Dive deep into Amazon ECR (ECRの裏側の仕組みを知ろう)
Amazon ECR とは
コンテナのワークフローとレジストリの役割
コンテナをベースとしたワークフローを組んだ場合、「Build, Ship, Run」に基づき整理すると下記にようになります。
アプリケーションのソースコードとDockerfileというコンテナイメージを構築するためのファイルを用意し、イメージを作成していきます。
Dockerfileというのは、このファイル上にコマンドを記述することで、アプリケーションに必要なライブラリをインストールしたり、コンテナ上に環境変数を指定する役割を持ちます。
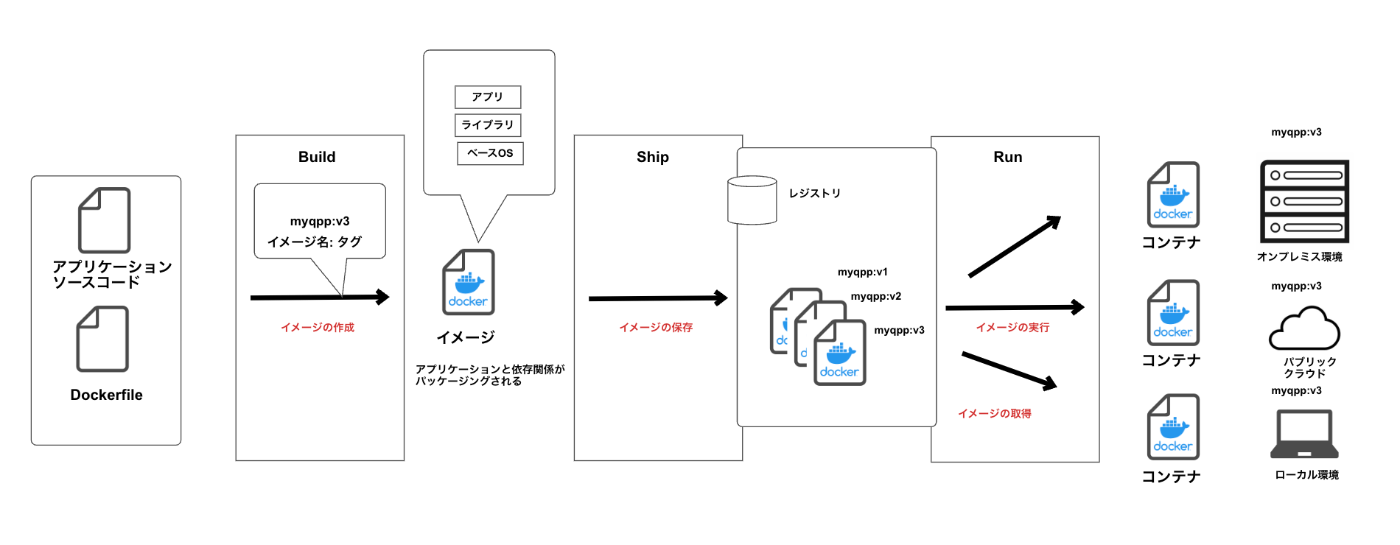

さて、ここで重要になってくるのはこのコンテナイメージを保存する先ですね。
そこで出てくるのが、レジストリと呼ばれるものです。
レジストリとは、コンテナイメージを保存するサービスで、Dockerレジストリを基点としてさまざまなプラットフォームにイメージを配布したり、利用者間でイメージを共有できます。また、Docker レジストリは複数のリポジトリから構成されますが、インターネット上に公開される「パブリックリポジトリ」と特定の組織やチーム間のみでアクセス可能な「プライベートリポジトリ」に分けられます。
Amazon ECR
今回、お話しするAmazon ECRというのは上記で説明したコンテナイメージのレジストリをマネージドで提供するサービスです。
基本的な操作は、Docker CLIコマンドを利用し操作していきます。
ちなみにコンテナイメージやアーティファクトはAmazon S3に保存されます。
サポートする形式は、Dockerイメージ、Open Container Initiative(OCI)イメージ、OCI互換アーティファクトになります。
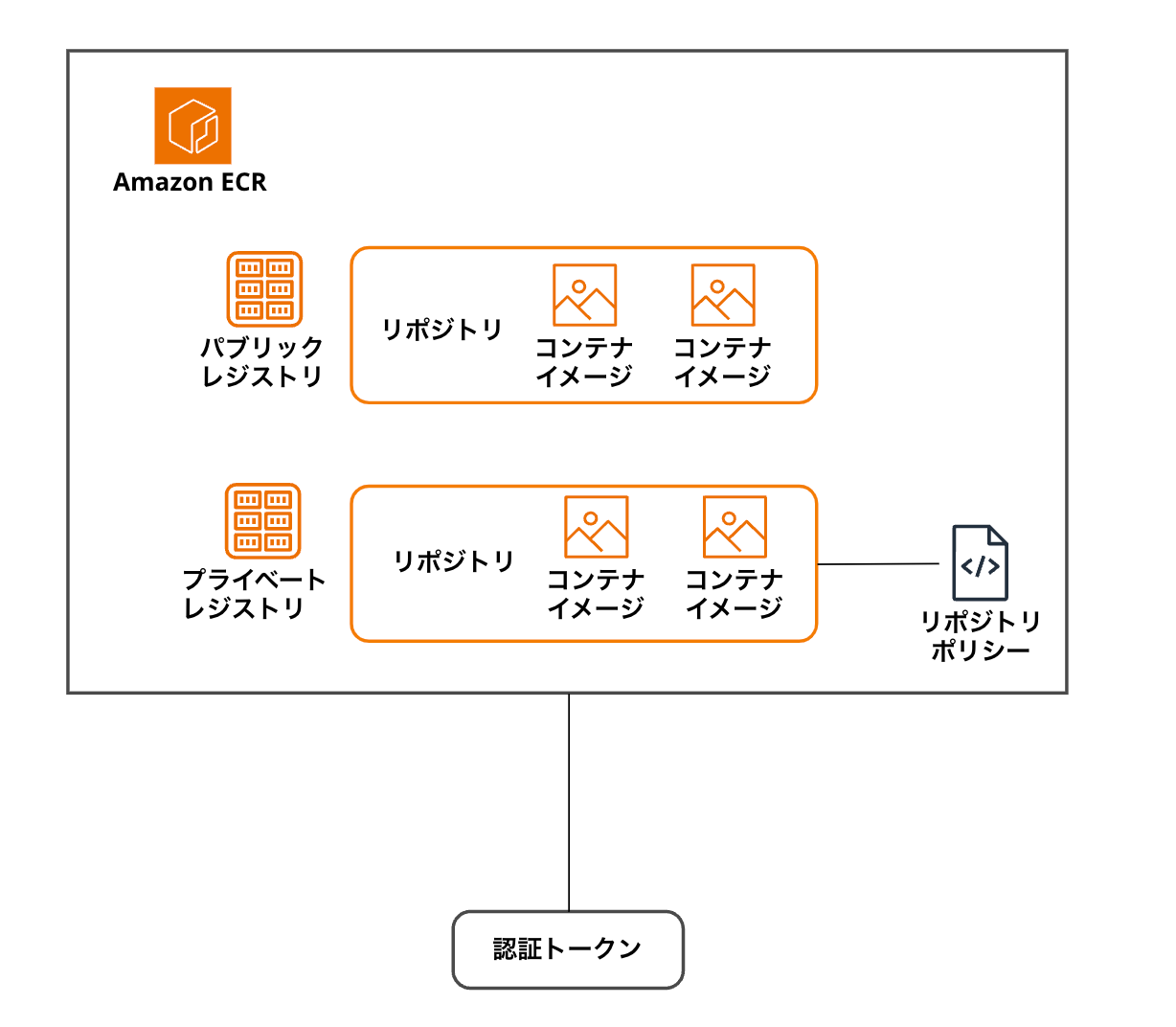
名称の定義
Amazon ECRを使うとレジストリ、リポジトリ、リポジトリポリシー、認証トークンという言葉が出てきます。
レジストリ
レジストリというのは、複数のリポジトリから構成され、AWSアカウントごとに用意されています。
Dockerクライアントを認証して利用することができます。
また、利用する際に、"プライベートレジストリ"と"パブリックレジストリ"が選択できます。
プライベートレジストリでは、コンテナイメージの操作にIAMベースの認証が必須になります。
パブリックレジストリでは、Amazon ECR Publicに公開され、認証無しでコンテナイメージの操作をすることができます。また、Amazon ECR Publicに公開されているので、公開されているイメージを検索することもできます。
リポジトリ
リポジトリというのは、レジストリの中にあり、Dockerイメージ、Open Container Initiative(OCI)イメージ、OCI互換のアーティファクトを保存することができます。
リポジトリポリシー
リポジトリとリポジトリ内のイメージへのアクセス権を制御するために利用します。
認証トークン
IAM認証情報を利用して、レジストリに対して認証します。
Amazon ECRの全体像
実際にAWSコンソールから見たAmazon ECR

ここまでが、Amazon ECRの基本の"き"となります。
Dive deep into Amazon ECR
2023年に行われたAWS re:Invent 2023の中の、breakout sessionに"Dive deep into Amazon ECR"というものがありました。
現地会場で私もセッションを聞いていたのですが、セッション対象者がLevel400となっているセッション(対象とする聴講者としてはExpertレベルを指します)ということもあり、何が語られるんだと胸を躍らせ参加していました。
今回はここで語られた内容をおさらいするために本記事を執筆いたしました。
シンプルなコンテナレジストリサービスの裏側がどうなっているのかをより多くのエンジニアの皆様が知るきっかけになればと思います。
Amazon ECRの特徴
AWSを利用しコンテナのワークロードをアーキテクトしていると、きっとAmazon EKSやAmazon ECSから作成したコンテナイメージを取得するような動きをさせたいと思います。
これを行うには、レジストリが欠かせません。
