Apache Kafka 分散メッセージングシステムの構築と活用
第1章
Apache Kafka とは
複数台のサーバーで大量のデータを処理する分散メッセージングシステム。大量のデータを「高スループット」かつ「リアルタイム」に扱う。
何ができるのか
- スケールアウト構成により扱うデータ量に応じてシステムをスケールできる。
- 受け取ったデータをディスクに永続化し、任意のタイミングで読み出せる。
- わかりやすいConnectAPIで外部システムから容易に接続できる。(ProducerAPI, ConsumerAPI)
- メッセージの送達保証ができ、データロストの心配がない。
Kafkaが生まれた背景
LinkedInがWebサイトで生成されるログの処理やアクティビティのトラッキングを目的に開発した。実現したかったことが4つ。
- 高いスループットでリアルタイムに処理したい。
- 任意のタイミングでデータを読み出したい。
- リアルタイムに処理もしたいし、一定時間ごとにバッチ処理もしたい。
- 各種プロダクトやシステムとの接続を容易にしたい。
- メッセージをロストしたくない。
Kafkaのメッセージングモデル
- Producer: メッセージの送信元。
- Broker: メッセージの収集・配信役。Brokerに送られてきたメッセージはディスクに永続化する。
- Consumer: メッセージの配信先。
- Topic: カテゴリみたいなやつ。
- Consumer Group: Consumerをスケールアウトするためのまとまり。複数のConsumerが同一のトピックから分散しながらメッセージを読み出すことでスケーラビリティを実現している。
送達保証
- At Most Once: 1回は送達を試みる。(重複しないがロストの可能性あり)
- At Least Once: 少なくとも1回は送達する。(ロストしないが重複の可能性あり)
- Exactly Once: 1回だけ送達する。(重複もロストもしないが、性能を出し難い)
Kafkaは当初 At Lieast Once を実現するのみだったが、のちにトランザクションの概念を導入して Exactly Once レベルの送達保証も実現可能になった。
第2章
Partition
Replication
In-Sync Replica
第3章
本では使っていないけど、環境構築は Docker を使った。
Dockerイメージ bitnami/kafka を使って構築
起動
$ docker-compose up -d
$ docker-compose exec kafka bash
Topic の作成
$ kafka-topics.sh --bootstrap-server localhost:9092 --create --topic first-test --partitions 1 --replication-factor 1
Created topic first-test.
Topicの確認
作ったTopicのList
$ kafka-topics.sh --bootstrap-server localhost:9092 --list
first-test
Topicの詳細
$ kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic first-test
Topic: first-test TopicId: RM4ZT6WURsSmgVcEV_Ag4Q PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: first-test Partition: 0 Leader: 1001 Replicas: 1001 Isr: 1001
ProducerとConsumer
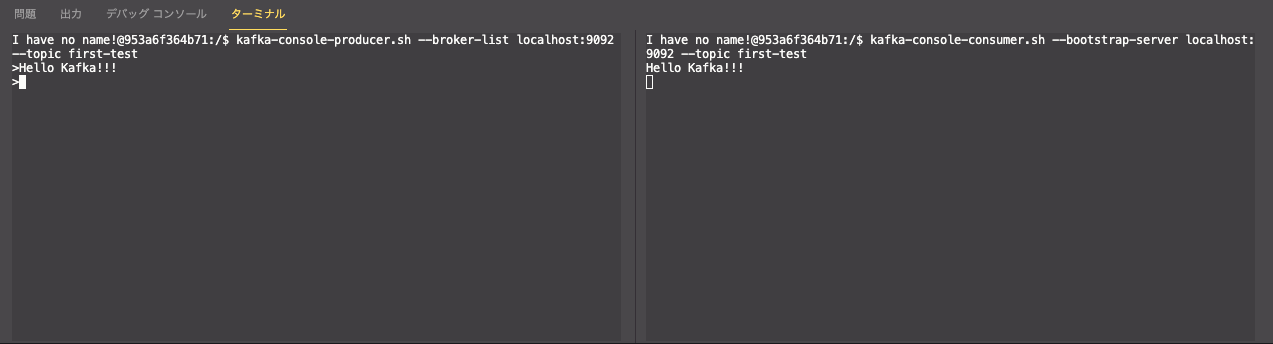
Kafka Console Producer の起動
$ kafka-console-producer.sh --broker-list localhost:9092 --topic first-test
Kafka Console Consumer の起動
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first-test
第4章
Java + Maven の環境を構築する
このコマンドで Maven プロジェクトを init した。
$ mkdir -p java/src/firstapp
$ docker run -it -v $PWD/java/src/firstapp:/firstapp --rm maven:3.5.4-jdk-8-alpine mvn archetype:generate -DarchetypeGroupId=org.apache.maven.archetypes -DarchetypeArtifactId=maven-archetype-simple -DgroupId=com.example.chapter4 -DartifactId=firstapp -Dversion=1.0-SNAPSHOT -DinteractiveMode=false
docker-compose.yml に java コンテナを追加した。
$ docker-compose up -d
Producerアプリケーションを実装してみる
アプリケーションのコード
build 実行
$ docker-compose exec java mvn package -DskipTests
別ウィンドウで Kafka Console Consumer を立ち上げる
$ docker-compose exec kafka bash
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first-app
Producer アプリケーションの実行
$ docker-compose exec java java -cp target/firstapp-1.0-SNAPSHOT-jar-with-dependencies.jar com.example.chapter4.FirstAppProducer
動いた!

