Stanford NLP with Deep Learning Lecture9のまとめ(Self-Attention編)
1.はじめに
本稿も引き続きStanford大学がYoutubeで公開しているオンライン講義の内容をまとめていきたいと思います。
このLectureからTransformerに入るわけですが、Self-Attention部分とTransformer部分を分けた方が分量的にも内容的にもスッキリしそうだなと思ったので分けて記事を書いていきたいと思います。なので今回はSelf-Attentionにフォーカスを当てた記事となっています。
2.Self-Attention
先述した通り、今回はTransformerで採用されているAttention機構であるSelf-Attentionについて述べていきます。
2-1:再帰モデルの課題
まず、Self-Attentionについて述べていく前に再帰モデルの課題を思い出していきます。
再帰モデルの課題としては、以下の二つが挙げられます。
- Linear interaction distance
- Lack of parallelizable
(1) Linear interaction distance(線形の相互距離)
文章は一般的には近い単語との依存関係が強いとされていますが、時に代名詞など位置が離れていたとしても関係を持つ単語が存在します。
そんな時、再帰モデルは文章を逐次的に処理していく関係上どうしても系列長が長くなるにつれて長距離の関係性を見ることが困難になってしまいます。(勾配問題によって)
(2) Lack of parallelizable(並列処理性能の欠如)
自然言語処理において処理速度は重要で系列長や文章数が大きくなるにつれてGPUを用いるために並列処理を用いることが多々あります。
そんな時再帰モデルは(1)の時同様、逐次的に処理を行う関係上並列で処理を実行することが不可能という課題があります。
2-2:Word Windowモデルの課題
講義では再帰モデル以外にもWindowを用いたモデルも比較として紹介していました。
Word Windowモデル
:文章をwindowと呼ばれる指定した単語数の中だけで意味を理解しようというモデル(図1参照)
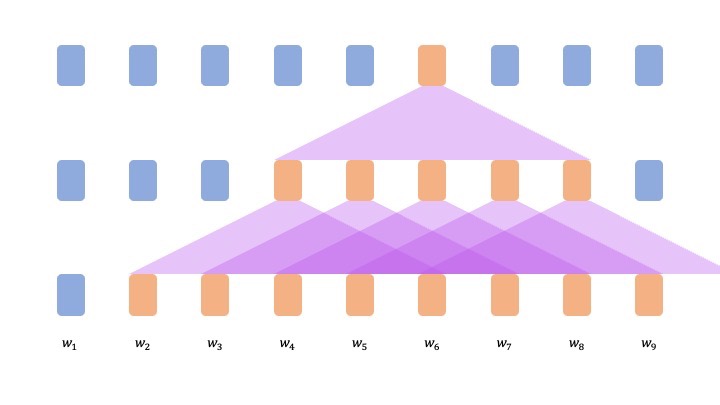 図1) Word Windowモデルの挙動(層数2, window数5の時)
図1) Word Windowモデルの挙動(層数2, window数5の時)
このモデルの長所としては系列長の長さに関係なくwindow数によって決まり、並列処理も可能となっています。
ただ、その一方で図1を見て分かる通り意味を算用する際に全ての単語を参照できない可能性があり、再帰モデルの時と同様長距離におよぶ関係性の把握が困難であるという課題があります。
2-3:Self-Attention
2-1, 2-2ではそれぞれのモデルにおける課題を見てきました。
これらを解決する手段として提案されたのがAttentionとなっています。
Attentionを簡単にいうと単語表現をquery、情報の参照元をvalueとして扱い文章の理解を行っていく手法のことを指します。
このAttentionは再帰モデルwindowモデルとは違い以下の二つを可能にしました。
- 並列処理が可能
- 系列長に関わらず一斉に処理を行うので長距離の依存関係も学習できる
さらにこのAttentionを拡張したSelf-Attentionについて述べていきます。
Self-Attention
:Attentionの処理において入力をquery,key,valueという三つに分けて単語表現を獲得していくAttention機構
以下のようにしてSelf-Attentionは単語表現を獲得します。
数式としてのSelf-Attentionを見てきました。ではこのSelf-AttentionがシンプルなDot-Product Attentionと異なる点を以下に示していきます。
- 全文を元にAttention weightを決めておらず文章中に出現する個々の単語の関係性を考慮に入れてAttention weightを決めている
- Attention機構は単なる全結合順伝播ではないという帰納バイアスを有している
これらによってより柔軟な単語表現の獲得を実現しました。
