こんにちは、よしこです。
この記事は 2020年に立ち上げたWebフロントエンド構成の振り返り の「Applicationのアーキテクチャ」項の詳細記事です。単体でも読めますが、よければ元記事もあわせてどうぞ!
この記事では、わたしの所属する株式会社ナレッジワークで開発・運用しているWebアプリケーションのドメインロジックやAPI通信部分のアーキテクチャについてご紹介していきます。いわゆるフロントエンドの中でも裏側の部分。
一番設計っぽい話になると思いますが、そのぶん「△△ライブラリの便利な使い方」「◯◯のベストプラクティス」というような具体的で汎用的な話とは異なり、うちではこうやってますという事例の共有以上の何物でもないです。
社内資料を社外にも公開するぐらいのイメージで共有していきます!
前提:アプリケーションの構成要素の4分類
前段として、大元の思想から話します。
まず、フロントエンドアプリケーションのロジックを構成する要素を以下の4つに大別しています。
- Component (以前書いた紹介記事)
- Global State (以前書いた紹介記事)
- Resource Set ★この記事で話すこと
- Library
この4つの関係性は以下のような感じ。
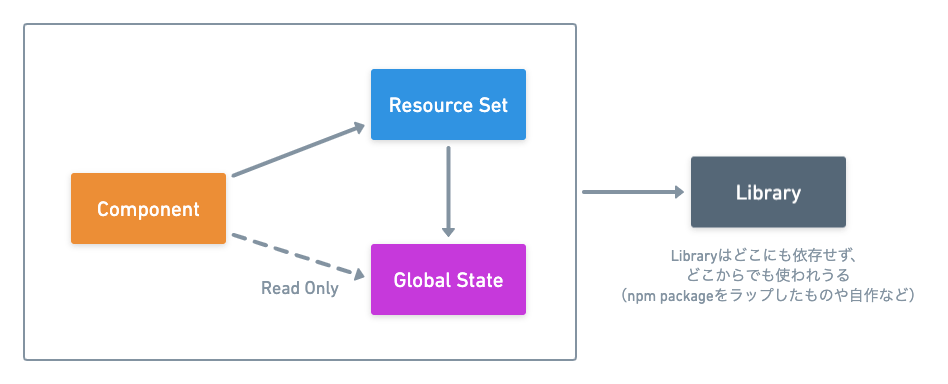
この4つを src 以下のディレクトリと照らし合わせてみると以下の対応。

Resource Setカテゴリの中に、 usecases repositories というディレクトリがありますね。
それらのレイヤーまで含めた依存関係の概観がこちら。

ちょっと抽象的で掴みにくいので、具体的な切り口でも見てみましょう。
「ユーザーが画面上で何らかのイベントを起こし、それに対してAPI通信を伴う結果を画面に反映する」という一般的なケースで考えます。
そのときに、これらのレイヤーがどう連携し合ってデータを受け渡すかの図が以下です。

(この図は、各要素説明後にもう一度改めて引用します)
Usecase, Repositoryに加えて、各レイヤーを移動するデータとしてModelも登場しました。
ここまでは思想の概観として全体像のわかるいくつかの図を紹介しましたが、この記事ではそれらの中の 「Resource Set」 という青い部分について解説したいので、ここからはそこを掘り下げていきましょう。
Resource Set ってなんなのよ
Resource Set というのは、リソースごとに存在する、そのリソースに関連した処理のセットです。
※ Resource Set という呼び方は造語です
リソースというのは、ドメインモデルの種類のこと。たとえばECサイトなら User(ユーザー)/ Product(商品)/ Order(注文)… 等になるでしょうか。
処理のセットは、「Model」「Usecase」「Repository」から構成されています。
これらを踏まえると、リソースごとに存在する要素は以下のようになります。

(うちではComponentもリソースごとに切っているため、図に含めました。その話はこちら)
models usecases repositories ディレクトリの中がさらにリソース単位でディレクトリ分割されていることがわかりますね。
このように、「レイヤー × リソース種別」ぶんのディレクトリを用意しています。
Model, Usecase, Repositoryの説明
ひとつのリソースに対応して存在する Model, Usecase, Repository の3つのレイヤーをまとめて Resource Set と呼んでいます。
ここからはそれぞれを掘り下げて説明していきます。
Modelレイヤー
Modelはドメインモデルをあらわすレイヤーです。主に属するのは以下です。
- データ型の定義(type.ts)
- ドメインロジックを実装した関数(selector.ts)
データ型と、そのデータ型を受け取って何らかの情報を返す関数を組み合わせることで、いわゆるドメインモデルのClassのようなデータ+振る舞いを表現しています。
Reactのようなimmutableな世界だとmutableなクラスベースのオブジェクトよりも単純なデータ構造としてのオブジェクトのほうが取り回しやすいと感じ、データと振る舞いを切り離す設計にしています。
type.ts
type.tsには名前のとおり型定義だけがあります。コード例はこんな感じです。
export type User = {
id: Id<'User'>
firstName: string
lastName: string
email: string | null
}
// 他、Userを作成/更新するためのUserCreateSeed/UserUpdateSeed型などもここに定義
id: Id<'User'> の部分ですが、Modelのデータ型のidは値としてはすべてstringであるものの、Branded Typesというテクニックを利用してModel間でのidの混同が起きないように定義しています。User型の定義をこのようにしておき、UserのIDを期待する引数や変数の型をstringではなく id: User['id'] のようにしておけば、間違って別のModelのIDを渡してしまっても型エラーで気付けるようになります。