EKSやECSが必要な時にいつでもコンテナイメージをレジストリから取得するツールとしてECRが存在しています。

使用するユースケース例を1つ挙げてみましょう。
ローカルPC上で作成したコンテナイメージをECRにプッシュします。
コンテナイメージの管理については、業界標準が存在し、Open Container Initiative(OCI)と呼ばれるものがあります。
なので、ECR上に新たなリポジトリを作成するとイメージをプッシュするために使用するOCIコマンドが表示されます。開発者は、タグをつけてローカルからECR上にプッシュすると、レジストリに保存されるので、保存されているイメージをpullし、ECRやEKSといったコンテナサービスで動かす形です。
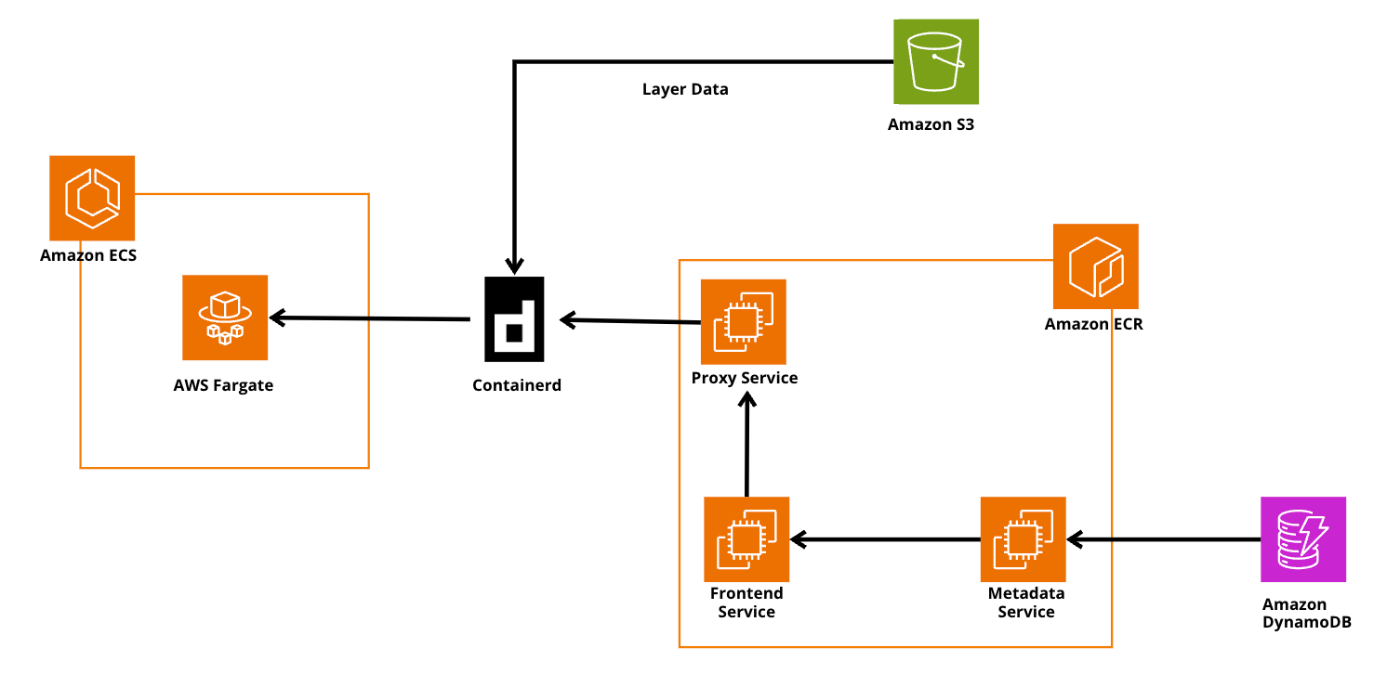
Amazon ECRが裏側でどうなっているのか
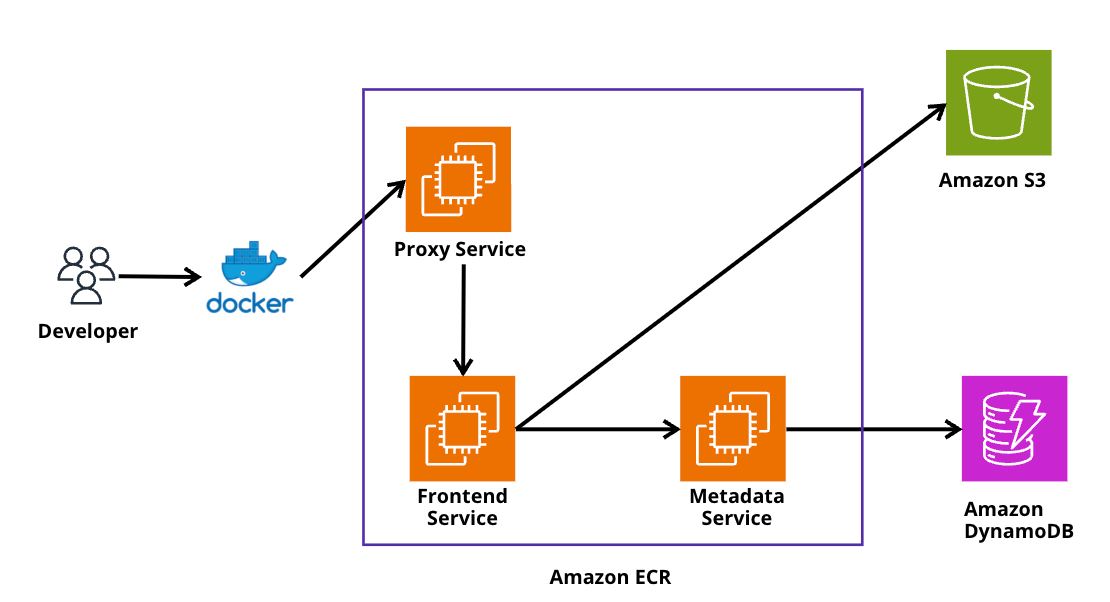
下記がAmazon ECRの裏側を簡単に表したものです。
セッション内で語られたこととしては、開発者はDocker CLIを通してAmazon ECRと通信する場合、ECR内のFrontend Serviceと直接通信するのではなく、Proxy Serviceを経由していることになります。
このProxy ServiceはOCIを解釈するので、Docker pushを行うとProxy Serviceがコマンドを受信し、Frontend Serviceが他のAWSサービスのFrontend Serviceが理解できるAPI呼び出しに変換され、その裏にいるバックエンドサービスと連携していきます。
ここでいうバックエンドサービスとは実際のコンテナイメージを保存しているS3やMetaData用のDynamoDBなどが該当します。
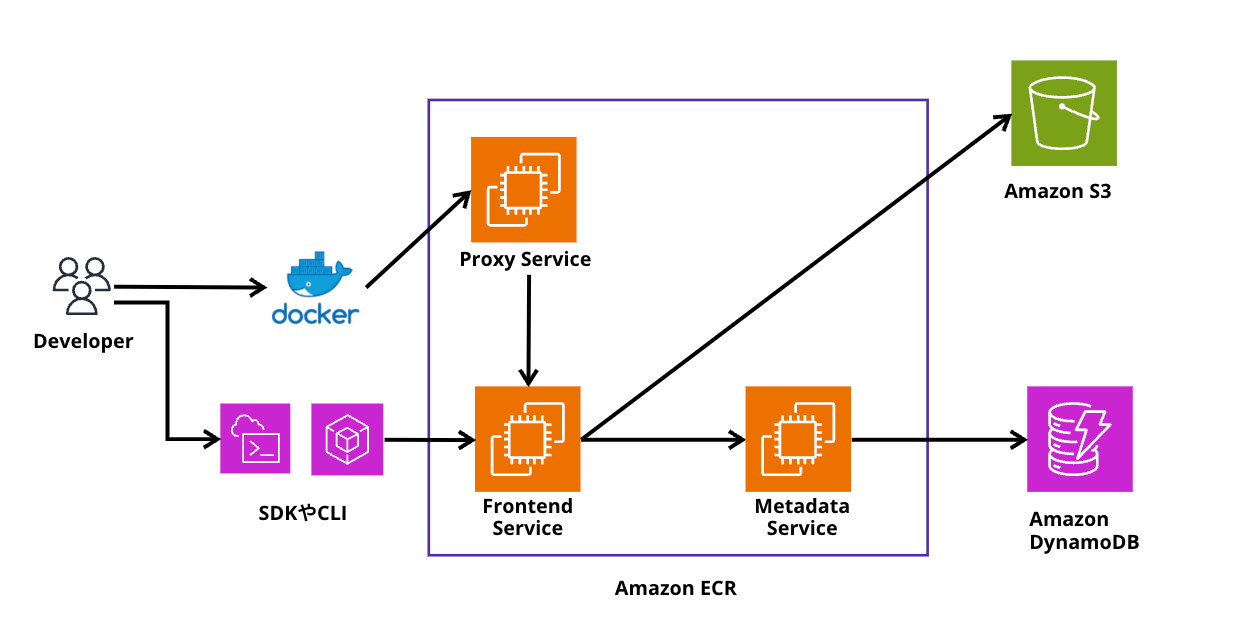
ちなみに、AWS CLIやSDKを使用した場合は、Docker+Procy Serviceを経由せずに、直接Frontend Serviceに対して通信を行うようです。
コンテナイメージとは
コンテナイメージは、とてもシンプルで、まずイメージのメタデータを持つJSONファイルの"Manifest"とレイヤーと呼ばれるファイルシステムのようなもので、複数のレイヤーがマージされコンテナイメージが構成されます。
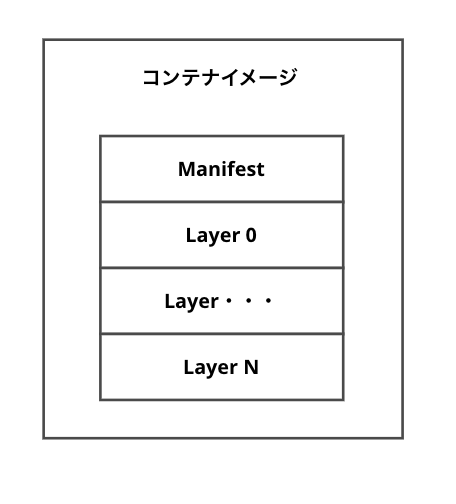
Manifestの中身を確認
下記のコマンドを実行すると、特定のコンテナイメージのmanifestを調査することができます。
docker manifest inspect --verbose hello-world
❯ docker manifest inspect --verbose hello-world
[
{
"Ref": "docker.io/library/hello-world:latest@sha256:e2fc4e5012d16e7fe466f5291c476431beaa1f9b90a5c2125b493ed28e2aba57",
"Descriptor": {
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"digest": "sha256:e2fc4e5012d16e7fe466f5291c476431beaa1f9b90a5c2125b493ed28e2aba57",
"size": 861,
"platform": {
"architecture": "amd64",
"os": "linux"
}
},
"Raw": "ewogICJzY2hlbWFWZXJzaW9uIjogMiwKICAibWVkaWFUeXBlIjogImFwcGxpY2F0aW9uL3ZuZC5vY2kuaW1hZ2UubWFuaWZlc3QudjEranNvbiIsCiAgImNvbmZpZyI6IHsKICAgICJtZWRpYVR5cGUiOiAiYXBwbGljYXRpb24vdm5kLm9jaS5pbWFnZS5jb25maWcudjEranNvbiIsCiAgICAiZGlnZXN0IjogInNoYTI1NjpkMmM5NGUyNThkY2IzYzVhYzI3OThkMzJlMTI0OWU0MmVmMDFjYmE0ODQxYzIyMzQyNDk0OTVmODcyNjRhYzVhIiwKICAgICJzaXplIjogNTgxCiAgfSwKICAibGF5ZXJzIjogWwogICAgewogICAgICAibWVkaWFUeXBlIjogImFwcGxpY2F0aW9uL3ZuZC5vY2kuaW1hZ2UubGF5ZXIudjEudGFyK2d6aXAiLAogICAgICAiZGlnZXN0IjogInNoYTI1NjpjMWVjMzFlYjU5NDQ0ZDc4ZGYwNmE5NzRkMTU1ZTU5N2M4OTRhYjRjZGE4NGYwODI5NDE0NWU4NDUzOTQ5ODhlIiwKICAgICAgInNpemUiOiAyNDU5CiAgICB9CiAgXSwKICAiYW5ub3RhdGlvbnMiOiB7CiAgICAib3JnLm9wZW5jb250YWluZXJzLmltYWdlLnJldmlzaW9uIjogIjNmYjZlYmNhNDE2M2JmNWI5Y2M0OTZhYzNlOGYxMWNiMWU3NTRhZWUiLAogICAgIm9yZy5vcGVuY29udGFpbmVycy5pbWFnZS5zb3VyY2UiOiAiaHR0cHM6Ly9naXRodWIuY29tL2RvY2tlci1saWJyYXJ5L2hlbGxvLXdvcmxkLmdpdCMzZmI2ZWJjYTQxNjNiZjViOWNjNDk2YWMzZThmMTFjYjFlNzU0YWVlOmFtZDY0L2hlbGxvLXdvcmxkIiwKICAgICJvcmcub3BlbmNvbnRhaW5lcnMuaW1hZ2UudXJsIjogImh0dHBzOi8vaHViLmRvY2tlci5jb20vXy9oZWxsby13b3JsZCIsCiAgICAib3JnLm9wZW5jb250YWluZXJzLmltYWdlLnZlcnNpb24iOiAibGludXgiCiAgfQp9",
"OCIManifest": {
"schemaVersion": 2,
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"config": {
"mediaType": "application/vnd.oci.image.config.v1+json",
"digest": "sha256:d2c94e258dcb3c5ac2798d32e1249e42ef01cba4841c2234249495f87264ac5a",
"size": 581
},
"layers": [
{
"mediaType": "application/vnd.oci.image.layer.v1.tar+gzip",
"digest": "sha256:c1ec31eb59444d78df06a974d155e597c894ab4cda84f08294145e845394988e",
"size": 2459
}
],
"annotations": {
"org.opencontainers.image.revision": "3fb6ebca4163bf5b9cc496ac3e8f11cb1e754aee",
"org.opencontainers.image.source": "https://github.com/docker-library/hello-world.git#3fb6ebca4163bf5b9cc496ac3e8f11cb1e754aee:amd64/hello-world",
"org.opencontainers.image.url": "https://hub.docker.com/_/hello-world",
"org.opencontainers.image.version": "linux"
}
}
},
・
・
・
hello-worldというコンテナイメージのmanifestを見ると、スキーマのバージョンや、layersの情報、digest情報、layersのサイズを確認することができます。
そしてこれは一例で、実際には数多くのコンテナイメージが大小様々な形で存在していることになります。
Amazon ECRではこの大小サイズの違うコンテナイメージを効率よく保存するように設計されています。
次に、重要な概念としてコンテナイメージにはタグが付与でき"多対1"の関係でコンテナイメージ付与することができます。

つまりは、Amazon ECRでは、この"多対1"で付与されたタグを含む全てのコンテナイメージを保存し、インデックスを作成する必要があります。
