smolagentsでエージェントにPythonを書かせてみた
概要
- OpenAIの
gpt-4o-miniを利用してsmolagents😎を試してみた。-
transformersを使うことでローカルLLMを、LiteLLMを使うことで外部にホストされたLLMを幅広く簡単に利用することができる。
-
-
smolagentsにはMultiStepAgentとLiteLLMModelが含まれており、それぞれ「エージェント」と「LLMのインターフェース」を担っている。 - LLMの生成したPythonコードを実行することで、
CodeAgentはより正確な結果を得ることができる。 - エージェントはLLMからの返答にフィードバックを与え、よりよい回答を得られるよう努力してくれる。
smolagentsの他のクラス(参考)
今回紹介するクラス以外にどのようなものがあるのかザッと見てみた。(精緻性に欠く方法)
import smolagents
[v for v in dir(smolagents) if v[0].isupper()]
実行結果は以下の通り。画像、音声系のタスクもできるらしく、他にもいろいろとありそう。
['AUTHORIZED_TYPES',
'AgentAudio',
'AgentError',
'AgentImage',
'AgentLogger',
'AgentMemory',
'AgentText',
'AgentType',
'AzureOpenAIServerModel',
'ChatMessage',
'CodeAgent',
'DuckDuckGoSearchTool',
'E2BExecutor',
'FinalAnswerTool',
'GoogleSearchTool',
'GradioUI',
'HfApiModel',
'LiteLLMModel',
'LocalPythonInterpreter',
'LogLevel',
'MessageRole',
'Model',
'Monitor',
'MultiStepAgent',
'OpenAIServerModel',
'PythonInterpreterTool',
'SpeechToTextTool',
'TOOL_MAPPING',
'Tool',
'ToolCallingAgent',
'ToolCollection',
'TransformersModel',
'UserInputTool',
'VisitWebpageTool']
環境セットアップ
使い捨てのJupyter Notebook(on WSL2)環境を準備します。今回はサンドボックス環境で実行していますが、Python3が使える環境であれば基本的に場所を選ばず実行可能かなと思います。後述しますが、CodeAgentはLLMが生成した任意コードを実行することができるため、特に破壊的な処理を行う場合にはサンドボックス環境を作成したほうが安心です。
また、今回は紹介しませんがE2BExecutor辺り[3]を使うと外部のサンドボックス環境を使えるようなので、それを活用してみても良いかもしれません。
- ホスト: Windows 11 Pro (23H2)
- WSL:
- kernel:
5.15.167.4-microsoft-standard-WSL2
- kernel:
- コンテナ内:
- Docker image: https://hub.docker.com/r/jupyter/datascience-notebook
- Python: 3.11.6
- smolagents: 1.8.0
- LiteLLM: 1.60.8
services:
notebook:
image: jupyter/datascience-notebook:latest
command:
- start-notebook.sh
- "--NotebookApp.token=''"
- "--NotebookApp.disable_check_xsrf=True"
ports:
- "8888:8888"