かつ User['id'] はstringのSubTypeなので、標準関数などstringを期待する箇所にもそのまま渡すことができます。面倒ごとを増やさずに型チェックだけ強化できてとても便利です。
Id の実装は参考にさせていただいた記事のとおりです。
selector.ts
selector.tsは振る舞いを表現するメソッドにあたる役割となりますが、引数に渡されたデータを変更するのではなくデータを元に何らかの値や判定結果を返す関数がほとんどなので、それが伝わりやすいようにファイルをselectorという命名にしてみています。コード例はこんな感じです。
export const selectFullName = (user: User) => {
return `${user.firstName} ${user.lastName}`
}
// 必要に応じて関数を定義
小さくバラバラな関数として定義して、状況に応じて必要なものをimportする形式にしています。
Repositoryレイヤー
Repositoryは外部との通信を担うレイヤーです。主に属するのは以下です。
- 外部との通信をする関数をまとめたオブジェクト(repository.ts)
- データ型の変換層(converter.ts)
repository.ts
repository.tsでは1回の通信あたり1メソッドに分割した関数をオブジェクトにまとめて定義しています。コード例はこんな感じです。
// 外から使われるのはこのhooks。
// 必要なhooksを呼び出してその値をfactory関数に渡しrepositoryを生成して返す。
export const useUserRepository = () => {
const apiClient = useApiClient()
return React.useMemo(() => createUserRepository(apiClient), [apiClient])
}
// repository本体はfactory関数としてhooksから分離してある。
// テストが書きやすいのと、Reactに依存しないPureな関数として資産にするため。
export const createUserRepository = (apiClient: ApiClient) => ({
// 一覧取得
async getList(query: UserListQuery) {
const queryData = convertUserListQueryToData(query)
const { data } = await apiClient.getUsers(queryData)
return {
users: data.users.map(convertUserFromData),
}
},
// 詳細取得
async getItem({ id }: { id: User['id'] }) {
const { data } = await apiClient.getUser({ id })
return {
user: convertUserFromData(data.user),
}
},
// ...ほかUserの作成・更新・削除など
}
コード中のコメントでも解説を入れていますが、repositoryの大部分はapiClientを引数にとる純粋なfactory関数になっています。それとは別にhooksがあり、Global Stateから認証済みapiClientなどの依存する値をとってきてfactoryに渡しrepositoryを作成して返す動きをしています。(apiClientがGlobal Stateにあるのは認証状態をGlobal Stateで永続化しているため)
別のレイヤーからrepositoryを利用するときにはhooksを通して利用することで内部的な依存の解決を任せて簡単に利用できる一方、テストをするときはfactory側を使い、引数にmockのApiClientを渡してrepositoryを生成すれば通信を伴うことなく自由にテストができます。
最近はMSWのような通信に介在するアプローチが普及してきたのでこのような工夫も不要になってきているかもしれませんが、このあたりを作った頃にはまだそこまで普及していなかったことと、暗黙的な振る舞いなく素直に依存性を注入できる作りもわかりやすくていいかなと思って今でもこの構造をとっています。
また、hooksとfactoryを分けているのは明示的にReactの世界とPure TSの世界に境界線を引いているという意味合いもあります。前述のModelは全てPure TSで表現できるのですが、Repositoryと後述するUsecaseはGlobal Stateの操作や参照が必要な関係上、どうしても一部がReactの世界に染まる必要があります。そこで、どこまでがReactでどこからがPureなんだっけ?というのを切り分けて、Pureな部分は特定ライブラリに依存しない資産として定義するというのを意識してみました。