アーキテクチャの図を見直した時に、Frontend Serviceの裏側にいるMetadata Serviceというのが全てのタグと全てのメタデータのインデックスを作成し、DynamoDBに保存します。
次にBLOBオブジェクトですが、JSONオブジェクトで形成されるManifestはBLOBオブジェクトとみなされ、S3に保存されます。また、大きなレイヤーもS3に保存されるようです。
Amazon ECRに対する全てのリクエストの動き
次に上記のアーキテクチャで各コンポーネントがどんな動作をするのかをみていきます。
重要なことは、Docker, Helm, OCI基準のクライアントツールとやりとりし、内部のAWSリソースへプロキシするのが、Proxy Serviceの役割です。
Frontend Service自体がプロキシされAWS内のリソースをAPIコールします。
ただ、重要なのはこのFrontend Serviceには他にもいくつかの役割を持っていることです。
それは、認証/認可/throttleになります。
つまりは、Frontend Service自体がIAMポリシーをチェックしトークンの有効性を確認、Amazon ECRのレジストリ、リポジトリに対してアクションを実行するそんな動きとなるようです。
そして、最終的にはリクエストのthrottleもここのFrontend Service自体で行います。
Amazon ECRのthrottleが重要なこと
セッション内で驚いたのは、Amazon ECR自体がどれだけ多くの人が世界中で利用しているのかに触れた時です。月に2億pushを処理しているようです。データ量としては、月に数百ペタバイトのデータとなるようです。
そのため、throttleはECRの中でも重要な処理となります。
ちなみにthrottleというのは、AWSにおけるサービスの一定時間内に送信できるリクエスト数を制限するプロセスのようなものだと思ってください。
これをやらないとAWSが提供するコンピュートリソースをお客様が利用した際に不公平が生じる可能性があり、それを防ぐ役割を持っています。
Amazon ECR に対するDocker pushの具体的な処理の裏側
動作自体を実際にやってみてわかると思うのですが、我々開発者はDocker pushをAmazon ECRに対して行っても1Stepでできている印象を持っていると思います。
しかし、実際には複数回DockerクライアントからAmazon ECRは呼び出されているようです。
実際の処理
実際には、下記の回数だけ内部のAPIが叩かれているとのことです。
ここで重要なのは、最初にレイヤーのpushから始まり、Manifestのpushで終わることです。
これは、Dockerのpushが途中で途切れてもいいように各レイヤーのpushを実行し、全て完了したらmanifestのpushで終わるそんな風に処理したかったからだと述べられています。
Push Layers
1 ecr:BatchCheckLayerAvailability
2 ecr:initiateLayerUpload
3 ecr:UploadLayerPart
4 ecr:CompleteLayerUpload
5 Repeat for all Layers
Push Manifest
1 ecr:PutImage
Push Layers
1 ecr:BatchCheckLayerAvailability
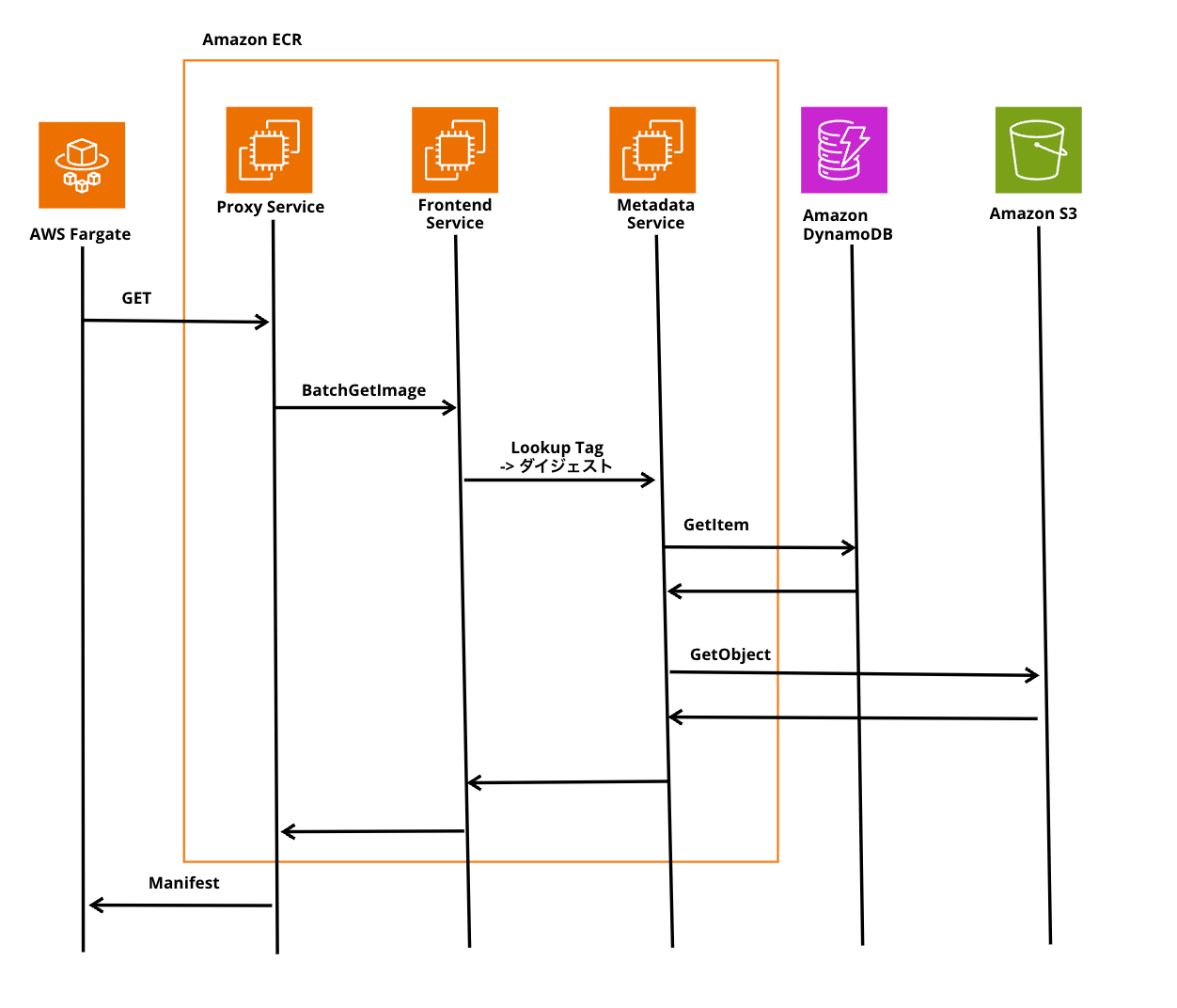
じゃあ実際のAPIコールの部分に注目してみます。
1発目のrequestでecr:BatchCheckLayerAvailabilityを実行しているのは、すでに同じコンテナイメージがあるのかをチェックしたいためです。同じものが既にあってpushするのは通信処理が無駄に、それだけAWSとしては帯域幅を使ってしまうので、この時点で判断したいというのが理由にあります。
さらにこれを実現するために、前段の内部のDocker ClientはProxy Serviceに対して、HTTPであるヘッドリクエストを飛ばすことで実現しているようです。
その後、Proxy ServiceがFrontend Serviceに対してecr:BatchCheckLayerAvailabilityのAPIをコールするそんな動きとなります。
