Stanford NLP with Deep Learning Lecture12のまとめ
1.はじめに
今回も引き続きStanford大学がYoutubeで公開しているMOOC[NLP with DeepLearning]の12回についてまとめていきます。
今回の内容は文章生成タスクに特化した内容になっており、現在Stanford大学でポスドクであるAntoine Bosselutさんによる講義でした。
GPT-3.5や4が登場する前の2021年の講義なので最新の技術等については触れないですが、NLGタスクのコアとなる部分の解説はとてもためになる講義でした。
2.NLGとは?
まずはじめにNLG(自然言語生成)とは何かについて述べていきます。
[NLG(自然言語生成)]
:NLPタスクの一つで人間の需要に沿った書き言葉や話し言葉の自動生成に焦点を当てたシステム設計を行うタスクのこと
ex) 機械翻訳,対話システム,要約タスク, etc...
この講義では主に自己回帰の文章生成モデルについて話していました。
よって、このモデルの目的は
「あるt地点において、それ以前のトークンを入力としてt地点のトークンを予測すること」と言えます。
これを数式で表すと以下のようになります。
<数式>
これを生成したい単語数になるまで逐次的に繰り返し行なっていきます。
3.NLGにおけるDecoding
基本的な部分の次はNLGにおける重要部分であるDecoderについて述べていきます。
3-1:NLGモデルにおける損失と課題
NLGも学習を行う必要があるので損失が以下のようにして算出されます。
<損失>
以前Lecture7でも書きましたが、NLGにおいて予測結果を得る方法として最もシンプルな方法である最も確率が高い単語を選択する
以下の手法や
Beam Searchが挙げられると思います。
ただ、これらの手法を実際にNLGタスクに用いたとき場合によってはあるt地点以降で同じ単語の反復が起きることがあります。
これは自己回帰モデルであるがゆえのものにはなりますが繰り返し同じ単語を生成していくことで(2)の損失が減少していくことが原因となっています。
この反復を減らすための対処法は
まず単純な手法であるn-gram単位での反復を禁止する手法が挙げられます。
ただ、これだと本質的な解決にはなっていないのでより高度な対処法も存在します。
-
Minimize embedding distance between consecutive sentences
連続する文章間の距離を最小にするようにEmbeddingを調整する手法
ただ、この手法は文章内における反復に対して弱いという弱点があります。 -
Coverage Loss
