【DBを自作する会 #1-1】ファイルシステムを理解しよう!─ブロックとページ編
自己紹介
はじめましての投稿です。よっしー(@yosshi_zen)です!
某大学の情報系学科3年生の端くれで、ノンビリとコーディングをする毎日を送っています。
DBを自作する会?
先日、私がかつて所属していたサークルのOBのDiscordにて「データベースを自作する会」が突如発足しました。諸先輩方が強すぎるので若干尻込みしつつも、勇気を出して参加してみました。
形式は、週1回オンラインで集まって、スライドに1章分の話題を説明するというものです。「輪読」に加えて「実装」もするので、「輪実装会」というらしいです。そもそも輪読もマトモにやったことがないので、自分ができるのか一抹の不安がよぎります。
使った教材
何もない状態から始めるのでは手詰まりになってしまうので、こちらの本をPDFダウンロードして利用することになりました。提携大学?の学生メールアドレスでログインすると、「大学生特権」により無料でダウンロードすることができます。オイシイ。
構成はどんな感じ?
なお、この本は以下の章立てから成っています。
- Database Systems
- JDBC
- Disk and File Management
- Memory Management
- Transaction Management
- Record Management
- Metadata Management
- Query Processing
- Parsing
- Planning
- JDBC Interfaces
- Indexing
- Materialization and Sorting
- Effective Buffer Utilization
- Query Optimization
だいぶ派手ですね。
それもそのはず、この本450ページもあります。しかも当たり前ですが全部英語……。
これを噛み砕くのは相当な胆力が要りそうですが、どうにか頑張って読解していきたいと思います。
備忘録的な意味合い + 本に書いていなかった詳細をまとめる、という目的で書き進めていきます。
駄文まみれで恐縮ですがお付き合いのほど〜〜
技術選定
参加者の皆が「Go使い」だったので、半ば自動的にGoで実装することになりました。
本はJavaで実装を進めているようなので、それをうまく書き換えてやろうってことですね。
さて Disk and File Management(原文ママ)
満を持して始まった輪実装会ですが、第1,2章は「データベースとは何か」という話題が主だったので軽く飛ばしていき、第3章から始まる「ファイルの格納方法と、OSにおける処理方法」が説明されている部分を重点において進めました。
【読み物】データの永続保管について
もちろんですが、データベースに保管されているデータは「永続的に」残っていて欲しいです。
この節では、永続的なデータの保管方法として「ディスクドライブ」をあげています。例としてはHDDです。この動作原理から切り込みます。
ディスクドライブ
こまこまとした話をする前に概観から眺めておきましょう。HDDはこのような構造をしています。絵の稚拙さは目を瞑ってください、、、笑