その後、Frontend ServiceがMetadata Serviceに転送し、DynamoDBをチェック(GetItem)してダイジェストがあるのかを確認します。
ダイジェストは不変で、変更できないのでこのダイジェストでチェックするそんな動きとなるようです。
最終的なレスポンスは、200か404が返ります。
2 ecr:initiateLayerUpload
次に、404が返却、つまりは同じイメージが存在しない場合については、2の処理を実行します。
その場合は、最初のレイヤーをアップロードしていきます。
面白いと講演者が言っているのは、この時のクライアント側の動きにあります。
このアップロード処理については、どのクライアントも基本並行で行います。
たとえば、レイヤー数が20個ある場合、1度に最大5回を並行して実行する動きになるようです。
動きとして、まず、DockerがProxy ServiceにPOSTのリクエストを送信します。
その後、proxy ServiceがFrontend Serviceに対して、API Request(ecr:initiateLayerUpload)を実行します。
そして、Metadata Serviceに転送し、ここでは、BLOBを保存したいので、DynamoDBではなく、先ほどのアーキテクチャに出てきたS3に対して、CreateMultipartUploadを行なっているようです。
重要なポイント
ここのステップでは、あくまで保存したいデータというのは送っていません。あくまでこれからのステップでBLOBをアップロードするよといった情報を送っているだけになります。
なので、最終的なレスポンスにはクライアント側に対してアップロードIDを伝え、次のステップでもらったアップロードID使用して実際のデータをアップロードしていきます。
3 ecr:UploadLayerPart
ここでは、先ほどのアップロードIDを使用して、Proxy ServiceからS3までの処理をループしてデータをアップロードしていきます。
たとえば、10GBのイメージを保存しようと思った場合、その全てをストリーミングする単一のHTTP接続で実現します。
10GBだと大体20メガバイトのチャンクに分けて送信するようです。
重要なポイント
ここでMetadata Serviceがダイジェストと呼ばれるものを生成し、DynamoDBに保存します。
このダイジェストというのは暗号ハッシュで、"digest": "sha256:e2fc4e5012d16e7fe466f5291c476431beaa1f9b90a5c2125b493ed28e2aba57"こんな表現で生成されます。
これは、Amazon ECR側が受信しているバイト、またはクライアントがAmazon ECR側に送信しようとしていたものを知るための計算に使用するものだと述べています。
後半のManifestで実際にこのダイジェストを送信することは、上記のManifestの中身を調査した際のJSONを見ればなんとなく分かるでしょう。
最終的なダイジェストの評価が終わるとS3へもアップロードを行います。
現時点では、全てのバイトをS3に保存しているとのことです。
レイヤーが作成終わったらクライアント側に終わったことを知らせます。
仕様には書いていないものの、地中での作業中止でも、その途中からアップロード操作ができるようになっており、やり直すことも容易にできます。

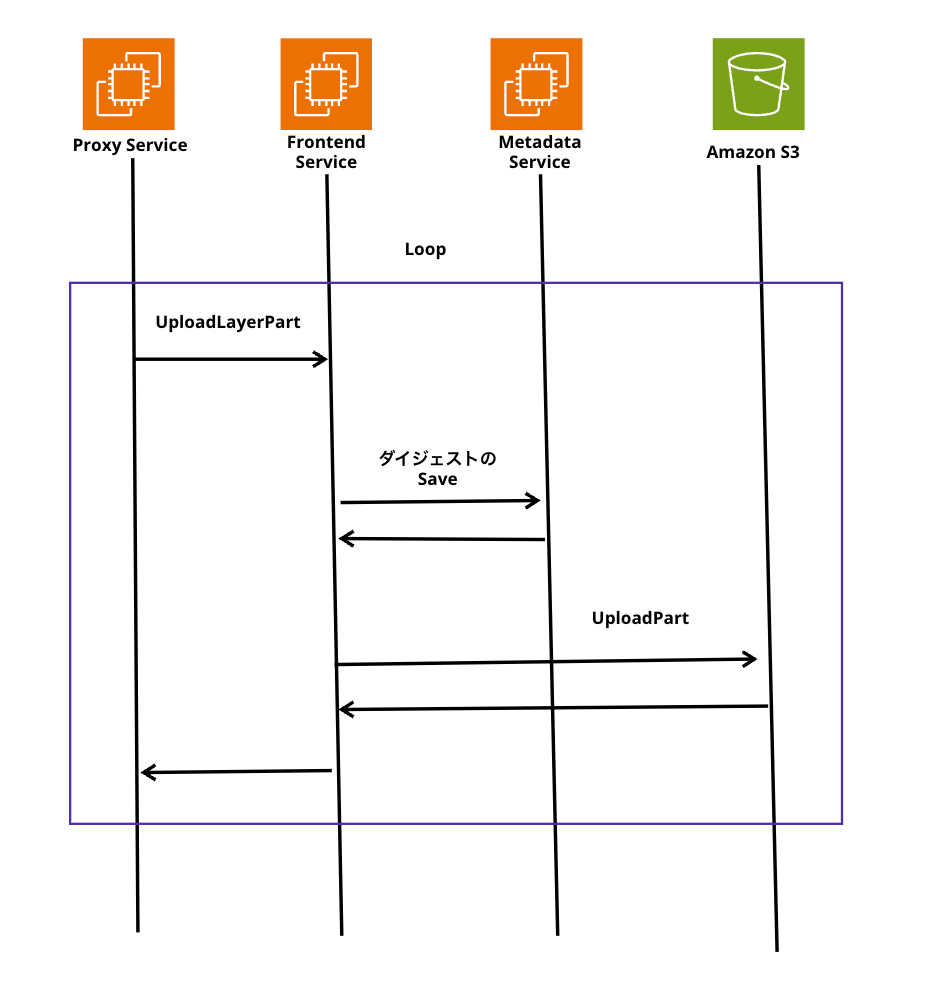
4 ecr:CompleteLayerUpload
ここまできたときに大事なことは、果たして全てのレイヤーを送信することができたのかという情報はAmazon ECR側は知りません。
なので、このステップではクライアントが完了したことを知らせる処理を行います。
Proxy ServiceからS3まで一貫したフローを行い、全てのレイヤーがアップロードできたことを知らせます。
5 Repeat for all Layers
あるコンテナイメージに大量のレイヤーが含まれていた場合、クライアントが並行で送信することを決定した場合は、このシーケンスを各レイヤー全てに対して並行で実行します。
Push Manifest
1 ecr:PutImage
さてここまできたら処理自体が完了か、と思いきや、先ほどから何回も述べているManifestを最後にPushしてあげることでコンテナイメージをAmazon ECR上に保存することができます。
