音声データの扱い方をざっくり勉強したのでまとめ
ハッカソンに応募したアプリで、音声データを主に利用したサービスを作りました。
これまで主に扱ってきたのはテキストや画像データだったため、音声データの特性を理解するのに苦戦しました。特に 「音声は時間軸を持つ連続データである(時系列データ)」という性質は、ストリーミング処理の必要性を意識する大きなきっかけになり、gRPCの学習にもつながりました。
また、音声認識や音声生成といったAI機能は、Google CloudのSpeech系のAPIを利用しましたが、APIを使うだけでも苦戦しました。「サンプリングレート」や「ファイルフォーマット」等々の意味がわからず状態で、クライアントとサーバーで設定値が異なり、エラーになるケースが多発しました。。。
そこで、自分なりに音声データの実態を理解した内容を、クライアント側のアプリ開発をする目線で、アウトプットしたいと思います。
本記事では、テキストだけではなく、頭の中で捉えた内容を、とにかく絵で表現することを重視して作りました。
これから音声データをプログラム上で扱う初心者の方向けに、音声データを理解するきっかけとして手助けになれば嬉しいです!
0. 音声データの処理の全体像
今回、「クライアント端末上で音声を録音し、録音した音声データをサーバへ送るまで」のケースを想定し、クライアント側で行われる音声データ処理の流れの全体像をざっくりと絵に落としてみました。
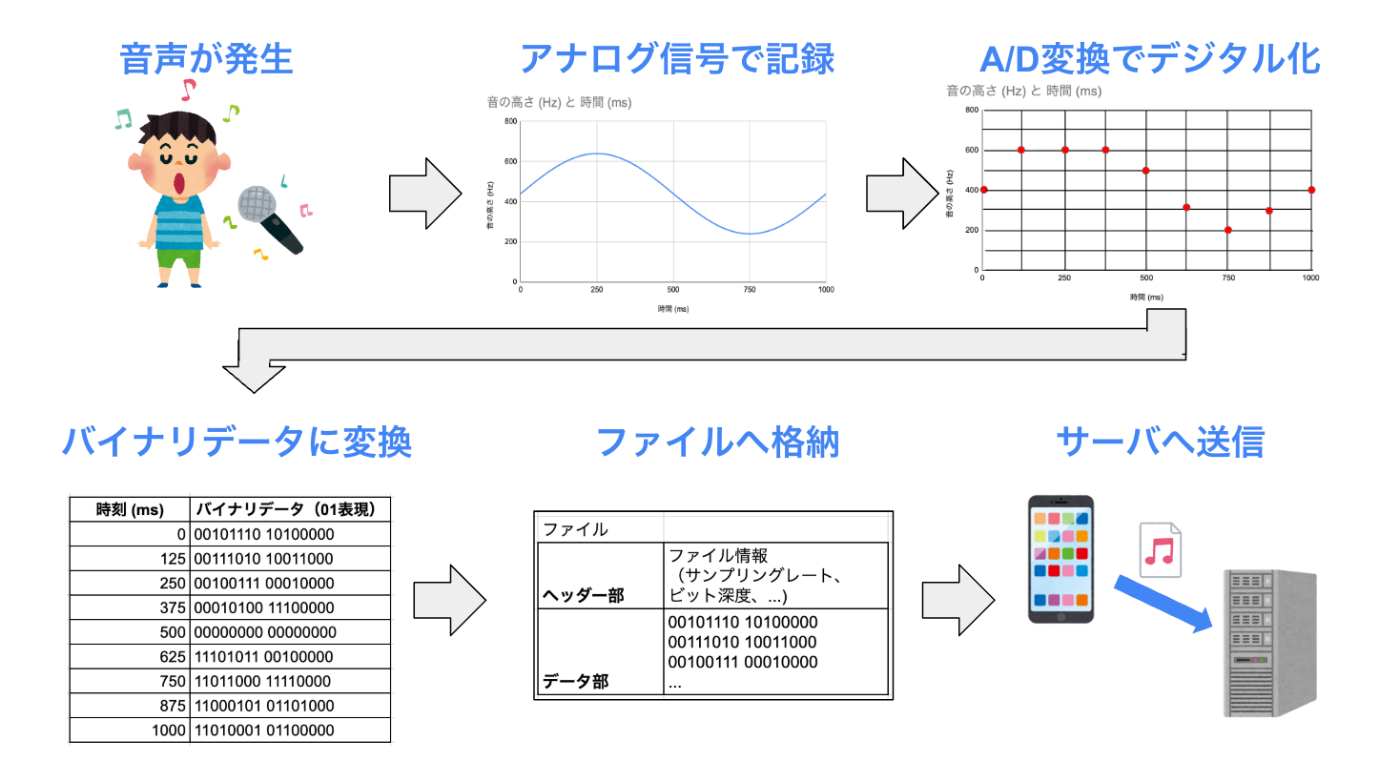
- まず、音源から空気中を伝わる波として音声が発生。
- 次に、マイクが、波をアナログ信号として記録。
- そして、A/D変換(アナログからデジタルへ変換)し、デジタル信号へ変換。
- その後、2進数のバイナリデータとして変換。
- さらに、ファイル内へバイナリデータを保存。
- 最後に、ファイルをサーバに送る。
ざっくりと上記の流れで僕は理解しました。
以降、勉強して理解した以下のステップで整理していきます。
1. 音声をアナログ信号で記録する過程

音声をアナログ信号として記録する際、マイクごとに周波数特性やフィルタリング機能などの違いがあると思います。
しかし、今回のアプリ開発では、スマホ内蔵マイクを使用し、特に問題はなかったため、マイクの特性は深く意識しませんでした。唯一、設定を見直す際に意識したのは「チャンネル数」です。
チャンネル
チャンネルとは「独立した音源の数」を表します。
音声データ内で使われる独立した音源の数を表す指標を「チャンネル数」と呼ぶようです。
具体的には、以下のような種類があります。