coverage vectorというAttentionのかかり具合を含むベクトルを損失計算に用いることで、繰り返しが起きたときに損失が小さくならないようにする手法([2]参照) -
Unlikelihood Loss
尤度関数を用いた損失ベースではなく、反復が起きそうなときにペナルティーを課す損失を用いる手法
これらを用いることで反復を最小限におさえることを実現しています。
ただ、NLGにおいてそもそも貪欲法を使うことが正しいのかという部分も話されていて、図1で示す通り実際の人間の思考は確率以外の要素も大きく、貪欲法では再現できていないことがわかります。
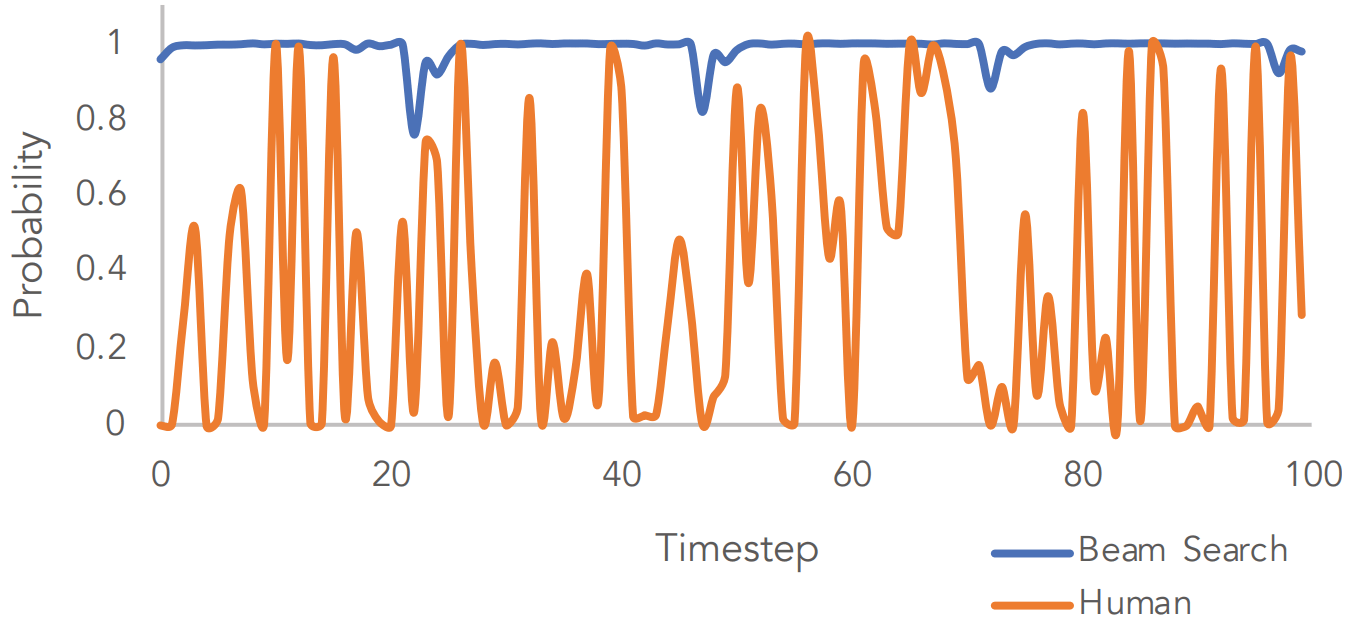 図1)貪欲法(BeamSearch)と人間の文章生成時の確率の違い([1]より引用)
図1)貪欲法(BeamSearch)と人間の文章生成時の確率の違い([1]より引用)
3-2:DecoderにおけるSampling
実際の生成時には、予測結果の確率分布をもとにランダムにSamplingを行う手法がとられています。しかし、語彙全てからランダムに取得するとなると以下のような問題点があります。
- 語彙中の単語数が多すぎて、各単語における確率が分散してしまう
- Contextと親和性のない単語にまで確率が割り当てられる
なので課題としては
- 選ばれて欲しい単語をグループ化して、そうでない関係ない単語に対しては無視したい
ということだと考えられます。
この方法の解決策としてTop-k Sampling
<Top-k Sampling>
:確率分布中のトークンのうち、出現確率上位k個の中からSamplingする手法
⭐️kの扱い
-
kを小さい値にする
汎用的ではあるものの面白みのない安定した出力を得ることができる -
kを大きい値にする
多様性に富んだ出力が得られる一方で、不自然な出力を出すという危険性がある
ただ、この手法にも問題点がありました。
図2で示したような確率分布の形状による実行速度の差です。
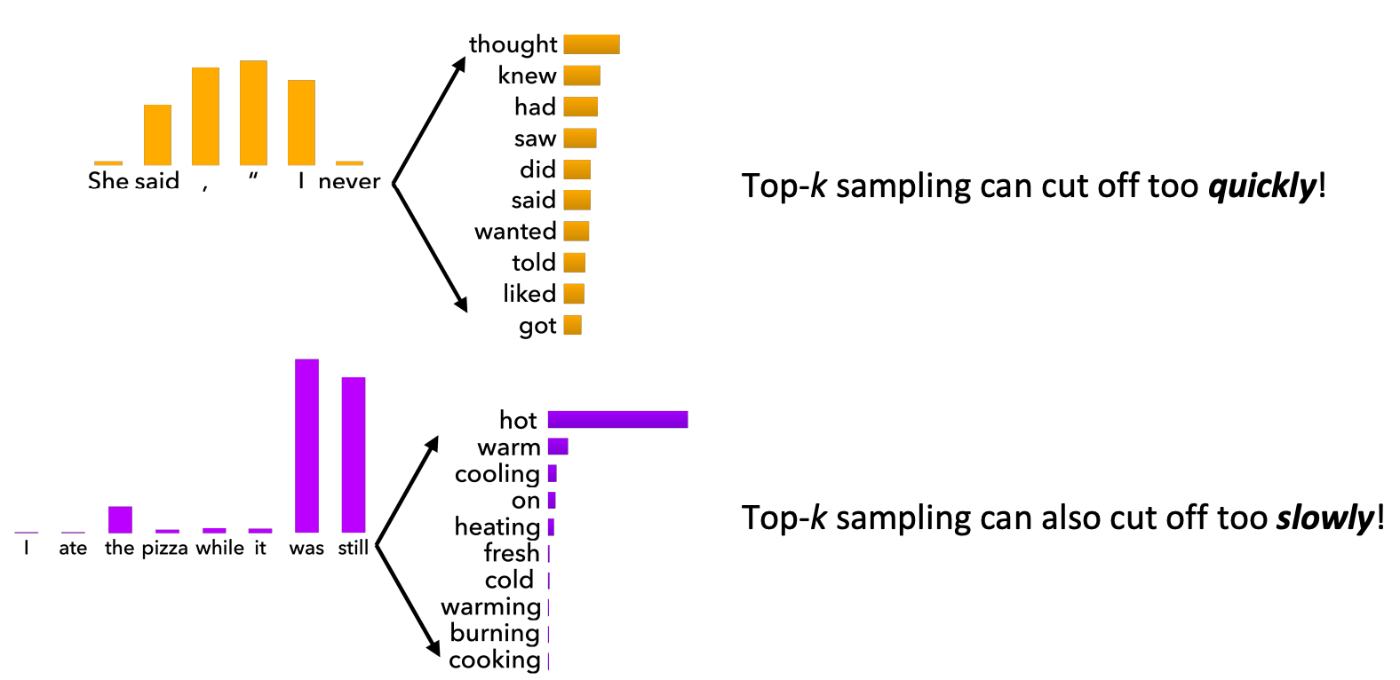 図2) 確率分布の違いによる実行速度の差([1]より引用)
図2) 確率分布の違いによる実行速度の差([1]より引用)
この解決策としてTop-p Samplingがあります。
<Top-p Sampling>
:確率の合計がpになる地点までの単語をSamplingする手法
この手法によって確立分布の形状ごとに適したkが採用されることで図2のような問題を解消できました。
3-3:Random性のScalling
式(1)から、確率分布の算出にはSoftmax関数が用いられていることがわかります。
ここにハイパーパラメータであるtemperature(