下記がその時のシーケンス図になるのですが、クライアントはmanifest urlへのPutリクエストを使用してManifestをpushします。これはputimageと呼ばれるAPIになります。
PutImageはDynamoDBとS3に完全なオブジェクトを保持しているので、S3に対して、JSONのBLOBを保存します。その後コンテナイメージが保存できたことをクライアント側に返すそんな一連の処理を行います。
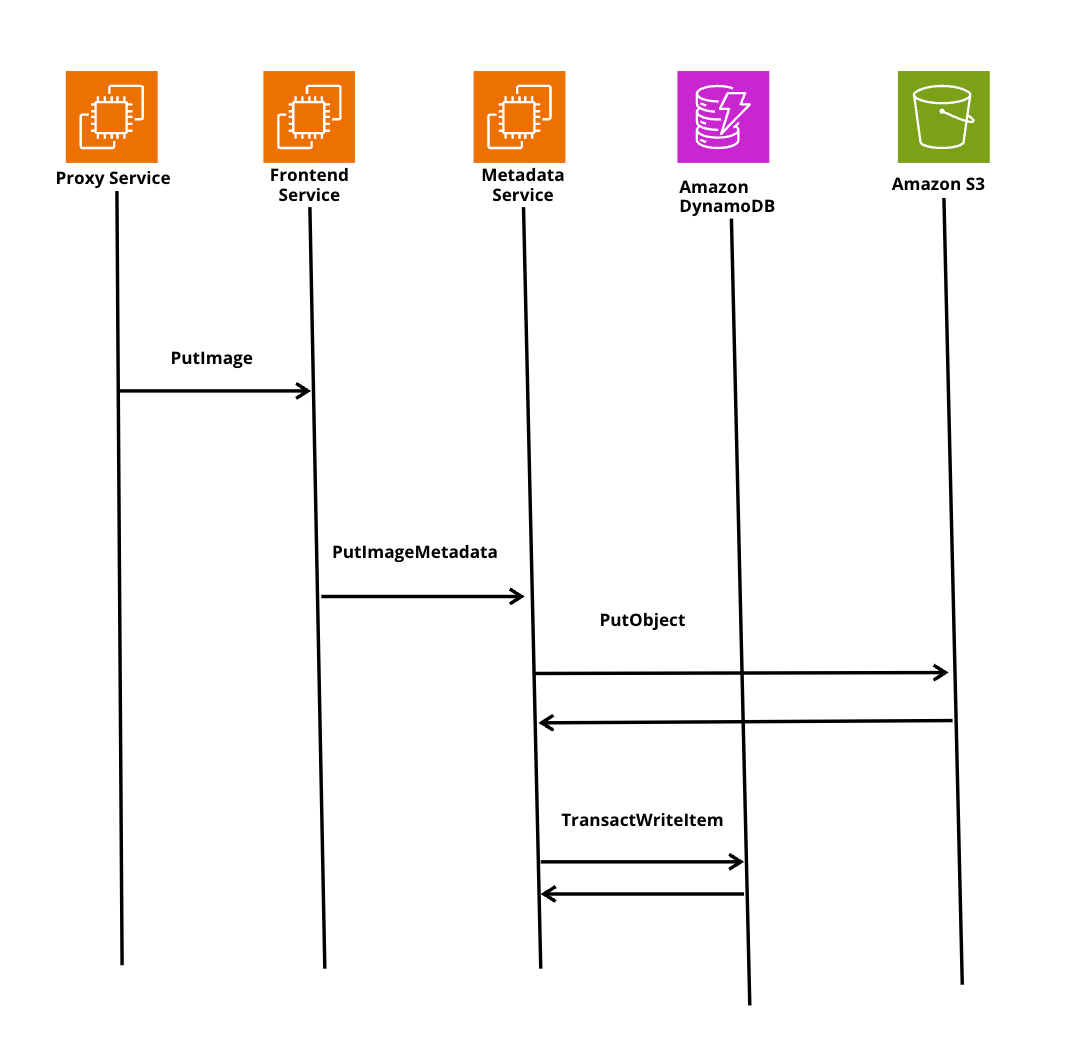
ECRにコンテナイメージをPushした後は??
もちろんコンテナのワークロードをAWSで実現しているのであれば、EKSやECSを使っているのではないかと思います。
下記のようにECSにはイメージがないので、コンテナのワークロードを実行したい場合は、ECRからコンテナイメージを取得してきます。
これを実現するのは、ECSですとタスク定義を作成し、その中にどのコンテナイメージを使い、ECSがECRに対してコンテナイメージを取得することができるような権限を振ってあげる事で実現できます。
言ってしまえば、このタスク定義と権限があればECSは自由にECRからコンテナイメージを引っ張ってきて利用することができるという事です。
ECS上でECRからコンテナイメージを取得する動作の裏側
実は、一見シンプルなPullの動きに見えてもこの動作の裏側でもかなり複雑は処理が行われています。
まず、注目いただきたいのは下記の図です。
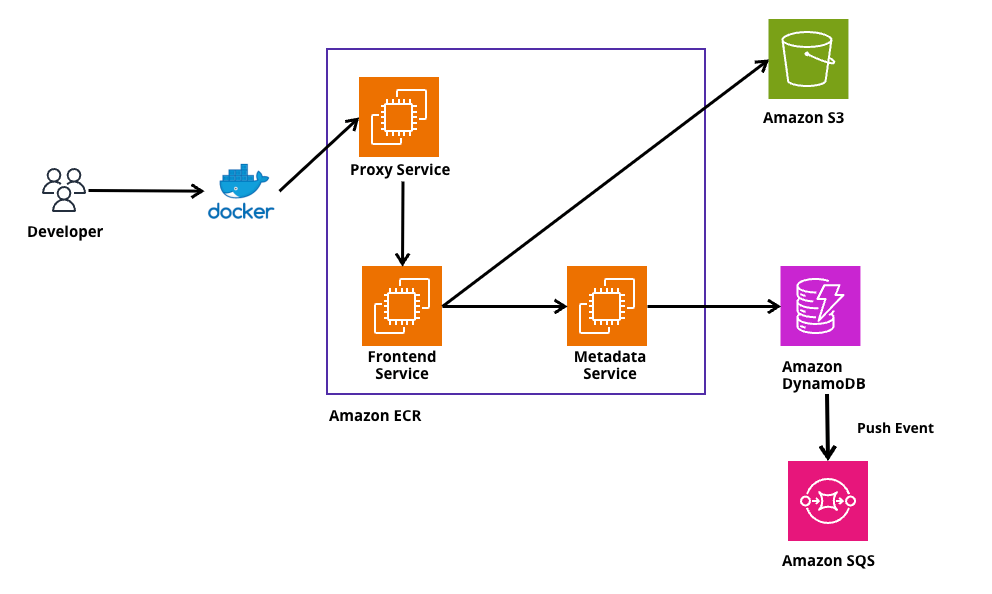
コンテナイメージをつかさどるレイヤーのデータはECR内のサービス(Proxy ServiceやFrontend Serviceなどを指している)を経由せずに、直接クライアント側に流れます。
さてこれは、なぜPushの時の動作とは異なるのか。それはPushの動作とpullの動作を使用する頻度に起因してだと思われます。
なぜ、PushとPullでは内部の動気が違うのか
Pushの時の話に戻るのですが、ECRはPushの処理だと月にだいたい2億回くらい行われます。
逆に、Pullだとどうなるのかというと、月にだいたい700億回くらい行われるようです。驚きですよね。
ただ、冷静に考えてみれば分かるのですが、我々、開発者(CI/CDとかでも一緒)が作成したコンテナイメージがECRのようなコンテナレジストリにPushされ、実際のコンテナを動かすサービスにデプロイするとき、そのサービス例えばECSとしましょう。開発者が開発した資源(実際のサービス)がECS上で大規模なフリート(ECS上において複数サービス構成にしていたり、複数のタスクを使用している)を所有している場合、それらはコンテナを起動するためにECRからPullする必要があります。そのため、PushよりPullの方が行われる操作としては多くなるのは確かになと思いました。
実際の処理
Pullした際に実際は、下記のAPIが裏側で叩かれているとのことです。
Pushの時の動作と同様に1つずつ見ていきましょう。
ここで重要なこと、それはPushと比べたら処理自体はシンプルだが、Push時の操作とは逆転しており、まず初めにManifestをPullするところから始まります。
Pull Manifest
1 ecr:BatchGetImage
Push Layers
1 ecr:GetDownloadUrlForLayer
2 Download layer directly from S3
1 ecr:BatchGetImage
まず初めにManifestを取得する処理では、特定のManifestを取得するため、タグもしくはダイジェストを頼りにECRはDynamoDBのテーブルを検索しにいきます。
最終的には、ManifestはJSON BLOBでS3に保存されているので、S3に問い合わせを行い、その結果をクライアント側に返します。
これにより、クライアント側は、Manifestに記載されているコンテナイメージの全てのレイヤーの情報が分かるので、後続の処理で該当するレイヤーを取得する動きになるのです。
1 ecr:GetDownloadUrlForLayer
ここでは、上記でManifestを取得し必要なレイヤー情報がわかったので、そのレイヤーを取得します。