- モノラル(1チャンネル): 単一の音声トラック。
- ステレオ(2チャンネル): 左右で異なる音声トラック。
- サラウンド(5.1, 7.1など): 左右だけでなく、奥行きや高さを感じる。
モノラルやステレオは、単語として聞いたことがありますね。
今回作成したアプリでは、ユーザがスマホの前で録音する前提(音源が1つ)だったため、モノラル(1チャンネル)を利用しました。
そのため、以降も、モノラル(1チャンネル)前提で記載していきます。
2. アナログからデジタルへの変換の過程
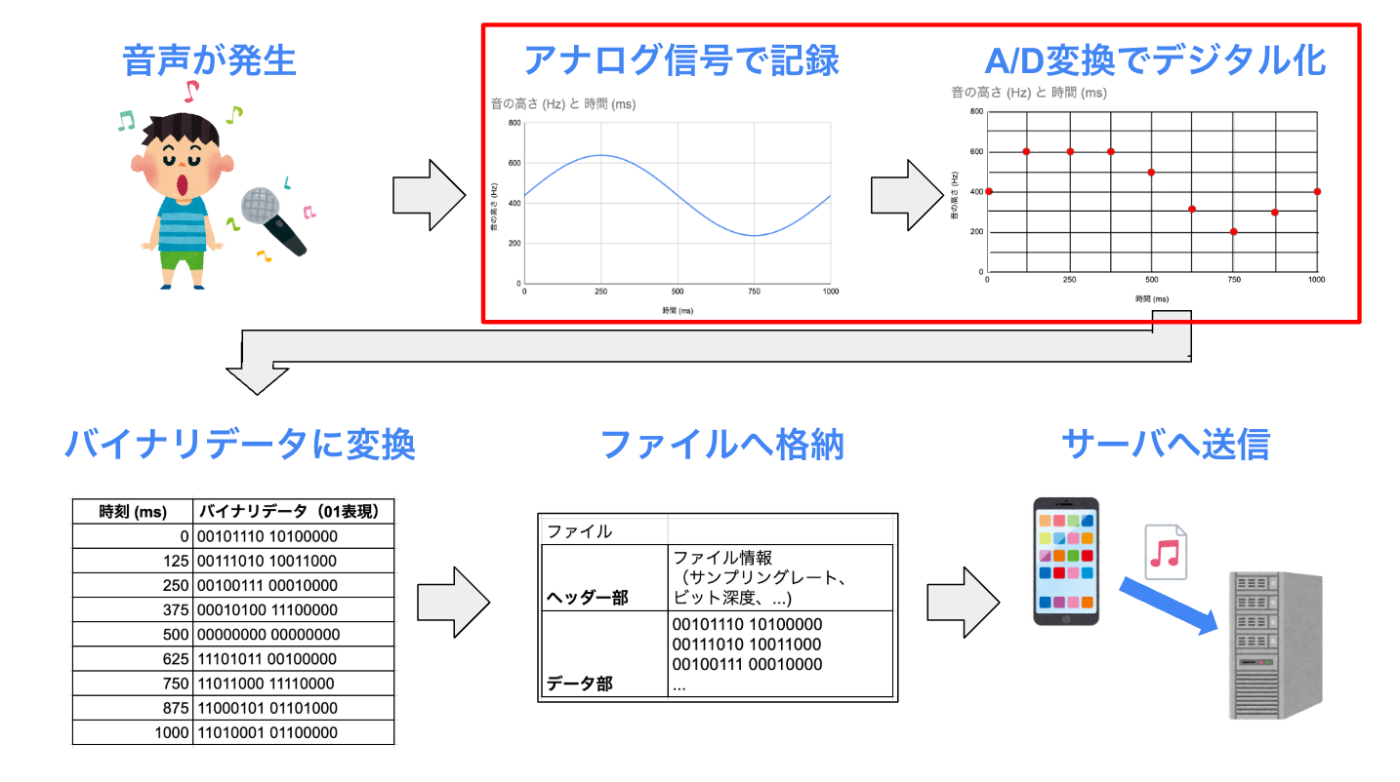
A/D変換の過程では、頻繁に設定項目として登場した「サンプリングレート」や「ビット深度」が関わってきます。
(最初、ここで躓きました...)
サンプリング
サンプリングは、アナログ音声信号(連続的な波)をデジタル化する際、一定の時間間隔でデータとして記録する処理のことです。
どのくらいの時間間隔で細かく記録するかの指標を「サンプリングレート」と呼びます。
例えば、サンプリングレートが「16,000Hz」の場合、1秒間に16,000回サンプリングを行います。
一般的には、目的に応じて、サンプリングレートは変化させるようです。
以下、参考イメージ例です。
- 電話
