【論文紹介】A foundation modelfor the Earth system:気象や環境等の時空間データ向けの基盤モデル
こんにちは!よっしゃと申します。
今回は、気象や環境等の時空間データを対象とした基盤モデルのモデルの論文「A foundation modelfor the Earth system」の紹介します。
地球システムデータとは(天候、海洋、大気...etc)
地球システムデータの特徴
- 多次元:緯度経度(空間)×気圧階層(高度)×時間方向を持つ多次元構造のデータ
- 多変数:大気、海洋、陸面、氷床など、多様な物理現象を含む
- ビッグデータ:数年、数十年の観測、日本全域あるいは地球全体の観測データ
扱う上での難しさ
- 異種データの統合:異なる変数(気温、風、湿度、波高、大気化学成分など)でそれぞれの(水平・鉛直・時間)解像度がバラバラ
- 高次元性:全球かつ高解像度データは超大規模
- 物理的な制約:時間的、空間的な連続性や質量・エネルギー保存などの物理法則を満たす必要がある

論文概要
- タイトル:A foundation model for the Earth system
- 公開日:2025/5/21(オンライン)
- 機関:Microsoft Research
- モデル名:Aurora(transformerベースで約13億パラメータ)
要旨:
大気、海洋、波浪、大気化学など地球システム全体を対象とした基盤モデルAuroraを提案しています。Auroraは多様なデータを統合的に扱える構造で、多様な地球物理データを100万時間以上のデータでPre-Trainingしており、天気(0.1°高解像度)・熱帯低気圧の進路・大気汚染・海洋波といった幅広い予測タスクで応用可能であることを示しました。主に高解像度天気予報や台風追跡、大気汚染解析などで、SOTA級の性能を高い計算効率で達成し、各タスクに対して低コストでファインチューニング可能な地球システム基盤モデルです。
Auroraモデル構造(概要)
Auroraはどの地球システム変数でも、望む解像度で予報できることを目標に設計された下記3つのモジュールで構成されている機械学習モデルです。

1)3D Perceiver encoder:
異なる変数・解像度・気圧面を統一し、物理的意味(気圧の階層性、地表と大気の違い、時空間的な連続性...etc)を保ったまま共通の3D潜在空間に集約する柔軟なエンコーダです。
2)Multiscale 3D Swin Transformer U-Net:
3D Perceiver encoderで作成した3次元潜在変数を数値シミュレーション用の仮想的な3次元メッシュとして扱い、時間発展(シミュレーション)する役割のバックボーンです。
3)3D Perceiver decoder
前段で時間発展させたシミュレーション結果(3次元変数)を物理的な意味を持つ数値に復元するデコーダーです。
LoRA
長期間予測タスクのFine-Tuningで用います。(後述)
3D Perceiver encoder