<数式>
⭐️
-
\tau
P_t -
tau
P_t
3-4:Decoding能力の向上
Re-balancing
NLGのDecoder部分の課題の一つとして、モデル内における分布の調整がきちんと行われているかということが保証されていないという点がありました。
これに対する解決策としてはre-balancing distributionsという手法があります。
<re-balancing distributions>
:n-gramフレーズによる統計的機械学習によって得られた確率分布を外部情報としてモデル内における確率分布(
この手法の概要は図3の通りです。
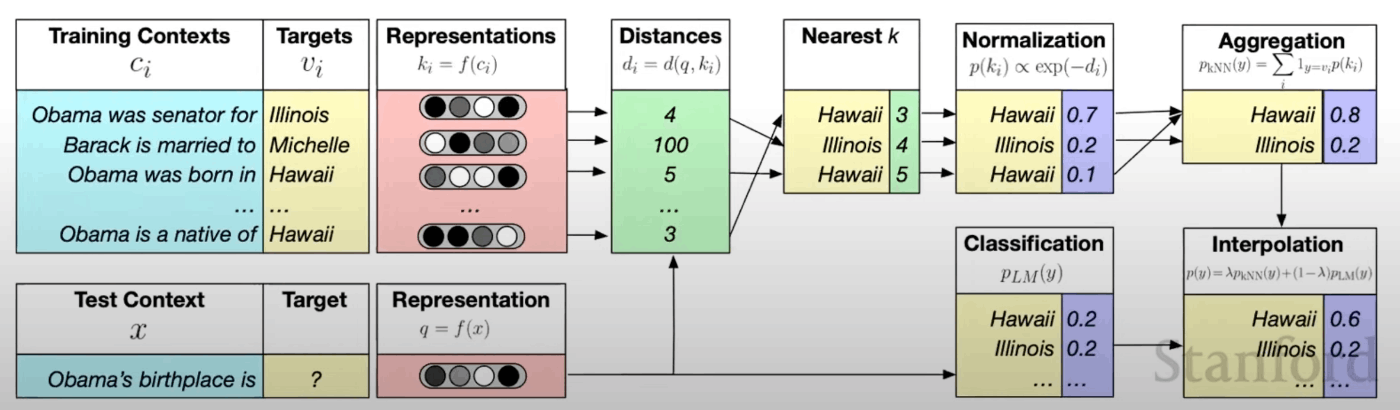 図3) re-balancing distributions([1]より引用)
図3) re-balancing distributions([1]より引用)
- 学習データから得られたフレーズを溜めこむデータベースを持つ
- Decoding時にデータベース内から類似している単語を探し出す
- n-gramフレーズによる手法で算出された確率分布を用いてバランス調整をする
これによってある程度モデル内部における確率分布の様子がある程度保証できるようになりました。
また、このバランス調整の考え方を活かした方法としてBack Propagation-based distribution re-balancingがあります。
<Back Propagation-based distribution re-balancing>
この手法はSoftmaxで得られた確率分布を解きたいタスクに応じたEvaluatorを用意し、評価対象とすることでバランス調整を行います。(図4参照)
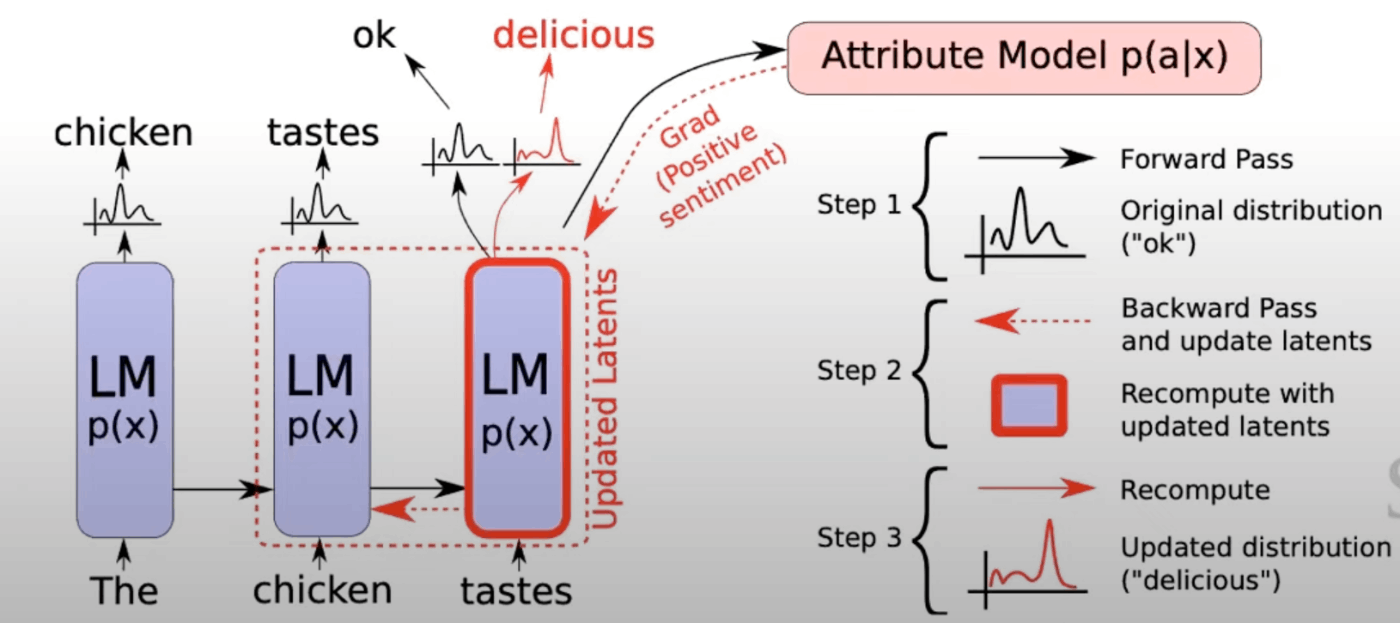 図4) Back Propagation-based distribution re-balancing([1]より引用)
図4) Back Propagation-based distribution re-balancing([1]より引用)
- 順伝播を行う
- Evaluatorを用いて、逆伝播を行う
- 確率分布を更新していく
Re-ranking
もう一つの課題としては、出力が納得いかないぐらい悪い時どうするか?ということがありました。
モデルの調整以外の手段として、Re-rankingがあります。
<Re-ranking>
:スコアを計算して出力に対してランキング評価を行うことで、再調整する手法
(並列処理を用いることでコストの削減も可能)
- いくつかの文章をDecodeする
- 作成した文章の質を評価するスコア関数を定義する
