TypeScriptで配列に重複がないことを保証する
zodで複数の設定群がある Schema を作成している際...
const exampleSchema = z.object({
name: z.string(),
description: z.string(),
exampleGroups1: z.array(
z.object({
name: z.string(),
setting1: z.string(),
// ...
})
),
exampleGroups2: z.array(
z.object({
name: z.string(),
settings: z.array(
z.object({
name: z.string(),
setting1: z.string(),
// ...
})
),
})
),
});
const example: z.infer<typeof exampleSchema> = {
// ...
};
nameを抽出したいな...
const exampleGroup1names = example.exampleGroups1.map((group) => group.name);
const exampleGroup2names = example.exampleGroups2.map((group) => group.name);
抽出結果を加工したいな...
const exampleFn = (g1Names: string[], g2Names: string[]) => {
// ...
};
const exampleResult = exampleFn(exampleGroup2names, exampleGroup1names);
// ^代入の順序を間違えてしまった!!!
このようなことがあるかもしれません
exampleFnの引数の型はどちらもstring[]なので、引数の順序を間違えても TypeScript はエラーを出してくれません。しかし、人間の注意力に依存する実装はいつか破綻します。
そこで、branded型を使い、各nameに独立した型を付与することを考えます。
const exampleSchema = z.object({
name: z.string().brand("exampleName"),
// ...
name: z.string().brand("exampleGroupName"),
// ...
name: z.string().brand("exampleGroupName"),
// ^うっかり同じ名前を付けてしまった!!!
settings: z.array(
z.object({
name: z.string().brand("exampleGroup2SettingName"),
// ...
});
const example: z.infer<typeof exampleSchema> = {
// ...
};
これでもまだ注意力に依存していますね。複数のファイルにまたがる、あるいはファイルサイズが膨大になった場合に、うっかり同じブランド名を付けてしまう可能性は十分に考えられます。
そこで、様々な場所で使う予定のブランド名をあらかじめ列挙し、重複がないことを保証する仕組みを導入します。
const BRAND_NAMES = noDuplicate([
"exampleName",
"exampleGroup1Name",
"exampleGroup2Name",
"exampleGroup2SettingName",
] as const);
const branded = <
T extends z.ZodTypeAny,
U extends (typeof BRAND_NAMES)[number]
>(
schema: T,
name: U
) => schema.brand(name);
これなら、誤って同じブランド名を付与することはありません。
本題
配列に重複がないことを保証する型ガード関数の実装
配列に重複がないことを保証するための型ガード関数で使用する、重複している要素にエラーを出せるジェネリクス型をどのように作成すればよいか考えていきます。
類似の機能について、以下の記事で言及されています。
しかし、この記事の実装を単純にオブジェクトではなく文字列の場合に書き換えることはできません。
- この実装は厳密には重複をチェックしているのではなく、ひとつひとつの要素に対して、元の配列から同じ ID を持つオブジェクトを検索し、他のプロパティの値が同じかを確認している
- 他のプロパティの値が同じであれば自分自身を参照しているとみなし問題がないと判断し、異なる場合はその要素の型を
neverに変更することで重複をエラーとして可視化 - そのため、ID が重複していても他のプロパティの値がすべて同じであれば問題がない
つまり今回の要件には適していません。
そもそも、ID プロパティと他のプロパティの 2 値から算出している点で一つの値からしか算出できない、文字列の配列の要素の重複をチェックすることに流用はできないです。
記事を書きながらできることに気付いた。でも以下の実装のほうが簡潔でわかりやすいと思う
type EnsureUniqueValues<T extends readonly Record<number, string>[]> = {
[K in keyof T]: T[K] extends { [key: number]: infer V }
? Extract<Exclude<T[number], Record<K, V>>, Record<number, V>> extends never
? T[K]
: Record<K, never>
: Record<K, never>;
};
type arr2obj<T extends readonly string[]> = {
[K in keyof T]: Record<K, T[K]>;
};
type obj2arr<T extends readonly Record<number, string>[]> = {