- 8,000 Hz
- 音声認識
- 16,000 Hz
- CD音質
- 44,100 Hz
- ...
実際にイメージを描いてみます。
横軸の時間軸において、一定の間隔で、記録するタイミングを赤い線で示しています。
以下の図では、「125msに1回」サンプリングを行うイメージです。

さらに、サンプリングレートを2倍にして「62.5msに1回」サンプリングと以下の図のようになります。
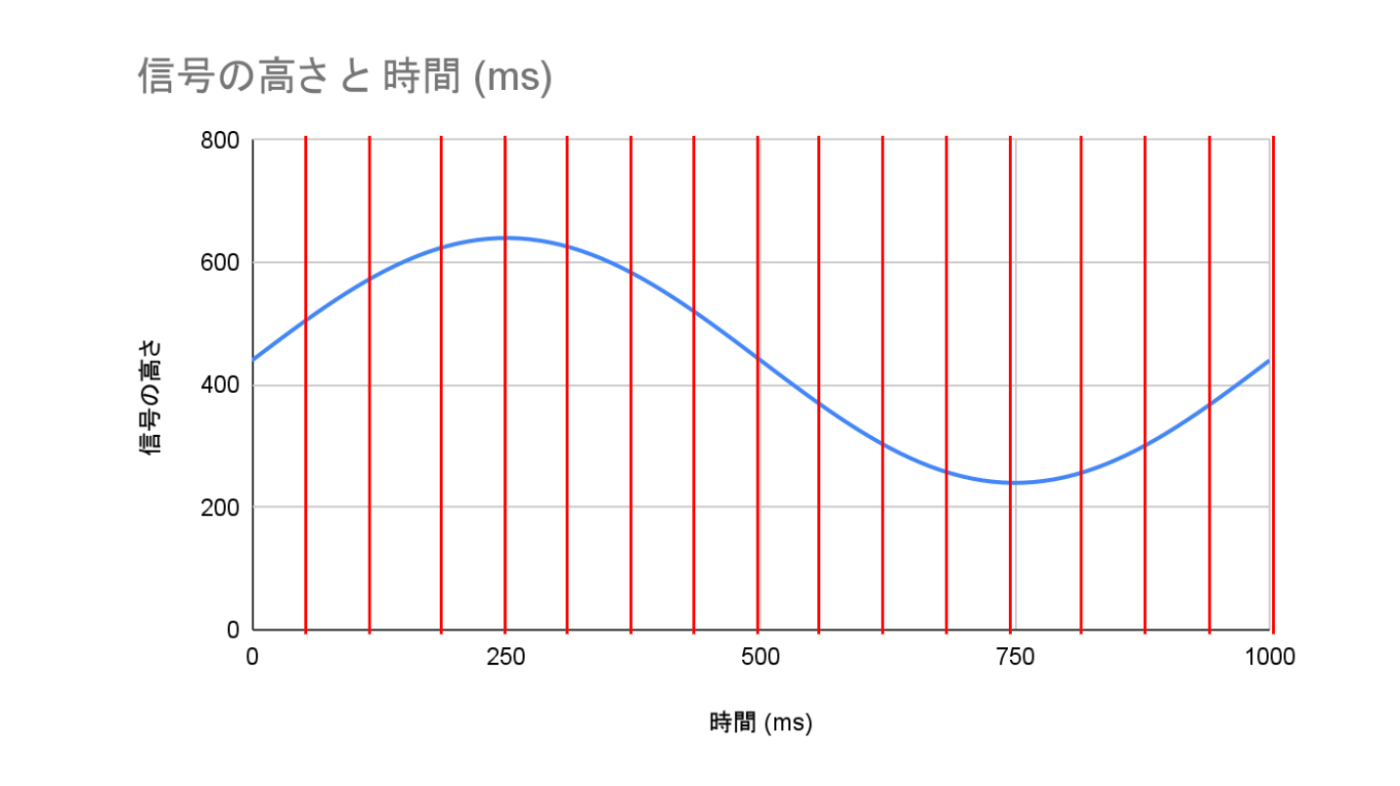
つまり、サンプリングレートが大きいほど、より細かい時間間隔でデータを記録でき、高品質のデータになりますが、同時にデータ量も増えますね。
量子化
量子化は、サンプリング点で取得した「波の高さ」をデジタル値に変換する処理です。
どのくらい細かく記録するかの指標を「ビット深度」と呼びます。
例えば、「16ビット」量子化の場合、各サンプル値を16ビット(0〜65,535段階)で表現します。
音声信号の最小値(-32,768)から最大値(+32,767)の範囲で記録するようです。
一般的には、目的に応じて、サンプリングレートは変化させるようです。
以下、参考イメージ例です。
- 電話
- 8 bit
- 音声認識
- 16 bit
- CD音質
- 16 bit
- ...