- 大気に関する変数(時空間+気圧)、静的な地形や陸海マスク等(空間)、地表に関する変数(時空間)の3種類の入力をそれぞれパッチ化し、Perceiver型のクロスアテンション層で少数の潜在変数(気圧レベル)へ集約。
- Fouier encodingにより潜在変数に位置(緯度経度)・パッチ面積・時刻などの情報を付与して3D潜在テンソルを構築。
ここでPerceiverとは、マルチモーダルなモデルでないにも関わらず、モダリティへの依存の少ないアーキテクチャで高精度を出せる特徴を持つモデルのことで、Cross Attention層やLatent Transformer層等があります。これにより解像度や変数、気圧レベルが異なる異種のデータを普遍的に扱っています。
Multiscale 3D Swin Transformer U-Net
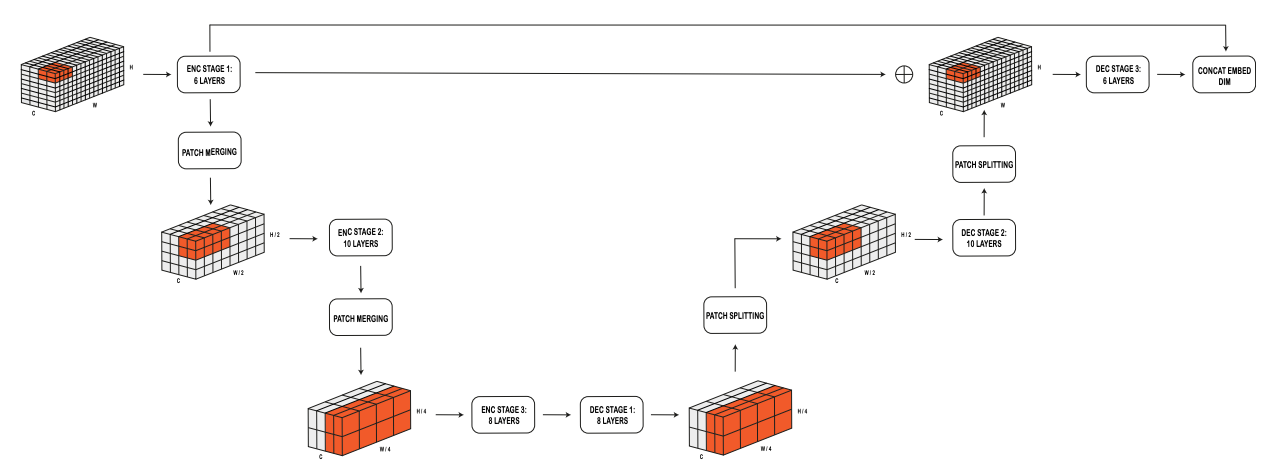
本モジュールは全体的にUネットのような構造になっており、前半は解像度を1/2ずつ徐々に縮小していき、後半は解像度を2倍ずつ徐々に拡大していきます。対応する解像度のエンコーダと出力をスキップ接続することで様々なスケールでのシミュレーションを可能にします。
3D Perceiver decoder

3D Perceiver encoderとは逆の処理を行うことで、シミュレーション後の3D潜在表現を任意の出力変数・気圧レベルにデコードし、標準の緯度経度格子へ復元します。
まとめ:**入力(任意の変数・解像度・気圧)→3D潜在→出力(任意の変数・解像度・気圧)**という柔軟なI/Oが可能。
学習戦略
問題設定
現在の状態から次の時刻の状態を出力するシミュレータΦを学習します。
将来の長期的な予測は、このシミュレータを繰り返し適用する自己回帰的な枠組みで行う。(ロールアウトする)

Xt:ある時刻tにおける大気(地表含む)の観測状態
目的関数
今回の学習は基本的には変数・場所・気圧・時間毎に予測値と正解値(1ステップ後の物理量)とのMAEを計算します。また、緯度によるグリッド面積差(cos重み)や、変数別・層別の重みで、次元の違い等の調整を行っています。

α:変数毎の重み係数
β:時間的な重み係数
w:空間的な重み係数
Pretraining
1ステップ6時間での次ステップ予測を目標とし、150kステップのトレーニングを実施します。
- データセット: 100万時間を超える多様な地球システムデータ(再解析・予報・解析・気候シミュレーション)
- 約480万フレームを処理
Short-lead-time Fine-Tuning
事前学習済みのAuroraモデルを各タスクに適応するために、短いリードタイム(1〜2ステップ)の予測を使ってモデルを微調整します。短いリードタイムの予測ではモデル全体の重みを更新します。
Long-lead-time / roll-out Fine-Tuning
長期のリードタイムの予測の際に、モデル全体の重みのFine-Tuningは計算負荷が大きいという課題がありました。そこで長期のリードタイムの予測では下記の工夫によって、省メモリ・省計算でのFine-Tuningを実現しています。
- LoRA(Low Rank Adaptation):バックボーンのSelf-Attentionに含まれる線形層を低ランク行列で補正。
- Pushforward Trick:最後のステップだけで勾配を計算する。
- Replay Buffer:ロールアウト中に得られたモデル生成の中間状態を短期的にためて再利用する。
実験結果
応用例1)台風・ハリケーンの進路予測
2022〜2023 年の世界全体の熱帯低気圧データセット(空間解像度:0.25°)でFine-TuningしたAuroraで台風の進路予測を検証しました。