この先Reactから別の何かへ乗り換える可能性を現実的に想定しているというわけではありませんが、Reactのままでもメジャーバージョンアップで主流なインターフェイスが変更される可能性は無くはないので、ドメインロジック内のReactのインターフェイスの影響を受ける箇所を最小限に切り分けてみたという感じです。これが役立つかどうかはあと数年しないとわからないですね。
converter.ts
repositoryの関数内で呼んでいた convertXxx という関数がconverterで、サーバーサイド向けの型(protobufで定義されたschemaをts-protoにかけて自動生成したもの)とクライアントサイド向けの型(前述のModel)を相互に変換する層です。
コード例はこんな感じです。
export const convertUserFromData = (data: UserData): User => {
return {
id: castId<User>(data.id), // stringからBranded Typesへ型変換
firstName: data.firstName,
lastName: data.lastName,
email: data.email || null,
}
}
ナレッジワークではフロントエンドとバックエンドの繋ぎの部分にプロトコルバッファを利用しており、protoファイルに共用のmodel定義をして、そこからGoとTypeScriptで使えるファイルをそれぞれ自動生成しています。UserDataというのがその自動生成された型で、-Data というsuffixをつける命名規則にしています。
この UserData をフロントエンド内でのUser型としてそのまま使うこともできますが、ドメインモデルの型を外部での定義に直接依存させてしまうと外部での定義に変更があったときに影響範囲がとても大きくなってしまうので、共用の型をそのまま使うのではなくフロントエンド用のUser型を別途type.tsに定義し、その型と共用の型を相互変換するconverterをあわせて作成する運用にしています。
色々な方と設計の話をしていると「サーバーと共用するために定義したschemaの型をそのままフロントエンドで使ってしまい、共用schemaが少し変更されるだけでもフロントエンドの色々な箇所のコードを変えなくてはいけなくて大変」というお悩みをたびたび聞きます。
このように緩衝層としてconverterを噛ませておくと変更の影響箇所を最小限に留められるほか、たとえば外部での定義ではenumにしておきたいけど画面表示では真偽の2パターンに丸まるのでフロントエンドのmodelとしてはbooleanになっているほうが都合がいい、というようなプロパティを変換したり、肥大化してきたmodelを分割するようなリファクタリングもフロントエンドに閉じておこなえたりと、とても有益なのでおすすめです。
前述したコードの例では、「サーバーから来るemailプロパティにはメールアドレスが未設定の場合に空文字が入りうるが、フロントエンドでは未設定の値をnullとして扱いたい」という変換をconverterの1箇所で実現しています。(実例ではなくサンプルの設定です)
Usecaseレイヤー
Usecaseは「ユーザーがしたいと思うひとまとまりの処理」を表現するレイヤーです。主に属するのは以下です。
- 取得したデータのキャッシュを伴うread系のusecase(reader.ts)
- 取得したデータのキャッシュを伴わないwrite系のusecase(usecase.ts)
- キャッシュのkeyやmutatorの定義(cache.ts)
Read系のものはreader.tsにSWRのようなキャッシュ機構つきfetcherライブラリを使う形で定義しており、Write系のものはrepositoryと同じようなfactory+hooksの構造でusecase.tsに定義しています。
それら両方から参照されるキャッシュ関連のhelperとしてcache.tsがあります。
reader.ts
データのキャッシュを伴うread系のusecaseをreader.tsにまとめています。
(read = readerとしてみたのですが名前はいまひとつしっくりきてません。accessorとかでもいいのかな。ファイル名だけなのでいつでも変えられるのですが)
コードはこんな感じ。
// 一覧取得
type UserGetListResponse = { users: User[] }
export const useUserList = (query: UserListQuery) => {
const repository = useUserRepository()
return useSWR<UserGetListResponse>(
userCacheKeyGenerator.generateListKey({ query }),
() => repository.getList(query),
)
}
// 詳細取得
export type UserGetItemResponse = { user: User }