今回も、実際にイメージを描いてみます。
量子化は、縦軸の波の高さにおいて、一定の間隔で、記録するタイミングを赤い線で示しています。
以下の図では、「高さ100間隔」で記録を行うイメージです。

さらに、ビット深度を2倍にして「高さ50間隔」で記録を行うと以下の図のようになります。

つまり、サンプリングレート同様に、ビット深度が大きいほど、より細かく信号を記録でき、高品質のデータになりますが、同時にデータ量も増えますね。
サンプリングと量子化によりデジタルの世界へ
「サンプリング」と「量子化」を行うことで、実際のデジタルデータとして記録できるように一定の間隔でデータが変換されます。
このプロセスが、A/D変換なんだと僕は理解しました。
「125msに1回」、「高さ100間隔」でA/D変換を行う過程のイメージも図にしてみました。

アナログ信号が、縦線と横線の交差点に一番近い部分を、赤い点でマークしてみています。

これにより、連続的だったアナログ信号は、一定の間隔に分割されたデジタル信号に変更されました。
A/D変換後、デジタル化されたデータを、01で表現するバイナリデータに変換する過程については、2進数に変換をするだけかと思い、あまり深く調べなかったので、割愛します。

ざっくり、上記のように記録した順番に、信号の高さを2進数で表現しているんだと思います。
3. バイナリデータをファイルに格納する過程

バイナリデータを、今度はファイルへ格納する過程を見てみます。
まずは、バイナリデータをエンコーディングした上で、ファイルフォーマットに合わせてデータを格納する流れになる理解をしてます。
エンコーディング形式
エンコーディングとは、データを特定の形式に変換する処理のことです。
音声エンコーディングには、大きく分けて「非圧縮」「可逆圧縮」「非可逆圧縮」の3種類があります。
| 種類 | 具体例 | 特徴 |
|---|---|---|
| 非圧縮 | PCM, ... | 録音したデータをそのまま保つため、データの質は高いが、ファイルサイズが大きい |
| 可逆圧縮 | FLAC, ALAC, ... | 録音したデータに戻せる状態で圧縮するため、質が高い状態を保ちつつ、ファイルサイズ小さくできる |
| 非可逆圧縮 | MP3, AAC, ... | 録音したデータから人間に聞こえにくい音を削除して圧縮するため、元のデータに戻せないが、ファイルサイズがとても小さい |
普段聞く音楽ファイルの拡張子が「.mp3」だなー、くらいしか意識していませんでしたが、mp3は非可逆圧縮であり、人間が聞く前提でデータを圧縮し、データ量を減らして保存されていたんですね。ふむふむ。
ファイルフォーマット
エンコードした音声データの保存形式が、ファイルフォーマットです。
例えば、非圧縮の「PCM」というエンコーディング形式を使う場合、「WAV」というファイルフォーマットを利用したりします。
拡張子が「.wav」のファイルは、見たことありますね。
一方でFLAC, MP3等は、どうやらは「エンコーディング形式」でもあり、「ファイルフォーマット」でもあるみたいです。
拡張子が「.mp3」のファイルは、頻繁に見たことあります。
| 種類 | ファイルフォーマット例 | エンコーディング形式例 |
|---|---|---|
| 非圧縮 | WAV, ... | PCM, ... |
| 可逆圧縮 | FLAC, ALAC, ... | FLAC, ALAC, ... |
| 非可逆圧縮 | MP3, AAC, ... | MP3, AAC, ... |
(Flutterの音声ライブラリやGoogle Cloudの音声APIを利用する際に、「wav」や「pcm」といったワードが出てくるたびに、よくわからん状態になっていました。今でも、正直はっきり理解しきれていませんが。。。)
ファイルの中は、基本的には「ヘッダー部(ファイル識別情報やオーディオフォーマット情報など)」+「データ部(実際の音声データ)」が、ファイルの中には保存されているであろう、というざっくりとした浅い理解でした。(以下イメージ図)

せっかくなので、今回記事を作るタイミングで、具体的な音声ファイルの構造を調べてみました。
今回は、例として「WAVファイル」のバイナリデータを見てみました。
(WAVではなく、FLACやMP3などは、また別のファイル構造になっているようです。)
WAV(非圧縮)
手元のwavファイルの中身を確認すると、以下のような表示がされました。
xxd -l 2048 sample_hello.wav
00000000: 5249 4646 063b 0100 5741 5645 666d 7420 RIFF.;..WAVEfmt
00000010: 1000 0000 0100 0100 803e 0000 007d 0000 .........>...}..
00000020: 0200 1000 4c49 5354 3000 0000 494e 464f ....LIST0...INFO
00000030: 494e 414d 0d00 0000 7361 6d70 6c65 5f68 INAM....sample_h
00000040: 656c 6c6f 0000 4953 4654 0d00 0000 4c61 ello..ISFT....La
00000050: 7666 3631 2e37 2e31 3030 0000 6461 7461 vf61.7.100..data
00000060: aa3a 0100 0000 0000 0000 0000 0000 0000 .:..............