- 世界4つの流域の公式予報※を上回る性能を示した。(図4-a)
- 台風のような局所的で進路が大きく変わるような未知の課題であっても高い性能を示した。(図4-b)
- 機械学習モデルで最大5日間先の熱帯低気圧の予測で公式予報を上回ったのはこれが初めて。
※国立ハリケーンセンター (北大西洋および東太平洋)、中国気象局・台湾中央気象局合同台風警報センター、日本気象庁 (北西太平洋)、オーストラリア気象局 (オーストラリア地域) が発表した世界 4 つの流域の公式予報
応用例2)高解像な天気予報
2016年から2022年までの0.1°IFS HRES※解析データに合わせてAuroraをFine-Tuningして天気を予測しました。

- 0.1°の解像度でもAuroraはIFS HRESを広範に上回る精度(92%のターゲットで優位、最大24%RMSE改善)
- 他のAIモデル(FourCastNet/GraphCast/Pangu-Weather)と比較して非定常的な気象イベント(熱波、ゲリラ豪雨、ハリケーン、寒波等)においても急峻なピークの再現も可能なことが強み。
Auroraは他にも大気汚染物質や波浪予測などの様々なタスクにおいて予測を行えていました。
更に、推論速度が高速である特徴があるため、従来の数値モデルに比べてコスト効率が非常に高い運用が可能です。
Auroraで推論を実行してみた
AUroraのコードが公開されているGithub内のdocumentationを参考に、学習済みのAuroraで天気予報をさせてみました。下記に推論コードを示します。
コードの概要
2023年1月1日のERA5データを0.25度の解像度でダウンロードし、このデータで Auroraを実行する。AuroraのFine-Tuningバージョンは、特にIFS HRES T0でのみ動作するため、この例ではFine TuningされていないバージョンのAuroraを使用しています。
データのダウンロード
データのダウンロードにはClimate Data Storeにアカウントを登録してAPI ikeyを取得する必要があります。
api_key = "□□□□□"
content = f"""url: https://cds.climate.copernicus.eu/api
key: {api_key}
"""
with open("/root/.cdsapirc", "w") as f:
f.write(content)
!cat /root/.cdsapirc # 内容確認(キーはマスク推奨)
from pathlib import Path
import cdsapi
# データダウンロード先
# デフォルトは ~/downloads/era5
download_path = Path("~/downloads/era5")
# CDS APIクライアント作成
c = cdsapi.Client()
# ダウンロードパスを展開し、ディレクトリ作成
download_path = download_path.expanduser()
download_path.mkdir(parents=True, exist_ok=True)
# 静的変数ダウンロード
# static.nc が無ければ実行
if not (download_path / "static.nc").exists():
print("Downloading static variables...")
c.retrieve(
"reanalysis-era5-single-levels", # データセット名
{
"product_type": "reanalysis", # プロダクトタイプ
"variable": [ # 変数リスト
"geopotential", # ジオポテンシャル
"land_sea_mask", # 陸海マスク
"soil_type", # 土壌タイプ
],
"year": "2023", # 年
"month": "01", # 月
"day": "01", # 日
"time": "00:00", # 時間 (UTC)
"format": "netcdf", # ファイル形式
},
str(download_path / "static.nc"), # 保存先ファイルパス
)
print("Static variables downloaded!")
# 地上変数ダウンロード
# 2023-01-01-surface-level.nc が無ければ実行
if not (download_path / "2023-01-01-surface-level.nc").exists():
print("Downloading surface-level variables...")
c.retrieve(
"reanalysis-era5-single-levels", # データセット名
{
"product_type": "reanalysis", # プロダクトタイプ
"variable": [ # 変数リスト
"2m_temperature", # 2m気温
"10m_u_component_of_wind", # 10m風速 (東西)
"10m_v_component_of_wind", # 10m風速 (南北)
"mean_sea_level_pressure", # 海面気圧
],
"year": "2023", # 年
"month": "01", # 月
"day": "01", # 日
# 時間リスト (UTC)
"time": ["00:00", "06:00", "12:00", "18:00"],
"format": "netcdf", # ファイル形式
},
str(download_path / "2023-01-01-surface-level.nc"), # 保存先ファイルパス
)
print("Surface-level variables downloaded!")
# 大気変数ダウンロード
# 2023-01-01-atmospheric.nc が無ければ実行
if not (download_path / "2023-01-01-atmospheric.nc").exists():
print("Downloading atmospheric variables...")
c.retrieve(
"reanalysis-era5-pressure-levels", # データセット名
{
"product_type": "reanalysis", # プロダクトタイプ
"variable": [ # 変数リスト
"temperature", # 気温
"u_component_of_wind",# 風速 (東西)
"v_component_of_wind",# 風速 (南北)
"specific_humidity", # 比湿度
"geopotential", # ジオポテンシャル
],
# 圧力レベルリスト (hPa)
"pressure_level": [
"50", "100", "150", "200", "250", "300", "400", "500",
"600", "700", "850", "925", "1000",
],
"year": "2023", # 年
"month": "01", # 月
"day": "01", # 日
# 時間リスト (UTC)
"time": ["00:00", "06:00", "12:00", "18:00"],
"format": "netcdf", # ファイル形式
},
str(download_path / "2023-01-01-atmospheric.nc"), # 保存先ファイルパス
)
print("Atmospheric variables downloaded!")
バッチの準備
ダウンロードしたデータを、モデルが読み込める形に変換します。
import torch
import xarray as xr
from aurora import Batch, Metadata