[K in keyof T]: T[K] extends { [key: number]: infer V }
? V extends string
? V
: never
: never;
};
type test = obj2arr<EnsureUniqueValues<arr2obj<["a", "b", "c", "a"]>>>;
// ^ [never, "b", "c", never]
そこで、他のアプローチを考えます。
- 重複がないということは、配列から一つの要素を取り出して元の配列をフィルタリングした際に、その要素が残る数が 1 つであること。
- 配列の各要素に対して 1. の操作を行う。
- 生成された型に対して Mapped Types を使用し、重複している要素の型を
neverに変更する。
実装
これらのアプローチを元に作成した型が以下になります。
type FilterTarget<
T extends string,
Array extends readonly string[]
> = Array extends [infer U, ...infer V extends string[]]
? U extends T
? [U, ...FilterTarget<T, V>]
: FilterTarget<T, V>
: [];
export type EnsureUniqueStrArr<T extends readonly string[]> = {
[K in keyof T]: FilterTarget<T[K], T>["length"] extends 1 ? T[K] : never;
};
この型について詳しく見ていきます。
-
FilterTarget<T extends string, Array extends readonly string[]>は、特定の文字列Tが配列Arrayの中に何個含まれているかを再帰的にチェックし、含まれている要素だけを新しい配列として返します。-
Array extends [infer U, ...infer V extends string[]]で配列の先頭要素Uを取り出し、残りの要素をVに格納します。 -
U extends Tで先頭要素Uが目的の文字列Tと同じ型であるかを確認します。 - もし同じであれば、
Uを先頭に、残りの要素Vを再帰的にフィルタリングした結果(...FilterTarget<T, V>)を結合した新しい配列を返します。 - 同じでなければ、
Uを含まず、残りの要素Vを再帰的にフィルタリングした結果を返します。 - 配列の最後の要素まで到達し、
Arrayが空になった場合は、空の配列[]を返します。
-
-
EnsureUniqueStrArr<T extends readonly string[]>は、入力された文字列配列Tの各要素に対して重複チェックを行います。-
[K in keyof T]で配列Tの各インデックスKをループします。 - 各要素
T[K]に対してFilterTarget<T[K], T>を適用し、その要素が元の配列T内にいくつ存在するかを計算します。 -
FilterTarget<T[K], T>["length"] extends 1 ? T[K] : never;の部分で、フィルタリングされた結果の配列の長さが1であれば、その要素は重複していないと判断し、元の要素T[K]の型をそのまま返します。そうでなければ、重複していると判断し、型をneverにします。
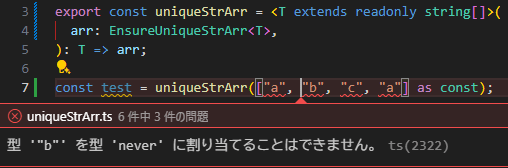
例えば、
["a", "b", "c", "a"]の場合、-
"a"は 2 個含まれているため、FilterTarget<"a", ["a", "b", "c", "a"]>は["a", "a"]を返します。このlengthは2なので、"a"の型はneverになります。 -
"b"と"c"はそれぞれ 1 個しか含まれていないため、それぞれのFilterTargetのlengthは1となり、型はそのまま"b"と"c"になります。
-
これにより、重複している要素の位置のみにnever型のエラーが発生し、コンパイル時に重複を検出できるようになります。
おわりに
このレベルの型パズルを自力で解くのは初めてで、試行錯誤しながらでしたが非常に楽しかったです。高速に高度な推論をしてくれる TypeScript だからこそ、トライ&エラーを繰り返しても快適に問題に取り組むことができたのだと感じました。
TypeScript 最高!!!
🥳🎉
おまけ
🤔🤔🤔
🥰🥰🥰
おまけのおまけ
学生だと Gemini Pro が無料なので試しに解かせてみた
自分の実装のほうが簡潔でうれしい
Discussion
おまけの部分について、原因がわかったのでコメントいたします。
結論から言うと、
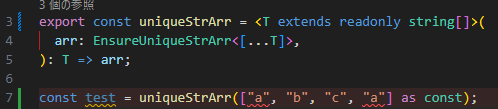
FilterTargetを次のようにすれば解決します。つまり、
readonly ["a", "b", "c", "a"]はUとVをどのようにとっても[infer U, ...infer V extends string[]]の部分型にはならない(readonlyな配列型はそうでない配列型の部分型にならない)ため、元の実装ではArrayとしてreadonlyな型を渡すとここで常に条件を満たさない判定になっています。後段の
uniqueStrArrの実装では、[...T]としたことでreadonlyが外れてうまく動いているものと思われます。コメントありがとうございます!
自分のトップページを見ても各記事のLike数は表示されますがコメント数は表示されないため完全に見落としておりました...
本記事を公開してから数日後に僕もcisdurさんと同様の結論に至り、その結論をもとに記事を作成したのですが、こちらの記事で原因究明にむけてのコメントを促すようなことを行っていたにも関わらずコメントを確認せず記事を公開してしまい、cisdurさんの成果を横取りするような格好になってしまい申し訳ないです
該当記事にてこちらのコメントを引用するように修正いたしました