00000070: 0000 0000 0000 0000 0000 0000 0000 0000 ................
...
00000640: 0100 0000 0000 0000 0000 0000 0000 0000 ................
00000650: 0000 0000 0000 0000 0000 0000 0000 ffff ................
00000660: ffff 0000 ffff 0000 ffff 0000 ffff ffff ................
00000670: 0000 0000 0000 0000 0000 0100 0100 0100 ................
...
これだけでは、全くわからないですね。。。
16進数を眺める機会は、日常でなかなかありません。
おそらく一定のルールに沿って、メタデータや音声データが配置されていると思われるので、GPT先生に聞いて内容を整理しました。
中身を確認していきましょう。
ファイルの基本情報(RIFF ヘッダー)
00000000: 5249 4646 063b 0100 5741 5645 666d 7420 RIFF.;..WAVEfmt
最初は、ヘッダー部分にファイル全体の構造が入っています。
例えば、今回見ているwavファイルは、RIFF形式で保存されることが定義されているようですね。
| オフセット | バイナリ値 | データの意味 |
|---|---|---|
| 0x00 | 5249 4646 | "RIFF"(WAV ファイル識別子) |
| 0x04 | 063b 0100 | ファイルサイズ(0x013B06 = 80454 バイト) |
| 0x08 | 5741 5645 | "WAVE"(WAV フォーマット識別子) |
| 0x0C | 666D 7420 | "fmt "(フォーマットチャンク識別子) |
ちなみに、オフセットとは「データの位置(アドレス)」を表すものです。
それぞれの位置によって、データの意味合いが決まっているみたいですね。
ヘッダー部分で、ファイル全体の構造が定義されることで、なんの情報がどこに保存されるのか、ファイル内のデータの配置ルールが決まってくるみたいです。
フォーマット情報(チャンク)
00000010: 1000 0000 0100 0100 803e 0000 007d 0000 .........>...}..
00000020: 0200 1000 4c49 5354 3000 0000 494e 464f ....LIST0...INFO
次に、音声の再生などに必要なフォーマット情報が入っています。
| オフセット | バイナリ値 | データの意味 |
|---|---|---|
| 0x10 | 1000 0000 | fmt チャンクサイズ(0x0010 = 16 バイト) |
| 0x14 | 0100 | オーディオフォーマット(1 = PCM) |
| 0x16 | 0100 | チャンネル数(1 = モノラル) |
| 0x18 | 803e 0000 | サンプリングレート(0x3E80 = 16000 Hz = 16kHz) |
| 0x1C | 007d 0000 | バイトレート(16000 × 2 = 0x7D00 = 32000 bytes/sec) |
| 0x20 | 0200 | ブロックサイズ(1チャンネル × 16bit / 8 = 2 バイト) |
| 0x22 | 1000 | ビット深度(16 bit) |
| ... | ... | ... |
フォーマット情報で、今まで確認してきた、「チャンネル数」や「サンプリングレート」が入ってました。
このような設定値も、バイナリデータで表現されているわけです。
メタデータ情報(LIST チャンク)
00000020: 0200 1000 4c49 5354 3000 0000 494e 464f ....LIST0...INFO
00000030: 494e 414d 0d00 0000 7361 6d70 6c65 5f68 INAM....sample_h
00000040: 656c 6c6f 0000 4953 4654 0d00 0000 4c61 ello..ISFT....La
00000050: 7666 3631 2e37 2e31 3030 0000 6461 7461 vf61.7.100..data
次に、メタデータ情報として、ファイルのタイトル名などが含まれています。
「フォーマット情報」と比較すると、「メタデータ情報」は、音声を再生するために必要不可欠というわけではなく、あくまでオプション的な存在なのかなと思います。
例えば、メタデータ情報の「タイトル情報」が存在してなくても、音声の再生自体は問題なくできるはずです。(多分)
| オフセット | バイナリ値 | データの意味 |
|---|---|---|
| ... | ... | ... |
| 0x24 | 4C49 5354 | "LIST"(メタデータの識別子) |
| 0x28 | 3000 0000 | LIST チャンクサイズ(0x0030 = 48 バイト) |
| 0x2C | 494E 464F | "INFO"(メタデータセクション) |
| 0x30 | 494E 414D | "INAM"(タイトル情報) |
| 0x34 | 0D00 0000 | INAM チャンクサイズ(13バイト) |
| 0x38 | 7361 6D70 6C65 5F68 656C 6C6F 0000 | "sample_hello"(タイトル) |
| 0x44 | 4953 4654 | "ISFT"(ソフトウェア情報) |
| 0x48 | 0D00 0000 | ISFT チャンクサイズ(13バイト) |
| 0x4C | 4C61 7666 3631 2E37 2E31 3030 0000 | "Lavf61.7.100"(エンコードソフト) |
| ... | ... | ... |
音声データ
00000050: 7666 3631 2e37 2e31 3030 0000 6461 7461 vf61.7.100..data
00000060: aa3a 0100 0000 0000 0000 0000 0000 0000 .:..............