# ダウンロードした静的変数、地上変数、大気変数のNetCDFファイルを開く
static_vars_ds = xr.open_dataset(download_path / "static.nc", engine="netcdf4")
surf_vars_ds = xr.open_dataset(download_path / "2023-01-01-surface-level.nc", engine="netcdf4")
atmos_vars_ds = xr.open_dataset(download_path / "2023-01-01-atmospheric.nc", engine="netcdf4")
# モデル入力用のBatchオブジェクトを作成する
batch = Batch(
surf_vars={
# 地上変数データ。最初の2つの時間点(00:00と06:00)を選択。
# [None]でバッチ次元(サイズ1)を追加する。
"2t": torch.from_numpy(surf_vars_ds["t2m"].values[:2][None]), # 2m温度
"10u": torch.from_numpy(surf_vars_ds["u10"].values[:2][None]), # 10m風速 (東西成分)
"10v": torch.from_numpy(surf_vars_ds["v10"].values[:2][None]), # 10m風速 (南北成分)
"msl": torch.from_numpy(surf_vars_ds["msl"].values[:2][None]), # 海面更正気圧
},
static_vars={
# 静的変数データ。時間変化しないので最初の時間点のデータを使う。
"z": torch.from_numpy(static_vars_ds["z"].values[0]), # 地表ジオポテンシャル
"slt": torch.from_numpy(static_vars_ds["slt"].values[0]), # 土壌タイプ
"lsm": torch.from_numpy(static_vars_ds["lsm"].values[0]), # 陸海マスク
},
atmos_vars={
# 大気変数データ。最初の2つの時間点を選択し、バッチ次元を追加。
"t": torch.from_numpy(atmos_vars_ds["t"].values[:2][None]), # 気温
"u": torch.from_numpy(atmos_vars_ds["u"].values[:2][None]), # 風速 (東西成分)
"v": torch.from_numpy(atmos_vars_ds["v"].values[:2][None]), # 風速 (南北成分)
"q": torch.from_numpy(atmos_vars_ds["q"].values[:2][None]), # 比湿度
"z": torch.from_numpy(atmos_vars_ds["z"].values[:2][None]), # ジオポテンシャル
},
metadata=Metadata(
# メタデータ。緯度、経度を取得。
lat=torch.from_numpy(surf_vars_ds.latitude.values),
lon=torch.from_numpy(surf_vars_ds.longitude.values),
# 時間情報。datetime64[s]に変換してdatetime.datetimeにする。
# バッチごとに1つの時間が必要なので、要素1(06:00に対応)を選択。
time=(surf_vars_ds.valid_time.values.astype("datetime64[s]").tolist()[1],),
# 大気圧レベル情報。整数に変換してタプルにする。
atmos_levels=tuple(int(level) for level in atmos_vars_ds.pressure_level.values),
),
)
モデルのロードと実行
モデルをロードして実行し、予測を視覚化する準備が整いました。2ステップ先分の予測(for文がロールアウトにあたる)を実行し、12:00と18:00の時間の予測を生成します。
# ローカルで実行するには `False` に設定し、Foundry で実行するには `True` に設定します。
run_on_foundry = True
if not run_on_foundry:
# Auroraモデルとロールアウト関数をインポート
from aurora import Aurora, rollout
# Auroraモデルを初期化(LoRAは使わない)
model = Aurora(use_lora=False) # The pretrained version does not use LoRA.
# 事前学習済みモデルのチェックポイントをロード
model.load_checkpoint("microsoft/aurora", "aurora-0.25-pretrained.ckpt")
# モデルを評価モードにする
model.eval()
# GPUが利用可能かを確認し、利用可能であればモデルをGPUに移動する
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
model = model.to(device)
# 推論モードで勾配計算を無効にする
with torch.inference_mode():
# モデルとバッチデータを使って2ステップ先まで予測を実行
# 各予測結果をGPUからCPUに戻してリストに格納
# モデルがCPUにある場合はそのままリストに追加
preds = [pred.to("cpu") for pred in rollout(model, batch, steps=2)]
# モデルをCPUに戻す(推論がCPUで行われた場合は不要だが、安全のために記述)
model = model.to("cpu")
予測結果の確認
import matplotlib.pyplot as plt
# 2行2列のサブプロットを作成
fig, ax = plt.subplots(2, 2, figsize=(12, 6.5))
# 各予測ステップと対応するERA5データを可視化するためのループ
for i in range(ax.shape[0]):
# 現在のステップの予測結果を取得
pred = preds[i]
# 左側のサブプロットにAuroraの予測結果を表示
# 2m温度データを取り出し、ケルビンから摂氏に変換
ax[i, 0].imshow(pred.surf_vars["2t"][0, 0].numpy() - 273.15, vmin=-50, vmax=50)
# Y軸ラベルに予測結果の時間(datetimeオブジェクトを文字列に変換)を設定
ax[i, 0].set_ylabel(str(pred.metadata.time[0]))
# 最初の行の場合のみタイトルを設定
if i == 0:
ax[i, 0].set_title("Aurora Prediction")
# X軸とY軸の目盛りを非表示にする
ax[i, 0].set_xticks([])
ax[i, 0].set_yticks([])
# 右側のサブプロットに元のERA5データを表示
# ERA5データセットから対応する時間ステップの2m温度データを取り出し、摂氏に変換
ax[i, 1].imshow(surf_vars_ds["t2m"][2 + i].values - 273.15, vmin=-50, vmax=50)
# 最初の行の場合のみタイトルを設定
if i == 0:
ax[i, 1].set_title("ERA5")
# X軸とY軸の目盛りを非表示にする
ax[i, 1].set_xticks([])
ax[i, 1].set_yticks([])
# サブプロット間のレイアウトを調整
plt.tight_layout()