重要なことは、このフェーズでは、S3に保存したレイヤー取得するわけではなく、DynamoDBに書き込まれている、レイヤーが保存されているS3のPresigned URLがクライアント側へ送信されます。
この仕組みにより、多くのデータをオフロードできるようになります。
なるべく、ECRの裏にあるサービスに負荷をかけないようにするため、オフロード先はS3ということですね。
クライアント側(ContainerdやDocker)は、S3のPresigned URLから直接S3にあるレイヤーのデータを引くことができます。
S3のリンクがPresigned URLになっているのは、分かりますよね。なぜならレイヤーのデータが公開設定されていたらまずいので、Presigned URL経由で引いてくる必要があるためです。
2 Download layer directly from S3
最後は、すごくシンプルで先ほど返却されたPresigned URLを使用して、S3からレイヤーのデータを取得するだけになります。
ECRの様々な機能の裏側
クロスリージョン/クロスアカウントレプリケーション機能
例えば、DR対応が必要で、1リージョン(例えば東京としよう)内にあるコンテナイメージを使用して、複数リージョン(東京, 大阪, オレゴン, etc・・・)で稼働しているECS + Fargateでその1リージョンにあるコンテナイメージをPullし、使いたい場合を想像してみてください。
ECRは機能として、レジストリのクロスリージョン/クロスアカウントレプリケーションを提供しています。

今回は、クロスリージョンの機能についてを見ていくのですが、動きとしては、クロスリージョンレプリケーションが有効になっている状態で、ローカルからコンテナイメージをある1リージョンにあるECRにPushします。
短時間の間でECRはレプリケーションルールに従い、レプリケーションを裏で実行します。
さて、この機能、Pushされてからコンテナイメージが保存され、クロスリージョンレプリケーションされるのに短時間で処理されます。
短時間でECRがクロスクロスリージョンレプリケーションを可能にしている理由
これを実現しているのは、DynamoDBの先にある非同期処理で実行するAmazon SQSを組み合わせたこ戸にあります。
基本的にPushもPullも同期的に行いユーザはコマンドの実行結果を待ちます。
このクロスリージョンへのレプリケーションはユーザのコマンド処理の中で同期的に実行させる必要もないですよね。
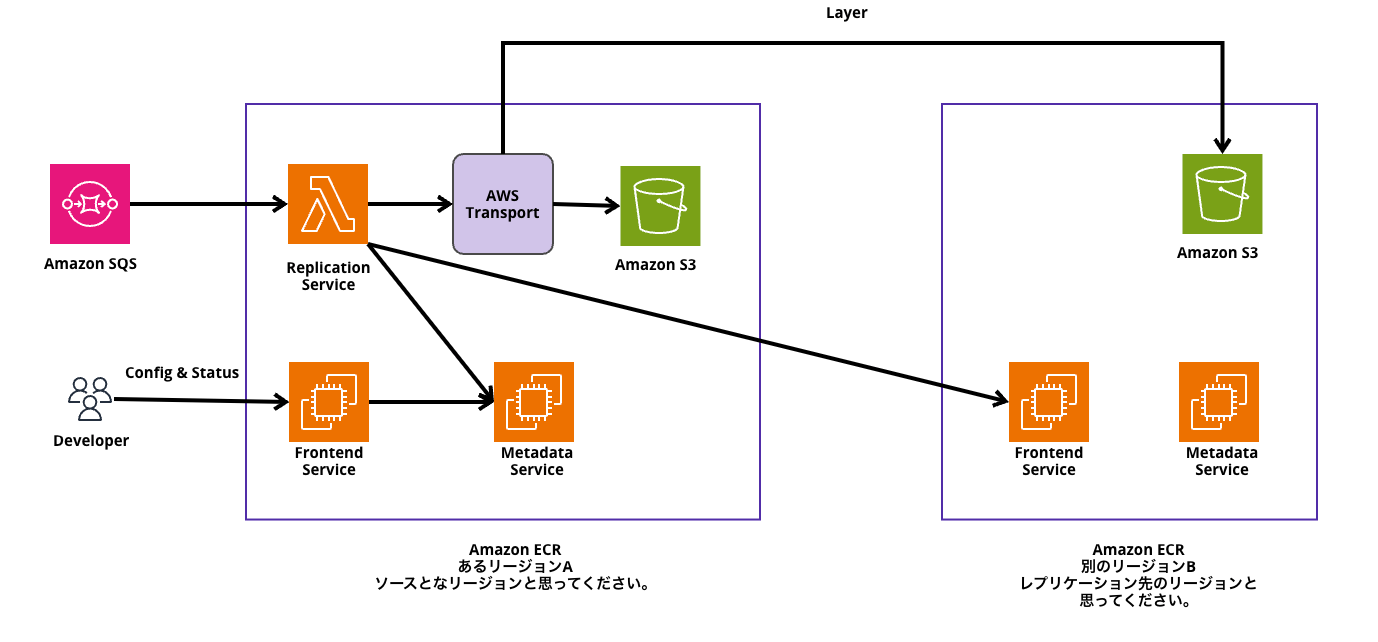
なのでSQSはDynamoDBをリッスンし、処理が来たら非同期でその後の処理を実行します。
後続の処理としては、キューを使用して、Lambdaを実行。
Lambdaが、レプリケーション元のリージョンにあるECRの裏にいるMetadata Serviceと、レプリケーション先の別リージョンにあるECRの裏側にいるFronend ServiceにImageのMedataを送ります。
Metadataだけではなく、S3に格納されているレイヤーやmanifestといったデータも転送する必要があります。
さてここですごく重要な問題が発生します。
それは、このレプリケーションの処理に時間がかかってくる可能性があるということですね。なぜならリージョンが物理的に離れていれば離れているだけ処理に時間がかかってしまうためです。
そこで、AWS社内でAWS Transportというサービスを経由して、他のリージョンに転送しているようです。
※ なお、このAWS Transportというサービスは公開されておらず、内部でしか利用ができない模様。(動画内では、このように解説しております。)
このサービスの効果は、リージョン間でデータを効率的に転送させることができるようなものらしいです。
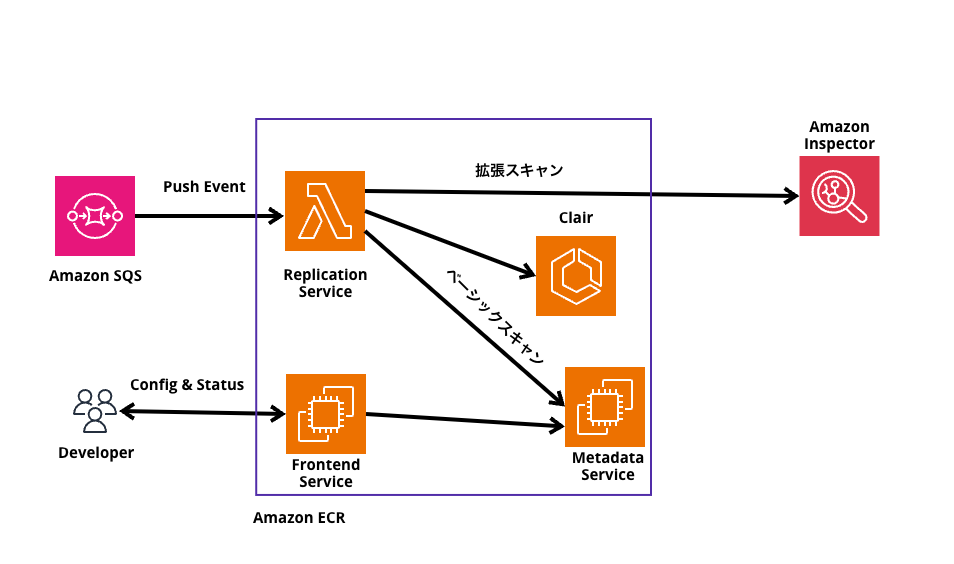
スキャンモード(ベーシックスキャンと拡張スキャン)
ECRの画面を見た時にScaningという機能があるのを見たこと、使ったことがある人も多いのではないでしょうか。

ベーシックスキャン
- オープンソースの Clair プロジェクトのCVEデータベースを使用したコンテナイメージの脆弱性スキャン機能です。
- イメージのプッシュ時にスキャンするか、手動実行
拡張スキャン
- Amazon Inspector と統合しリポジトリの自動で継続的なコンテナイメージの脆弱性スキャン機能です。