メタデータの後に、ようやく実際の音声データが格納されています。
実際の音声データは、最初に無音状態が続くので、おそらく「0000」が続いているようです。
| オフセット | バイナリ値 | データの意味 |
|---|---|---|
| ... | ... | ... |
| 0x50 | 6461 7461 | "data"(音声データ識別子) |
| 0x54 | aa3a 0100 | 音声データサイズ(0x013AAA = 80426 バイト) |
| 0x58 | 0000 0000 ... | 実際の音声データ |
| ... | ... | ... |
音声ファイルの中には、実際の音声データだけではなく、フォーマット情報等、これだけ細かく情報が詰め込まれているとわかりました。
クライアントアプリを開発するときは、細かいファイルの仕様は必要に応じて調べる程度で、普段は、ざっくりと以下のように、「ヘッダー部(ヘッダー・フォーマット情報・メタデータ情報等)」と「データ部(実際の音声データ)」で成り立っているんだなーと捉えれば良さそうな印象を持ちました。
以降の説明でも、上図を利用して、イメージ図を作成しています。
4. ファイルをクライアントからサーバに送る過程
今までの内容は、基本的には音声を扱うライブラリ側で実装されている内容だと思います。一般的なクライアントのアプリケーションを作る側の立場であれば、設定項目の意味合いをわかっていれば良いと考えています。
以降は、実際にクライアントのアプリケーションを作る立場でも、プログラムを作成する部分に近しい内容だと思います。

バッチ処理 / ストリーミング処理
音声データは、「音声は時間軸を持つ連続データである(時系列データ)」という性質があります。そのため、バッチ処理だけではなく、時間経過と共に逐次処理をするストリーミング処理を検討する機会も増えると思います。
僕自身も、今回作成したアプリでは、クライアントとサーバ間で、音声データをストリーミング送受信する仕組みを導入しました。
バッチ処理とストリーミング処理の違いは、ざっくりと以下の認識です。
バッチ処理(Batch Processing)

音声データを「ファイル」としてまとめて処理するイメージです。
例えば、クライアント側でユーザの声を録音する場合、以下のようなイメージです。
- クライアント側で録音を完了する。
- 完了後、ファイルとして一括送信し、サーバ側で処理を行う。
一括処理のため、比較的設計がシンプルになりますが、音声の録音が完了するまで次の処理が進まないことには注意が必要だと思います。
ストリーミング処理(Streaming Processing)

リアルタイムにデータを少しずつ処理するイメージです。
データを「チャンク(小分けのブロック)」に分割して処理を進めます。
例えば、クライアント側でユーザの声を録音する場合、以下のようなイメージです。
- 音声データをチャンクに分ける。
- 録音しながら、逐次サーバにチャンクを送信し、処理を並行して進める。
- 録音が終わる頃には、ほぼ処理が完了している。
逐次音声データを送り、リアルタイムに近い処理が可能ですが、一括で送るよりも設計は複雑になりそうですね。
APIでの利用
APIで音声データを利用するケースを考えてみましょう。
今回は、「クライアント」で音声を録音し、「クライアント」から「サーバ」へ録音した音声データを送り、「サーバ」側で音声データの何かしらの処理をするケースを想定します。
REST APIで送る
まずは、REST APIでサーバ側に送るケースを考えます。
今回は、Multipartで送るケースではなく、JSONで送信するケースを想定して、ざっくりとした処理の流れで考えてみましょう。(バッチ処理を想定してます。)
JSONで送るので、Base64でエンコードし、テキストデータ化して送る必要があります。

- クライアント
- ユーザの音声を録音する