上記の図は世界の気温に関するAuroraの予測結果と正解データの画像を可視化したものですが、概ね正解データに近い結果を得ることが出来ています。
まとめ
本研究の成果
-
時空間+気圧レベルの次元を持つ地球システムデータを対象とした基盤モデルAuroraを提案しました。
-
Auroraは下記のような特徴を持っています。
- 3DPerceiverにより解像度や変数、気圧レベルが異なる異種のデータを普遍的に扱うことができ、Fourier encodingによって時空間的な意味を付与することができる。
- Multiscale 3D Swin Transformer U-Netによりユーザーが望んだ解像度での予測が可能。
- この予測モデルで繰り返し自己回帰的な予測を行わせることでユーザーが望む長さの予測が可能。
-
単一タスクではなく、Fine-Tuningを行うことで天気予報、台風の進路予測、波浪予測等の多様な予測タスクに応用できます。
-
Fine-Tuningでの工夫や、推論速度が高速であるため、従来の数値モデルに比べてコスト効率が非常に高い運用が可能です。
今後の展望
Auroraは任意の地球システムタスクに低コストでFine Tuningできるため、洪水・山火事などの非定常的な現象、花粉動態、農業生産性、再生可能エネルギー生産、海氷面積といったより幅広い領域で応用できる可能性があります。
参考文献
本記事の執筆にあたり、下記資料を参考にしました。
- 論文:https://www.nature.com/articles/s41586-025-09005-y
- 論文の補足情報:https://static-content.springer.com/esm/art%3A10.1038%2Fs41586-025-09005-y/MediaObjects/41586_2025_9005_MOESM1_ESM.pdf
- ソースコード (GitHub):https://github.com/microsoft/aurora?tab=readme-ov-file
- Perceverとは:https://developers.agirobots.com/jp/perceiver-perceiver-io/
Discussion