実はre:Invent2023のワーナーのKeynote中にこのECRスキャン周りで新しいアップデートが出ています。
機能としては、下記のようなことがつらつら書いてあるのだが、要はベーシックスキャンは、オンデマンドスキャンが可能なので、CI/CDに組み込めたが、拡張スキャンは対応していなかったのがこれまででした。
今回発表されたアップデートにより、AWS SDK/CLI にて実行が可能になったというものです。
もちろん”inspector-scan API ”というAPIを利用し、組み込むこともできそうという感じですね。
1.開発ツールとの統合によるコンテナイメージのセキュリティ評価
JenkinsやTeamCityなどの主要な開発ツールとの統合により、開発者は
CI/CDツール内でコンテナイメージのソフトウェア脆弱性を評価できるようになり、
ソフトウェア開発ライフサイクルの早い段階でセキュリティを向上させる
2.CI/CDダッシュボード内の評価結果と自動対応
評価結果はCI/CDツールのダッシュボード内で利用可能となり、開発者は
重大なセキュリティ問題に対して、ビルドのブロックやコンテナレジストリへの
イメージプッシュの阻止などの自動対応を取ることができる
さてさて本題に戻り、このスキャンの仕組みについてなのですが、先ほどのECRのクロスリージョン/クラスアカウントレプリケーションの仕組みと非同期処理は全く同じです。
SQSにPushイベントでキューを格納し、その後の処理が変わってきます。
SQSでキューを受けてからの裏の処理は流石に違います。
どうなっているかというと、ベーシックスキャンをするイベントの場合は、AWSが管理するClairエンジンにリダイレクトするか、拡張スキャンであればAmazon Inspectorにリダイレクトします。
ただ、そのどちらもすキェんの結果は、同じMetadata Serviceにリダイレクトされるようです。
そこから、我々開発者がスキャン結果を確認したりするとのことです。
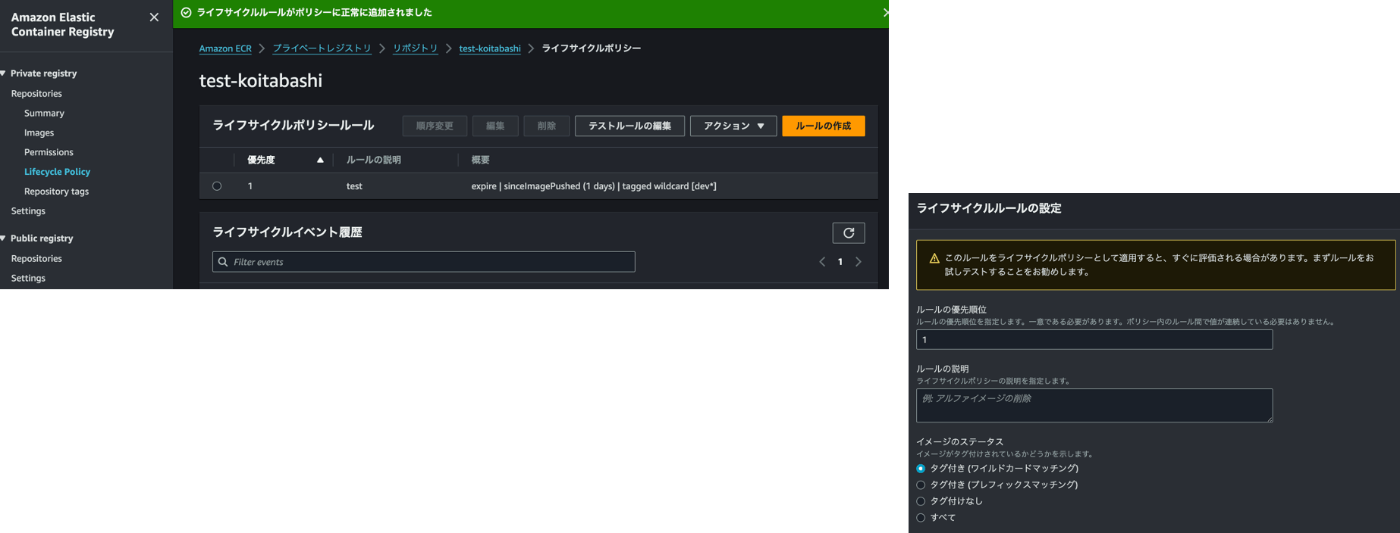
ライフサイクルポリシー
ECRのライフサイクルポリシーは使ったことある方は多いのではないでしょうか。
ライフサイクルポリシーとは、ECRの中のライフサイクルポリシーを設定しておくことで、不要になったイメージを自動的に有効期限切れ(削除)することができる機能になります。
実はここ最近もアップデートが増え、ライフサイクルポリシーのフィルターでワイルドカードが使えるようになったというものも発表されていました。
機能としては、ライフサイクルポリシーでフィルターとしてワイルドカードマッチングを使用でき、ワイルドカードを使用すると、任意の位置に 1 つ以上の特定の文字列を含むイメージタグを照合できるものとなっています。
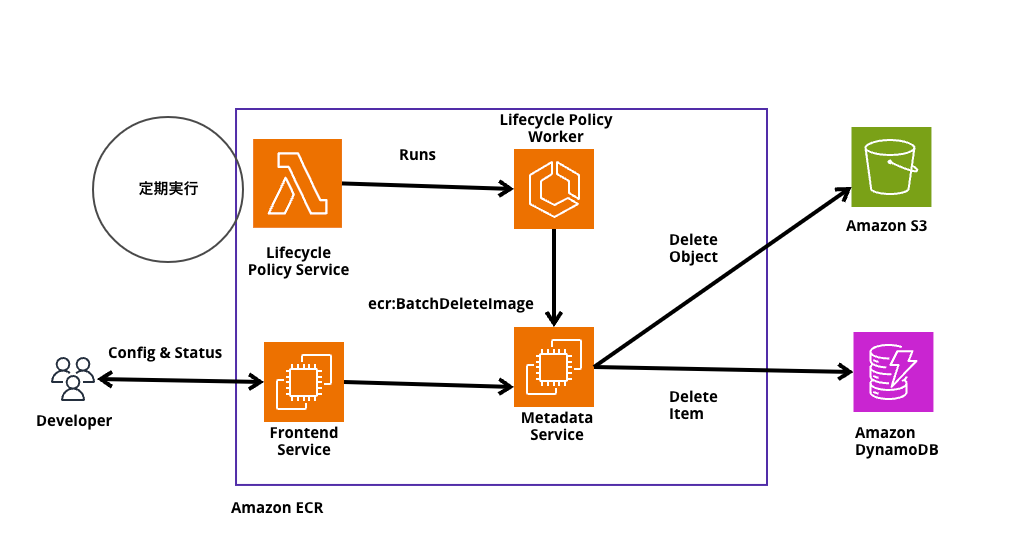
このライフサイクルポリシーの裏側は実にシンプルで下記のようになっています。
まず、ポリシーのリストを調べ、ポリシーをワーカに飛ばします。ワーカーはポリシーを取得し、リポジトリに何があるのかを確認します。
削除候補を見つけ、通常はバッチごとに5~10個のコンテナイメージをecr:BatchDeleteImage APIが呼び出されて、消すのだが、コンテナイメージの一括削除で起こる動作としては、実際には瞬時に削除されることはないようです。
実際には、S3やDynamoDBからは削除されずに削除フラグ的なマークが付与されるようです。
そしてバックグランドプロセスで定期的に動いているものがあるようで、ライフサイクルポリシーを介したものだけではなく、すべてのコンテナイメージのステータスを見て、クリーンアップする動きとなるようです。
ちなみにバックグラウンドプロセスで実行している間は料金は一切請求していないとのことでした。
まとめ: ここまでの一連の動作の中でAmazon ECRがしてきたこと
Amazon ECRのようなコンテナレジストリサービスは、一見開発者から使っている分にはシンプリに見えますが、裏側ではこれだけ多くのことをDockerクライアントとAmazon ECR側では行なっていることがお分かりいただけたのではないでしょうか。
今回、現地でセッションを聞く中で Level400と聞いていたので、かなり身構えていたのですが、まさかのちゃんとレベル400だなという感じで納得感もありました。
引用元資料
Discussion