- 得られたスコアをもとにランキング付けをする
4.NLGにおける学習について
ここからはNLGモデルにおける学習とその課題について述べていきます。
(2)式でNLGモデルにおける損失を示しました。
この損失を最大化していくことでNLGモデルは学習を行なっています。
ただ、この方法はいくつか課題があります。
- 図1でも示した通り、人間本来の文章生成過程と異なっているため生成した文章の多様性を阻害する可能性があること
- Exposure biasの存在
4-1:Unlikelihood Training
1.への対抗策の一つとしてUnlikelihood Trainingがあります。
これは通常の目的関数
<Unlikelihood Training(数式)>
Unlikelihood Trainingを採用したNLGモデルのt地点における目的関数
4-2:Exxposure biasと強化学習
Exposure bias
文章生成において学習時には「Teacher forcing」が用いられています。
この手法は学習が安定する一方で、図1で示したように人間による単語選択と機械による単語選択では誤差があり文章生成時にはこの誤差が累積してしまうという問題が発生します。(図5参照)
文章生成時に生じるこの誤差のことをExposure biasといいます。
 図5)Exposure biasについて
図5)Exposure biasについて
このExposure biasに対する対抗策として以下の二つが例として挙げられていました。
-
Sequence re-writing
:プロトタイプとして人間によって書かれた文章を用いて学習し、その後プロトタイプの文章ないのトークンを入れ替えたり、取り除いたりして手を加えた文章をもう一度入力文章として学習に用いる手法。 -
Reinforcement Learning(強化学習)
State:調整前のモデル
Actions:生成した文章
Policy:Decoder部分
Rewards:定義したスコア
これら四つを用いてモデルの挙動を評価し、調整していく手法
この二つのうち、強化学習について次は述べていきます。
Reinforcement Learning(強化学習)
以下の目的関数が強化学習の中では基本的な部分として用いられがちです。
この目的関数内における二つの関数にはそれぞれ異なる役割を持ちます。
-
\log P(\hat{y_t}\ |\ \lbrace y^* \rbrace ; \lbrace \hat{y} \rbrace _{<t})
:単純に出現確率の高いトークンを出力として選択できる -
r(\hat{y_t})
:上式の制約としてrewardであるスコアが上がる場合というのを課すことができる。