export const useUserItem = (query: { id: User['id'] }) => {
const repository = useUserRepository()
return useSWR<UserGetItemResponse>(
userCacheKeyGenerator.generateItemKey(query),
() => repository.getItem(query),
)
}
かなりシンプルですね。基本的には欲しい情報を取得できるrepositoryのメソッドを呼び出して、そのレスポンスにkeyを割り当てキャッシュする、というだけの責務です。キャッシュをしてくれるSWRがhooksなので、呼び出し単位ごとにカスタムフックとして提供しています。
ちなみにナレッジワークではSWRをSuspense対応モードで使っているため、usecaseからisLoadingやerrorなどのプロパティを返す必要はありません。Component側でSuspenseとErrorBoundaryを使ってハンドリングしています。
インターフェイスをhooksにしていることで、1点工夫が必要な箇所があります。
hooksの制約として、場合分けして呼び出せない、というものがあります。たとえばComponent側でuserIdがnullableであり、値があるときだけ詳細を取得したい、というようなケースでもhooksの呼び出しをif文で囲うことはできません。
そういうニーズがあるUsecaseでは以下のように、引数となるuserIdと返り値のUserをnullableにし、Usecase内部でidがnullでないときにだけrepositoryのメソッドをコールすることで分岐ができます。
export type UserGetItemResponse = { user: User | null }
export const useUserItem = ({ id }: { id: User['id'] | null }) => {
const repository = useUserRepository()
return useSWR<UserGetItemResponse>(
userCacheKeyGenerator.generateItemKey({ id }),
() => {
if (!id) {
return { user: null }
}
return repository.getItem({ id })
}
)
}
このあたりは Reactのuse RFCが実用化されたらComponent側で素直に条件分岐ができそうですね。
usecase.ts
データのキャッシュを伴わないwrite系のusecaseをusecase.tsにまとめています。コードはこんな感じ。
export const useUserUsecase = () => {
const repository = useUserRepository() // 前述のRepository
const mutator = useUserCacheMutator() // 前述のCache Mutator
const { addToast } = useToastMutators() // Global StateのMutator
return React.useMemo(
() => createUserUsecase({ repository, mutator, addToast }),
[repository, activityRepository, mutator, addToast],
)
}
export const createUserUsecase = ({ repository, mutator, addToast }: {
repository: UserRepository
mutator: ReturnType<typeof useUserCacheMutator>
addToast: ReturnType<typeof useToastMutators>['addToast']
}) => ({
// 作成
async createUser(seed: UserCreateSeed) {
try {
const { user } = await repository.createItem(seed)
// ユーザーが増えたので既存の一覧のキャッシュデータをクリア
mutator.mutateList()
// 画面にToast UIを表示して通知
addToast('ユーザーを作成しました')
return { user }
} catch (error) {
// 想定内エラーのハンドリング
if (error instanceof HTTPError && error.statusCode === 409) {
throw new ApplicationError('同じユーザーが既に存在しています')
}
// 想定外エラーのハンドリング
// - エラー監視ツールへ生エラーを通知
reportException(error)
// - 画面へ表示する用の汎用エラーをthrow