- 録音が完了したら、音声をBase64でテキストデータにエンコードする
- JSONにテキストデータを載せる
- サーバ側にJSONを送る
- サーバ
- jsonを受け取る
- テキストデータをBase64でデコードする
- 音声データとして目的の処理を行う
JSONにテキストデータとして音声データを格納するイメージは以下の通りです。
以下のkey「audio_data」のvalue「UklGRiQAAA...」が、Base64でエンコードした音声データのイメージです。
{
"filename": "audio.wav",
"format": "wav",
"sampling_rate": 16000,
"bit_depth": 16,
"channels": 1,
"audio_data": "UklGRiQAAABXQVZFZm10IBAAAAABAAEAQB8AAIA+AAACABAAZGF0Y..."
}
音声データが、バイナリではなく、文字列で表現されている状態って、なんか不思議ですね。
JSONベースで簡単に送信できるメリットがあるものの、Base64によりデータサイズや処理コストの増加のデメリットもあります。
バッチで処理するケースには向いてそうですが、リアルタイム性を重視するアプリの場合は、gRPC等を利用する方が良さそうですね。
RPCで送る
次は、RPCでサーバ側に送るケースで考えます。
今回は、gRPCのクライアントストリーミングで、音声をチャンク単位で、逐次送るケースを想定し、ざっくりとした処理の流れ考えてみましょう。

- クライアント
- ユーザの音声を録音を開始する
- 音声を小さなチャンク(バイト列)に分割
- gRPCストリームでチャンクをサーバへ送信
- 録音が完了したら、残りのチャンクをサーバへ送信
- サーバ
- チャンクを受信
- 届いたチャンクから順に先に次の目的の処理を行う
gRPCを利用する場合は、事前にprotoファイルを定義します。
今回は、クライアントからサーバへの単一方向のストリーミングを想定しますが、gRPCでは双方向ストリーミングも可能です。
以下の「stream AudioRequest」により、ストリームで音声データをバイナリデータ(bytes)として送信することを定義しています。
syntax = "proto3";
service AudioService {
// クライアントストリームRPC
rpc StreamAudio (stream AudioRequest) returns (AudioResponse);
}
message AudioRequest {
bytes audio_chunk = 1; // 音声データのチャンク
}
message AudioResponse {
string responce = 1; // テキストベースでレスポンス
}
gRPCのストリーミングを使えば、逐次音声データを送れるため、音声がすべて録音できてなくとも、録音できたデータから処理可能です。また、base64を利用せずとも、バイナリのままデータも送れるため、クライアント側でのbase64エンコード処理時間・サーバ側でのbase64デコード時間も短縮でき、リアルタイム性を重視するアプリに向いてそうです。
終わりに
今回は、音声データをアプリで利用したときに、勉強した内容をざっとまとめました。
テキストや図でまとめることで、改めて音声データの処理の流れがよりクリアになってと思います。また、バイナリデータの中身まで見たりと、少し深いレイヤーに踏み込んで理解が深まったことも良きでした。
音声データを使ってみて「時間軸を持つ連続したデータである」という音声データの性質は、ストリーミング処理をより意識して勉強するきっかけとなり、テキストデータや画像データとは違う性質を実感する良い経験でした。
ストリーミング処理を勉強したい、という方は、まずは音声データを使って遊んでみると、新しい気づきを得られるかもです!
Discussion