HDDは「ディスク」ドライブなので、円盤が回転してそれを読み書きしています。誤解を恐れずにいえば、何枚ものCDが内部にある感じです。その円盤1枚1枚のことを「プラッタ(platter)」といいます。そして、プラッタ1枚は、幾つもの層からなるバウムクーヘンのような構造をしています。その層1枚1枚を「トラック(track)」といいます。「セクタ(sector)」は後述しますが、トラックを構成する記憶領域の一部分です。
ここで、ディスクドライブの性能を評価する指標をいくつか導入してみます。
ディスクドライブ容量(capacity)
量販店ではこれを売りにして販売されていますね。512GBとか、1TBとか。
定量的に評価するならば、
「プラッタ数」×「トラック数 / プラッタ」×「バイト数 / トラック」
として表現できます。
回転速度(rotation speed)
プラッタが回転して読み書きするわけですから、当然回転のスピードも読み書き性能に直結します。
転送レート(transfer rate)
バイト列が「磁気ヘッダ」を通過する速度を指します。1秒あたりに何バイトのデータが通過するかどうかという指標です。直感的にわかりにくかったのでこれも図に起こしました。
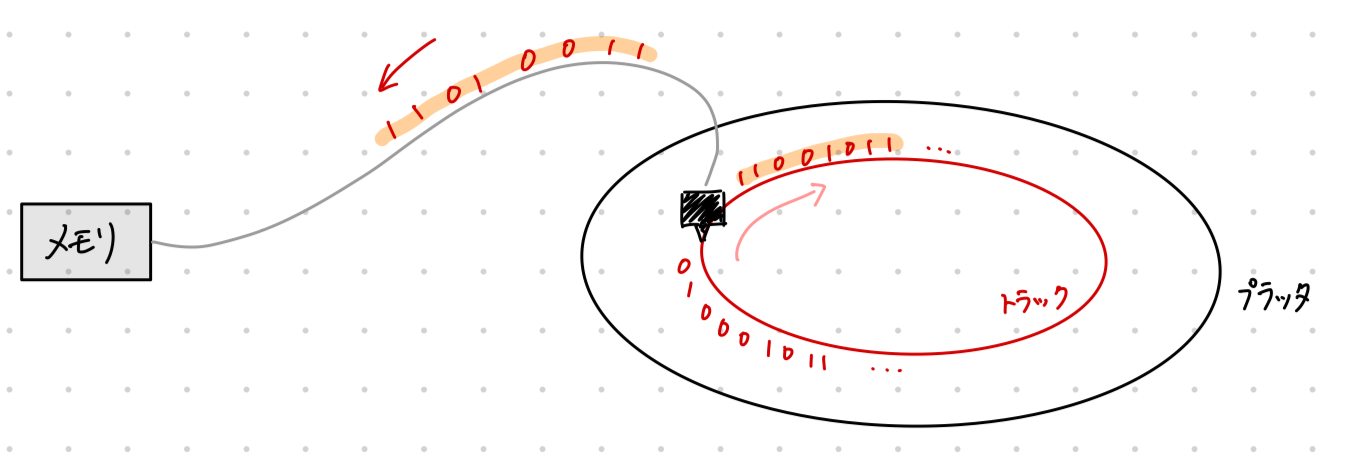
これを見れば一目瞭然だとは思いますが、「トラックあたりのバイト数」と「回転速度」に依存する指標になります。
シークタイム(seek time)
最後にシークタイムです。これは、磁気ヘッダが目的トラックに到着するまでの遅延となります。こちらは直後に詳説します。
ディスクドライブへのアクセス
では、どうやってディスクにアクセスするのか考察してみましょう。具体的には以下の順番で行われます。
- 特定のトラックまでヘッダを移動させる(seek time)
- 特定の読み出し開始位置が回転してくるまで待つ(rotational delay)
- 読み出し終了位置まで回す(transfer time)
そして、アクセスするのにかかる時間は1〜3の所要時間の和となります。
文章だと若干わかりにくいと思うので、これも図に起こしてみました。
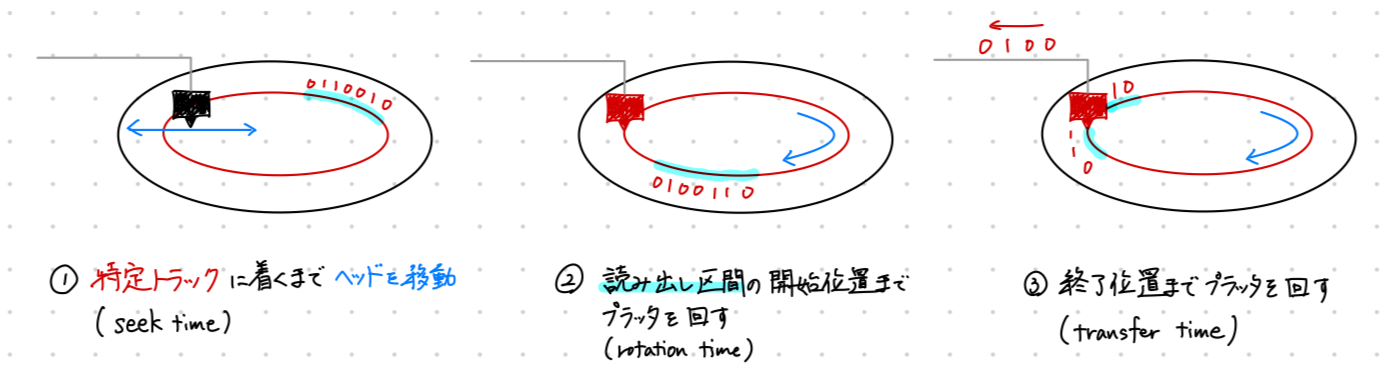
では、この3段階にかかる時間をそれぞれ定量的に評価してみましょう。
ここで重要になってくる考え方があります。それは、
ということです。
…何を当たり前のことを?と思うかもしれません。何がいいたいかというと、「1と2の、ディスク上の特定のバイト列のところにヘッダを移動させる時間」がとても支配的であるということです。
1バイトのデータの転送時間は、転送レート(こちら)が80MB/sとすると、
となって、これが1,000バイトのデータだったとしても
これは、平均seek timeが
したがって、1バイトだろうが1,000バイトであろうが読み出し時間はさして変わらないので、「まとめて読み出してしまおう」と考えだされたのが「セクタ」という概念です。壮大な伏線回収ですね…笑
この先の節では、seek timeやrotational delayによる遅延の影響が大きいことから、その遅延を小さくしようとする試みが多数紹介されています。また、永続性の観点から、データが吹き飛ばないようにする工夫についても紹介されています。しかし本筋から逸れるためこの回では割愛します。(どこかで紹介するかも…?)