必要なパッケージは以下でインストールするもの2つです。外部ホストのLLMを使うために今回はlitellm[4]を利用しています。このパッケージを使うことでOpenAI、Anthropic、VertexAIをはじめとした様々なLLMを統一されたインターフェースで利用できます。
これを使う以外にも、Hugging Face上で頒布されているモデルをtransformersでロードすることで、ローカルLLMも使うことができるようです[5]。
pip install smolagents litellm
今回は大それたこともしないので、通常のパッケージをそれぞれインストールします。
OpenAIのAPIキーの準備
OpenAIのAPIを経由して外部のLLMを利用するため、キーを発行します。以下のページにてAPIキーを作成し、あらかじめ残高を入れておきます。今回はお試しなので最小の5ドル入れてみました。
- API keys: https://platform.openai.com/api-keys
- Billing: https://platform.openai.com/settings/organization/billing/overview
発行したAPIキーは、環境変数にセットしておきます。今回はdotenvを使ってロードしますので、.envに書いておきます。
OPENAI_API_KEY="**********"
早速使ってみる
公式ドキュメントを参考にし、まずはフィボナッチ数列の118番目を求めます。
このCodeAgentの優れている点は、LLMが直接結果を推論するのではなく、LLMが中間生成したPythonコードを言葉通りCodeAgentが代わりに実行して結果を得ることができる点です。これによりhallucination(幻覚)の影響に抑え、より正確な結果を得ることができます。
また、CodeAgentはエラーが発生した際などにもログの内容を解釈し、フィードバックを与え、複数のステップを経てよりよい回答を行ってくれます。なお、このステップ数の上限は初期化時にmax_steps[6]で設定することができますが、多ければ良いという訳ではないので注意します。
from smolagents import CodeAgent, LiteLLMModel
from dotenv import load_dotenv
load_dotenv()
model = LiteLLMModel(model_id = "openai/gpt-4o-mini")
agent = CodeAgent(
tools = [],
model = model,
)
agent.run(
"Could you give me the 118th number in the Fibonacci sequence?",
)

グラフィカルな画面で実行され、結果2046711111473984623691759を得ます
パッケージを追加してみる (安全性の話)
CodeAgentはローカルでPythonを実行しますが、その際にLLMが生成した任意のコードを実行することができてしまいます。そのため、デフォルトでは埋め込み関数やmathなどの安全なパッケージ・関数しか使うことができません。削除系の処理を行う際などには特に注意を払う必要があります。追加でパッケージを使うには、初期化の時点でadditional_authorized_imports[7]にパッケージ名の配列を渡す必要があります。
以下の例では追加でパッケージの使用を許可し、Googleのページをfetchしてタイトルを取得しています。ただし、additional_authorized_importsにパッケージを追加したからといって、必ずそれらを使うような制約が課される感じではないようです。そのため今回は正規表現でソースコードから抽出するのではなく、BeautifulSoupを使うよう明示的に指示しました。
from smolagents import CodeAgent, LiteLLMModel
from dotenv import load_dotenv
load_dotenv()
model = LiteLLMModel(model_id = "openai/gpt-4o-mini")