3.Self-Attentionの課題
2ではAttention、ひいてはSelf-Attentionの優れている点について述べていきました。
並列処理も可能になり、長距離間の係り受けも学習できるようになったことで一見NLPの覇権を再帰モデルから取って代わったかのように思えますがAttentionにも以下の問題点が存在していました。
- Sequence order(位置情報の欠如)
- Not non linearity(非線形ではない)
- Masking(学習時のカンニング)
3-1:Sequence order(位置情報の欠如)
再帰モデルが左もしくは右から順番に位置情報を元に処理を行っていくのに対して、Attentionは一つの単語の表現を得る際に全ての単語を参照します。
この時単語の位置は考慮されておらずどんな単語が文章中に存在しているかということをもとに学習します。
よって、仮に単語の位置が変わろうと同じ結果が得られてしまうという問題が生じてしまいます。
この問題に対してはシンプルに位置情報をベクトルとして付与すればいいじゃん!!という考えのもと解決されました。
そのベクトル化の際にはTransformerにおいては以下式のように条件によって変わるsincos曲線が用いられています。
この方法のメリットしては二つ挙げられています。
- 系列長が長くなっても対応可能
- Periodicity indicates that maybe “absolute position” isn’t as important
この訳し方がいまいち分かりませんでした、、、誰かわかる方いれば教えてください。
周期性はまだしもこの手法は絶対位置なのでは?と思いました。
デメリットとしては
- 外部のデータに合わせて学習できない
ことが挙げられていました。
このデメリットに対しては、位置ベクトル
3-2:Not non linearity(非線形ではない)
下図と2-3で示したAttentionの式の通り、これまで解説してきたAttentionは出力であるoutputがAttention weightとvalueの重み付き和でした。
このままでは深層学習モデルなのに出力が非線形でないことを意味しています。
 図2) 出力が単なる重み付き和のAttention([1]より引用)
図2) 出力が単なる重み付き和のAttention([1]より引用)
この問題を解決するためにAttentionの後に以下式で定義されるFeed-Forward Networkを加えることで非線形に変換できるような工夫を取り入れました。(図3参照)
 図3) FFNを加えたSelf-Attention([1]より引用)
図3) FFNを加えたSelf-Attention([1]より引用)
3-3:Masking(学習時のカンニング)
最後にMasking作業について解説していきます。
再帰モデルは何度も言うようですが、再帰モデルなので文章において順番通り逐次的に処理を行っていきます。そのため現在の入力に対して予測する未来の情報を含んでおらずカンニングの心配がありませんでした。
しかし、Attentionは入力全てを参照して単語表現を獲得するので現在の単語の予測に対して未来の情報を参照してしまいます。これでは汎化性能が担保されません。
この問題への対象方がMaskingです。
Maskingは以下式のように現在見ている単語より後の単語に関するAttention weightを-♾️とすることで影響をなくそうという手法です。
これをより分かりやすく図で表すと下図のようになります.
 図4) Maskingの様子([1]より引用)
図4) Maskingの様子([1]より引用)
4.まとめ
Self-Attentionだけでも十分すぎるボリュームになりましたね、、
次はいよいよTransformerについての記事を作成していきたいと思います。
また、Lecture9からNLPがめっちゃ好きそうなおじいちゃん教授から画像を主に先行しているらしいTAの若い方に変わりました。この人はこの人でおもしろいのでこの研究室自体すごい楽しそうですね。
5.参考文献
[1]Stanford CS224N NLP with Deep Learning | Winter 2021 | Lecture 9 - Self- Attention and Transformers
Discussion