ここで生まれる疑問がスコアって何?ってことだと思います。
答えとしては「評価関数(BLUEやROUGE etc...)を用いる」です(もちろん例外もあります)
ただ、この評価関数を設定する際の注意点として
「ただ評価するための関数ではなく、あくまでモデルの最適化に用いるものである」という認識をもって選択する必要があることが挙げられます。
この強化学習を用いたExposure biasへの対処法としてかなり強力ですがデメリットもちろんあります。
- 強化学習を行うまえに教師あり学習による事前学習が必要である
- rewardに対してベースラインを設定する必要がある
- rewardに対してモデルがずるして学習し、欲しい結果にならない時がある
ただこれらを抜きにしても強化学習はとても強力ですね、、。(いずれきちんと理解したい分野の一つです)
5.NLGシステムの評価について
NLGには大きく分けて3つのタイプがあります。
- Content Overlap Metrics
- Model-based Metrics
- Human Evaluations
これらについて一つずつ見ていきます。
5-1:Content Overlap Metrics
これは名前の通り、生成文と教師データがどのくらい共通しているかについて評価する手法です。
この手法は「早くてある程度有力である」という特徴ゆえに広く用いられている評価方法です。
- N-gram overlap metrics
:単語の被っている数で評価する手法。機械翻訳や要約、対話、物語生成といった入力と出力の文章が異なるタスクにおいては全く使えないほど直感と異なる評価となるため注意が必要
ex) BLUE, ROUGE, METEOR, CIDE etc... - Semantic overlap metric
:文章から得られる単語表現の関係を表すグラフ等を用いて評価する手法。
ex) DYRAMID, SPICE, SPIDE etc...
5-2:Model-based Metrics
モデルが学習した単語や文章の表現を用いて、生成文と教師データの類似度を評価とする手法
この手法はContent Overlap Metricsと比較して以下のメリットがあります。
- 単語の重なりだけでなく、ベクトルによる文章表現を用いているので意味の類似度も考慮できる
- 期待していた答えにならなくても学習によって修正可能である
この手法は以下の2種類に分けられます。
- Word distance funcrtions
- Beyond word marching
Word distance funcrtions
単語間のベクトル表現における距離を用いて評価する方法