agent = CodeAgent(
tools = [],
model = model,
additional_authorized_imports = ["requests", "bs4"], # パッケージの使用を追加で許可する
)
agent.run(
"Fetch html from `https://www.google.com/` and extract the page's title from title tag by using BeautifulSoup.",
)
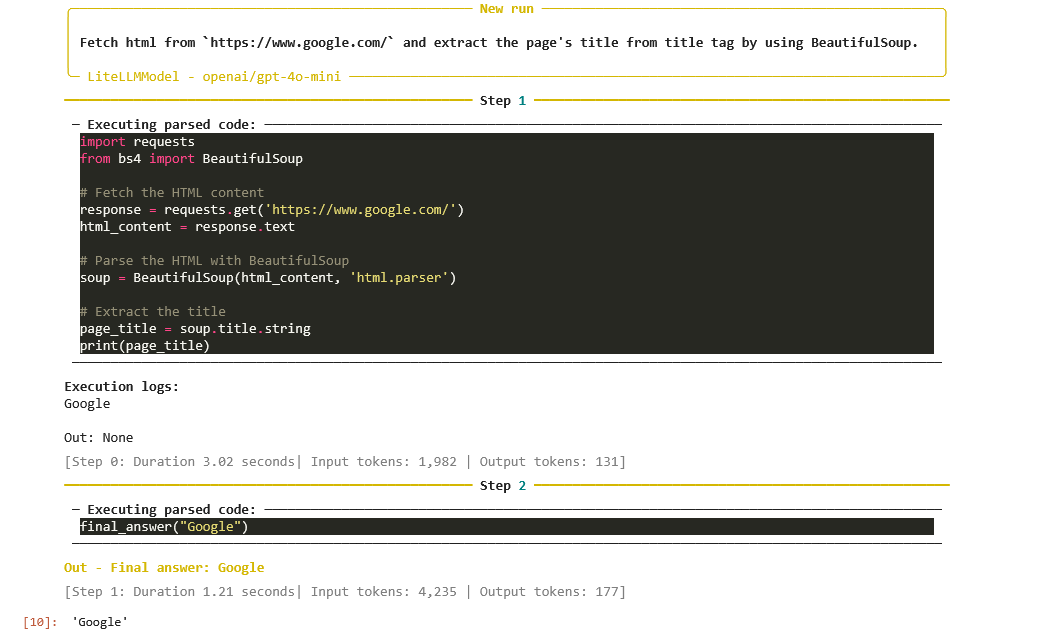
指定のURLにアクセスし、BeautifulSoupを使ってタイトルを得ている
マルチエージェントを構築してみる
smolagentsにはいくつかのツールボックスがデフォルトで用意されています。add_base_toolsをTrueにしてCodeAgentクラスを初期化することで、デフォルトのツールを使ってエージェントを強化することができます。
デフォルトで用意されているツール(参考)
実装を見てみると、PythonInterpreterTool、DuckDuckGoSearchTool、VisitWebpageToolの3つが含まれています。
チュートリアルではあえて明示的にツールを使うように書いていますが、add_base_tools = Trueにするだけでも検索エージェントは作成できるかもしれないです。
このツール機能を活用すると、役割が異なるエージェントを複数組み合わせたマルチエージェントを作成することができます。なお、デフォルトで実装されていないツールも作成できるため、特定のドメインに特化したツールを作成することもできます(例えば欲しいデータの詳細を受け取ってDB上でクエリを実行するなど)。
公式ドキュメントの例を参考にして、DuckDuckGoを使った検索型マルチエージェントを作成してみました。なお、Google検索も利用することはできますが、SerpApiのAPIキーが別途必要です。
以下の例では、公式ドキュメントの例とは違いパッケージ内のVisitWebpageToolを使っています。独自のツールを定義する際には、GitHubのexamplesのように@toolのデコレータを付け、docstringに関数の内容を説明し、入出力の型ヒント[8]を書きます。これらの型ヒントがLLMの理解を助け、より精度の高い結果を得るための手がかりとなりますし、書かないとエラーになります。
from smolagents import CodeAgent, ToolCallingAgent, LiteLLMModel, DuckDuckGoSearchTool, VisitWebpageTool
from dotenv import load_dotenv
load_dotenv()
model = LiteLLMModel(model_id="openai/gpt-4o-mini")
# ツールを利用するエージェント
# 与えられた2つのツールを使って検索・Webページへのアクセスを行う
managed_web_agent = ToolCallingAgent(
tools = [DuckDuckGoSearchTool(), VisitWebpageTool()],
model = model,
name = "web_search",
description = "Runs web searches for you. Give it your query as an argument.",
)
# エージェントを利用するエージェント
# managed_web_agentに対して指示を行う
manager_agent = CodeAgent(
tools = [],
model = model,
managed_agents = [managed_web_agent],
)
manager_agent.run("Who is the president of Hasunosora Girls' High School Idol Club?")