【読み物】ブロックレベルでのインタフェース
ここまでの話で、「セクタ」という単位でディスク上のデータにアクセスすることを紹介しました。
なので、このセクタをデータの単位、いわゆる「かたまり」として、アプリケーションでも取り扱えばいいのでは?とお思いでしょう。しかしここで大きな問題があります。
ということです。そこで、OSがその違いを吸収してやる必要があります。そこで、「ブロック」という概念を導入します。ブロックには以下の特徴があります:
- 基本的にはセクタと同じ
- 異なるのは、「OSがサイズを決める」ということ
- 全てのブロックが固定長
- OSが、ブロックとセクタをマッピングする
- OSは、各ブロックに対して番号(block number)を付与する
- block numberをもとに、OSが実際のセクタアドレスと結びつける
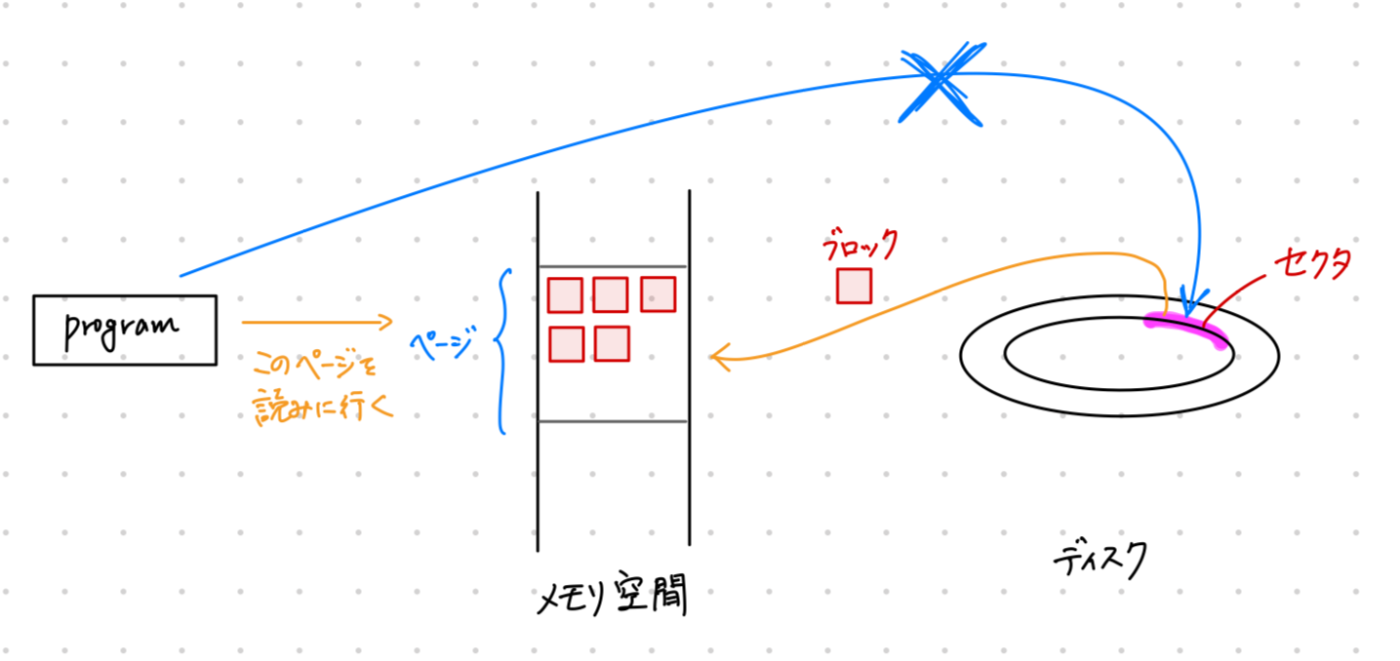
また、そのブロックのアクセスにも制約を設けます。
- ディスクのデータを直接アクセスすることを禁止する
- ディスクのデータアクセス時には以下のプロセスを経る
- まず、メモリ上の「ページ」に、当該セクタのブロックを読み込む
- ページからブロックを読み込み、バイト列を編集してページに書き戻す
- ディスクへ書き戻す
ブロックは主にこんな感じです。(間違っているかもしれません、その場合追記します)
OSが提供する具体的なインタフェース
上述のシステムを実現するため、OSは以下のインタフェースを提供するのが一般的です。
-
readblock(n, p)- ディスク上のblock numberがnのブロックを、ページpに読み込む -
writeblock(n, p)- ページpのバイト列を、ディスク上block numberがnのブロックに書き込む。 -
allocate(k, n)- k個の連続したブロックをディスク上から発見し、確保したblock numberを返す。空き領域は、できる限りblock numberがnに近いものから探す。 -
deallocate(k, n)- block numberがnから始まる、k個のブロックを「unused」とする
ふぅ
記事って書くのだいぶ疲れますね…笑
今度大学の課題がひと段落したら、1-2の「ファイルレベルのインタフェース編」行ってみたいと思います。
では!課題の沼へ!
追伸(2025/02/11)1-2を書きました!実装が近い…笑
Discussion