const errorMessage = '予期せぬエラーが発生しました。再度お試しください。'
throw new Error(errorMessage)
}
},
// ...ほか更新や削除など
}
usecase.tsもrepository.tsと同じように、別レイヤーからの呼び出し用のhooksとメインの実装であるfactory関数に分かれています。
usecaseの責務としては処理に対応するrepositoryの呼び出しの他、Cache Mutatorを使ったキャッシュの更新や、Global Stateの書き換えなどがあります。
repositoryは1通信1メソッドの単位で作成していましたが、usecaseは1ユースケース1メソッドなので、内部で複数のrepositoryメソッドを呼び出すこともあります。たとえば重複ハンドリングを事後にやるのではなく、ユーザー作成前に重複ユーザーがいないかvalidation APIを呼び出す形式にしたい、となったら await repository.createItem(seed) の前の行で await repository.validateItem(seed) を呼び出せばよいだけです。
usecaseは一番コントローラーっぽいレイヤーになるので、詳細な実装がここに直接つらつらと書かれて肥大化してしまうリスクがあります。なので別途repositoryやcache helperなどのレイヤーを用意して詳細はそこに書き、usecaseではそれらを手続き的呼び出すだけ、というふうにして見通しを良く保っています。
cache.ts
最後、reader.tsとusecase.tsから使われていたcache.tsについて。
cache.tsに書かれているのは主にふたつで、Cache Key GeneratorとCache Mutatorです。コードはこんな感じ。
// Cache Key Generator
export const userCacheKeyGenerator = {
generateListKey: ({ query = {}, includeAllQuery }: { query?: UserListQuery, includeAllQuery?: boolean }) => {
return ['USER', 'LIST', ...(includeAllQuery ? [] : [query])] as const
},
generateItemKey: ({ id }: { id: User['id'] }) => {
return ['USER', 'ITEM', id] as const
},
}
// Cache Mutator
export const useUserCacheMutator = () => {
const { mutate, mutateMany } = useMutate()
return React.useMemo(
() => ({
mutateList: () =>
mutateMany(userCacheKeyGenerator.generateListKey({ includeAllQuery: true })),
mutateItem: (
{ id }: { id: User['id'] },
newData?: UserGetItemResponse,
revalidate?: boolean,
) => mutate(userCacheKeyGenerator.generateItemKey({ id }), newData, revalidate),
}),
[mutate, mutateMany],
)
}
例としてユーザー一覧とユーザー詳細のレスポンスをキャッシュするための内容を載せています。
キャッシュのKeyは必ずCache Key Generatorを通して生成します。一覧ではKeyにページ数やlimitなどが入ったqueryを含め、詳細ではidを含めることで、リクエストに対して一意のレスポンスをキャッシュすることができます。
その下のCache Mutatorは特定のキャッシュをmutateする関数群です。SWRのmutateがhooks依存なのでカスタムフックとして提供しています。こちらも内部でCache Key Generatorを使うことでKeyの同期を担保しているのと、Listのmutateをするときにはquery問わずすべての一覧のリクエストがmutateされるように工夫しています。(ここのフラグ部分の型定義は改善の余地がありそうですね)
あとから気付いたのですが、Cache Key GeneratorはReact QueryメンテナのDominikさんのブログにあるQuery Key factoriesとほとんど同じことをしていました。だいぶ嬉しかったです。
図で振り返る
長くなりましたが以上がResource Setの簡単な説明になります。これらを踏まえて再度以下の図を見ていただくと、最初よりもなんとなくイメージが掴めるでしょうか?
なんとなく理解していただけた方は、今日からナレッジワークのフロントエンドチームで開発ができそうですね。お待ちしています。笑
余談:最初からこれでいけてたの?