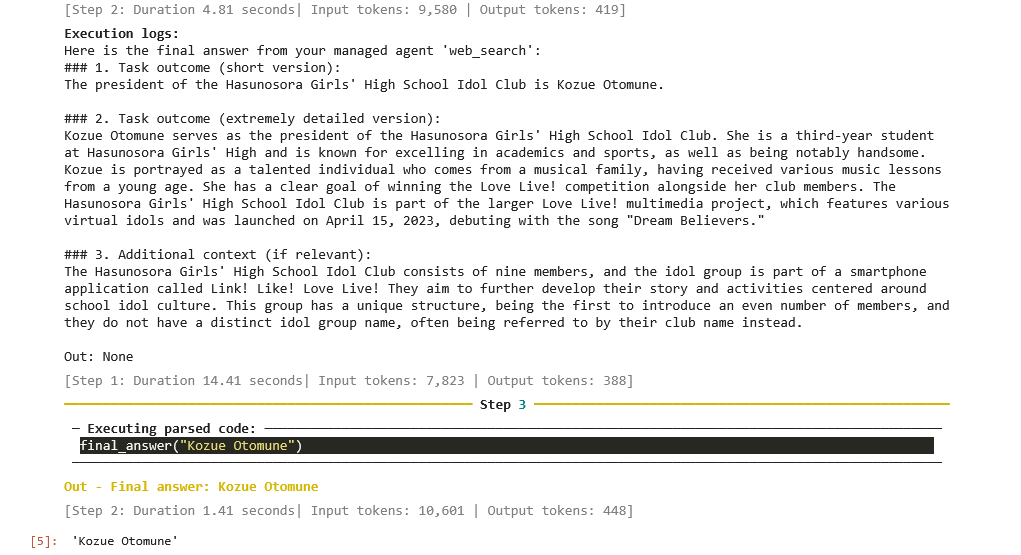
検索結果に出てきたWebページに実際にアクセスし、正解となる"Kozue Otomune"を得ている
なお、gpt-4o-miniに対して直接問うと誤った答えを返してくるため、今回試してみたグラウンディングはより正確な回答に役立っています。
gpt-4o-mini単体の知識を使った際の回答結果
model = LiteLLMModel(model_id = "openai/gpt-4o-mini")
agent = CodeAgent(
tools = [],
model = model,
)
agent.run("Who is the president of Hasunosora Girls' High School Idol Club?")
結果は以下の通りになった。

"Shioriko Mifune"と返しているが、そもそもグループの異なるメンバーを回答しているため誤り
もう少し大型のタスクを与えてみる
ワードを返すだけではタスクとしては単純なので、次はWeb上のデータについて複数項目を列挙してもらう、いわばスクレイピングのタスクを与えてみます。
今回はシングルエージェントとして、一人で頑張ってもらいます。
from smolagents import CodeAgent, ToolCallingAgent, LiteLLMModel, DuckDuckGoSearchTool, VisitWebpageTool
from dotenv import load_dotenv
load_dotenv()
model = LiteLLMModel(model_id="openai/gpt-4o")
agent = CodeAgent(
tools = [],
model = model,
additional_authorized_imports = ["pandas", "bs4", "requests", "re"]
)
agent.run("""
What are the most trending models on Hugging Face? Go to `https://huggingface.co/models` and list as many model names, types and download counts as you can.
You can retrieve the model list by selecting `div.relative article` elements.
Extract their meta information from the `div' element next to the `header' element containing the model name.
Remove special characters such as tab and carriage returns from the meta information and treat it as a `meta info' column.
Do not truncate list and table. Format as Pandas Dataframe.
