン
wandbのアカウントを作成する
wandbをインストールする
pip install wandb
wandbコマンドでログインする
wandb login
https://wandb.ai/authorize に表示されるキーを入力する
ログイン情報は ~/.netrc と ~/.config/wandb/settings に保存される
もしログイン情報をリセットしたい場合は rm ~/.netrc && rm ~/.config/wandb/settings でファイルを削除する必要がある
transformersでの書き方
以下のように書くことでwandbの画面で学習のログを表示できる
import wandb
from transformers import TrainingArguments, Trainer
wandb.init(project="my-test-project", name="display name")
# ...
args = TrainingArguments(..., report_to="wandb")
trainer = Trainer(..., args=args)
trainer.train()
wandb.initの引数の情報はここ
transformersの他にも、PyTorchやTensorFlowなどでの書き方も用意されている(かなりシンプル)
「Fine-tune a pretrained model」を試す
https://huggingface.co/docs/transformers/training の内容をwandbを使って試してみる
pip install torch transformers[torch] datasets evaluate sklearn
finetune.py
import wandb
wandb.init(project="my-test-project", name="yelp_review_full bert classification")
import numpy as np
import evaluate
from datasets import load_dataset
from transformers import (
AutoTokenizer,
AutoModelForSequenceClassification,
TrainingArguments,
Trainer
)
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
# prepare a dataset
dataset = load_dataset("yelp_review_full")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
tokenized_datasets = dataset.map(tokenize_function, batched=True)
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(10))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(10))
# train
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", num_labels=5)
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
training_args = TrainingArguments(output_dir="test_trainer", evaluation_strategy="epoch", report_to="wandb")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
# save a model
save_dir = 'model'
tokenizer.save_pretrained(save_dir)
model.save_pretrained(save_dir)
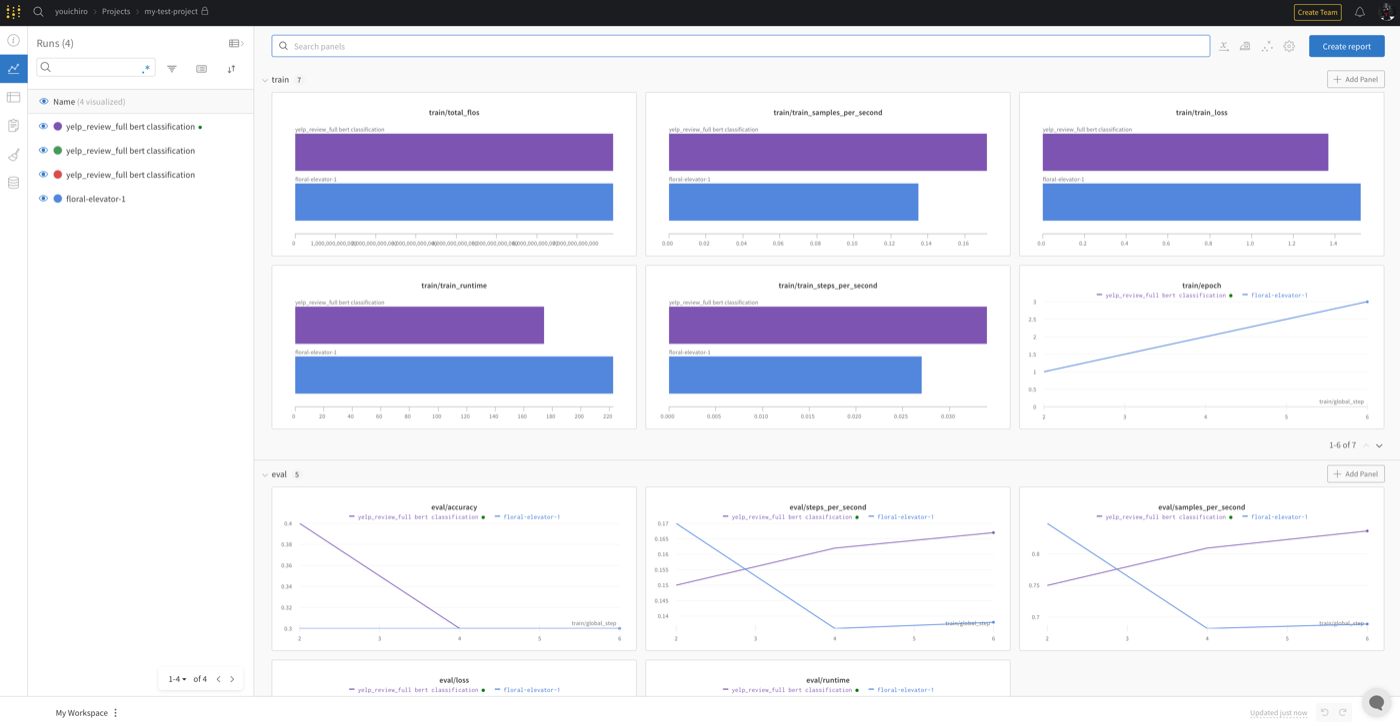
wandbのサイトにプロジェクトが作成され、学習のログが表示される
https://wandb.ai/<your_account>/my-test-project
Discussion