最初からバチッとこの構成でいけてたかというと全然そんなことはなく、最初はRepository層を設けていなかったためにUsecase層が肥大化してしまったり、Cache Mutatorがhooksベースでなかったためにライブラリのアップデートでmutateがhooksベースになるに伴いインターフェイスの構造変更を迫られたりと、2年ほどの間に色々な変更を経て今の形に落ち着きました。
ゼロイチ時の設計について思うことですが、そもそも立ち上げ時にはアプリケーションに対する要求が出揃っていない状態なので、その時点で数年先の要求にまでぴったり合った設計をするというのは未来予知ができない人間には無理だと思います。最初の設計ではあとから振り返ったときに60点ぐらいとれていれば十分なのではないでしょうか。
大切なのは、そこからアプリケーションが拡大するにつれて新たな要求や外部環境の変化に直面し、既存の設計に痛みを感じ始めたとき、それをスルーせずにきちんとリストアップしておいて適切なタイミングで如何に解消できるかということだと思います。
機能開発と並行してアプリケーションの全体的な構造を改善していくのは簡単なことではないですが、たとえばナレッジワークの場合だと、社員メンバーが機能開発をするのと並行して副業メンバーにアーキテクチャ変更の適用をお願いすることで両方の歩みを止めることなく進化させ続けることができました。信頼して動き方を任せてくれる会社と優秀な副業メンバーの方々に感謝です。
並行してそういう動きをしてこれていなかったら、アプリケーションの大規模化にもライブラリのバージョンアップにもどこかでついていけなくなり、合わなくなった設計により生産性も下がっていき、そろそろ今ぐらいのタイミングで「一旦何ヶ月か機能開発を止めて技術的なリプレイスに集中させてください!」となっていたかもしれないですね。
ここからも事業フェーズの移り変わりから新たな要求が出てきたり、ReactやNextに新しい概念が入ってきたりと構造改善のニーズはたくさん生まれてくると思うので、今まで以上にアプリケーションが大規模になっていく中でもうまく並行して解決し続けていけるかどうかが自分やチームの腕の見せどころなのかなと思っています。
以上!
ずいぶん長めの記事になってしまいましたが、アーキテクチャは一大トピックなので細かな工夫はまだまだ語りきれていないところもあります。概観や考え方だけでも伝わって、どこか共感を生める部分があったら嬉しいなと思っています!
元記事では他にも様々な項目の構成紹介をしています。よければあわせて読んでみてください!

Discussion
大変勉強させていただきました🙇
超大作ありがとうございます!!
一点だけ質問させてください!
API絡みのロジックはUsecaseレイヤーで処理するイメージできたのですが、フォーム関連(ここではReactHookFormを想定させてください)もUsecaseレイヤーで括った場合、APIとフォーム関連のHooksはどのように管理していたかご教示いただければと思います🙇
「ユーザーがしたいと思うひとまとまりの処理」と記載していただいていたのですが、「ユーザーがFormに入力する」(フォーム関連)と「データを登録する」(API)にわけてHooksで管理するか、併せて一つのHooksにするのか判断しきれずにいます。
大変お忙しい中恐れ入りますが、お時間ある時にご確認いただけますと幸いです。
何卒よろしくお願いいたします。
ありがとうございます!
うちでは、フォーム関連の処理(submit前まで)は完全にComponentのレイヤーだけに閉じています。
うちでもreact-hook-formを使っているので、form入力中のstateはそこにあり、Componentのレイヤーからだけ読み書きしているので、フォーム操作に関してはusecase/repositoryは全く使っていません。
「データを登録する」(API)のところはご認識のとおりusecaseにしているので、submitのときに、react-hook-formから渡ってくる値をリソース作成usecaseにわたす、という感じですね!早速のご返答ありがとうございます🙇
react-hook-formの責務はComponentのレイヤーに依存させていているのですね!理解できました!
usecaseを使用する場合は、主に外部とやりとりをする時になりそうですね!
再度勉強になりました🙇ありがとうございました!