ex)
-
Vector similarity
:テキスト間の意味の類似度を距離を用いて測り、その類似度で評価する方法
(Embedding average, MEANT, etc...) -
Word Mover's Distance
:テキストを構成する単語のベクトル表現を用いて、二つのテキストの類似性を評価する方法 -
BERT SCORE
:BERTによって生成された文脈も考慮されたベクトル表現を用いて、cos類似度で類似度を算出する方法
Beyond word marching
-
Sentence Movers Simirality
:Word Mover's Distanceから発展した評価方法で、連続する複数の文章とある一つの文章間における類似度をRNNsから得たベクトルで評価する方法 -
BLEURT
BERTをベースにした回帰モデルを用いてスコアを算出する方法
この方法におけるスコアとは、参照もとの文章の意味が伝わっているかどうかと生成した文章が文法的に正しいかを評価している
5-3:Human Evaluations
多くの計算で求められる評価指標は、人間による評価には及ばないとされており実際最新のNLGの論文の75%近くでは人間による評価を用いて評価が行われています。
ただ、人間による評価ももちろんデメリットがあります。
- 評価が終わるまでに時間も費用もかかるという点
- 評価を行う人によって、結果に差が出やすいという点
ようするに計算による評価の数字のみを信じるのではなく、人による評価であったりモデル内の、吟味がきちんと行う必要がある!!ということですね。
一応、この後に倫理観に関する章もあるのですが他の授業でやりそうなので割愛します。
6.おわりに
今回はNLGに関するモデルというより、内部の理解度を深める講義内容でした。
この講義自体が2021年のものなので、GPT-4やLlama2の登場でまた内容が大きく変わってそうですね、、
でも、基本的な部分については共通していると思うので今回の授業でできた強化学習による制限のことであったり評価手法についてはしっかり理解を深めて、現在の発展した手法を学習する時につまづかないようにしたいですね
ps)LangChainを最近触って遊んでいるのですが、あれすごいですね
7.参考資料
[1]Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 12 - Natural Language Generation
[2]'Get To The Point: Summarization with Pointer-Generator Networks' See et all. 2017
Discussion