""")
基本的にはプロンプトを頑張って書いただけです。少しタスクの難易度が上がったのでgpt-4oに切り替えて実行してみました。
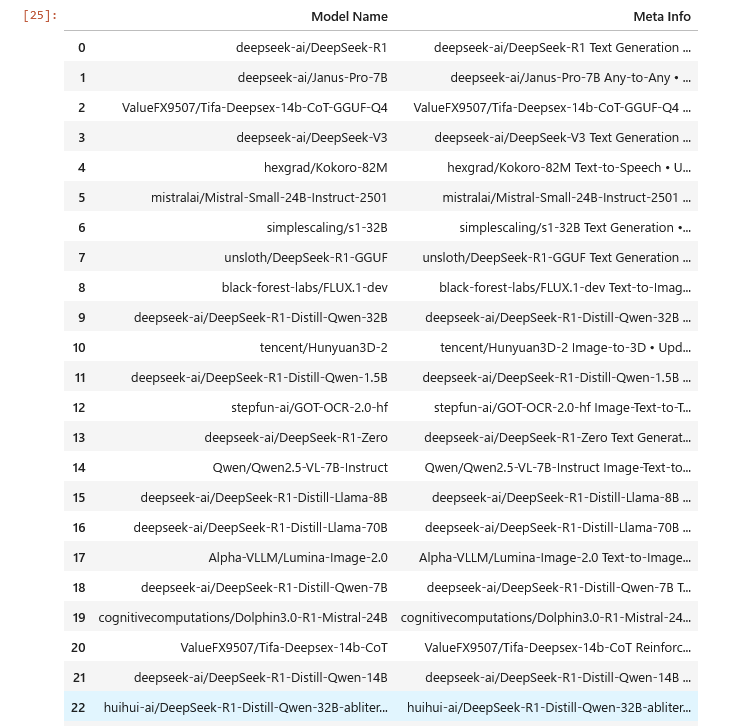
指示通りモデル名とメタ情報の2カラムのDataFrameを得た
LLMが生成したコード(参考)
以下のコードはstep 2で生成されました。特に今回の要件に対しては問題ないように見えます。
import requests
from bs4 import BeautifulSoup
import pandas as pd
import re
# Fetching the webpage content
url = "https://huggingface.co/models"
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
# Extracting model details
models_data = []
models = soup.select('div.relative article')
for model in models:
# Model name
header = model.find('header')
model_name = header.text.strip() if header else "N/A" # If header not found, use "N/A"
meta_info = model.find('div')
meta_text = re.sub(r'[\t\r\n]', ' ', meta_info.text).strip() if meta_info else "N/A"
models_data.append({
"Model Name": model_name,
"Meta Info": meta_text
})
# Creating the DataFrame
df = pd.DataFrame(models_data)
# Showing the DataFrame
print(df)
今回のようなやや大型のタスクを課すと、LLMからの返答を踏まえてエージェントがステップごとにフィードバックし、実際にHTMLを解釈してコードを生成している過程をログで見ることができるので楽しいです。このようなタスクにおいて思うような結果が得られない際には、少しmax_stepsを上げてみるのも一つの選択肢かもしれません。
なお、このコードを1回実行するごとに1.5万~2万トークンほど使うため、gpt-4oを使うと大体0.1~0.2ドルほど使います。gpt-4o-miniは0.02ドルくらいしかこの記事作成中に使っていないので、インパクトを実感します(円安も含め...)。
まとめ・感想
マルチエージェントは特におもしろい仕組みで、データベースに接続するエージェントを作成してSQLを作成して投げてもらうなど、活用の幅が広い技術だと感じました。
詳しい概念などは公式ドキュメントに動画や画像を添えてconceptual guidesとして紹介されていたりするので、関連研究の論文を含め、気になる方は見てみるとおもしろいと思います。
また、所望の出力・結果が得られなかった際には公式ドキュメントにBuilding good agentsというページが用意されているので、それを読んで対策してみると良いと思います。
-
groundingの説明についてはグラウンディングの概要を参照。 ↩︎
-
別のクラスが用意されているが、公式のサンプルコードによるとプロンプトが違うだけで
CodeAgentでも動く。また、ToolCallingAgentもPythonコードを経由してツールを呼び出す。 ↩︎ -
https://huggingface.co/docs/smolagents/tutorials/secure_code_execution#e2b-code-executor ↩︎
-
https://huggingface.co/docs/smolagents/guided_tour#building-your-agent ↩︎
-
https://huggingface.co/docs/smolagents/reference/agents#smolagents.MultiStepAgent.max_steps ↩︎
-
https://huggingface.co/docs/smolagents/reference/agents#smolagents.CodeAgent.additional_authorized_imports ↩︎
Discussion