Broker複数のパターンでProducerアプリケーションを動かしてみる。
アプリケーションのソースコード
docker-compose-cluster.yml
今回はBrokerを3つ立てる。
$ docker-compose -f docker-compose-cluster.yml up -d
Topicの作成
PartitionとReplicationFactorも3つ作ってみる。
$ docker-compose -f docker-compose-cluster.yml exec kafka-c-0 kafka-topics.sh --bootstrap-server kafka-c-0:9092,kafka-c-1:9092,kafka-c-2:9092 --create --topic first-app-cluster --partitions 3 --replication-factor 3
Created topic first-app-cluster.
アプリケーションのビルド
$ docker-compose -f docker-compose-cluster.yml exec java-c mvn package -DskipTests
Kafka Console Consumerを立ち上げる
新規ウインドウを3つ作り、それぞれで下記を実行(kafka-c-x の x に 0 | 1 | 2 を指定)
$ docker-compose -f docker-compose-cluster.yml exec kafka-c-x bash
$ kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic first-app-cluster
実行
$ docker-compose -f docker-compose-cluster.yml exec java-c java -cp target/firstapp-1.0-SNAPSHOT-jar-with-dependencies.jar com.example.chapter4.FirstAppClusterProducer
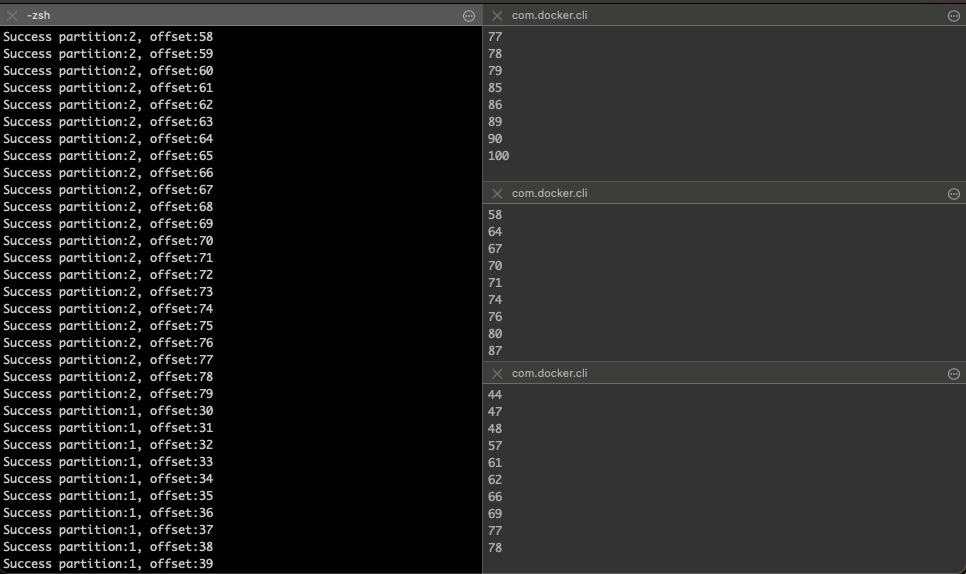
複数Consumer x 複数Partition に分散っぽいことができていそう。異なるPartitionに送信されたMessageの処理順序が、取得タイミングなどにより異なる。
Consumerアプリケーションを実装してみる
(書いとく)
Kafkaのユースケース
Kafkaの機能・特徴が重視されるシチュエーション
- リアルタイム
- 同報配信(同じメッセージを複数箇所に配信すること)
- 永続化
- 多数の連携プロダクト
- 送達保証
- 順序保証
代表的なユースケース
- データハブ
- ログ収集
- Webアクティビティ分析
- IoT
- イベントソーシング
データハブ
データハブアーキテクチャとは、複数のデータソースとなるシステムからデータを集め、それを複数のシステムに流していくアーキテクチャのこと。これによりサイロ化(システムが孤立してシステム間連携が効率よく行えない状況)を解消できる。
ログ収集
ログの欠損が許されない。複数のデータソースと繋がる必要がある。
Webアクティビティ分析
Kafka Streamsなどのストリーム処理が使える。
IoT
略
イベントソーシング
イベントソーシングとは、状態の変化のひとつひとつを「イベント(event)」として扱い、発生するイベントを逐次記録しておくもの。Kafkaはデータをすべて抽象的な「ログ」として扱い、受信したメッセージはログに逐次記録されるため、イベントソーシングの実現にフィットしている。
CQRS
CQRS(CommandQueryResponsibilitySegregation:コマンドクエリ責任分離)。データの更新処理と問い合わせ処理を分離するという考え方のアーキテクチャ
第6章 Kafka を用いたデータパイプラインの構成要素
データパイプラインとは
データの発生から収集・加工処理・保存/出力されるまでの、データが流れる経路や処理のための基盤全体のこと。
データパイプライン:Producer側のパターン
データを生成/送信するミドルウェアが
- 直接KafkaにMessageを送信するパターン。
- 対応ミドルウェア
- Apache Hadoop
- Apache Spark
- Kafka Streams
- 対応ミドルウェア
- 直接Kafkaにデータを送信せず、他のツールを介してMessageを送信するパターン。
- 例えばWebのアクセスログのパイプラインを考えると、HTTPサーバはKafkaに直接出力できないので、一度ローカルのログファイルに出力したあと、別のツールでKafkaにMessageを送信する方式が一般的。
Consumer側の構成要素
データを受信するミドルウェアが
- 直接KafkaからMessageを取得し処理するパターン。
- 対応ミドルウェア
- Apache Spark
- Apache Flink
- 対応ミドルウェア
- 他のツールを介してKafkaからMessageを取得し、処理/保存するパターン。
データパイプラインで扱うデータ
データパイプラインにおける処理の性質
- 複数のミドルウェアやアプリケーション(ex: ProducerとConsumer)によってデータが読み書きされるので、データのフォーマットの整合性が取れている必要がある。
- ストリーム処理では継続的にストリームデータが生成されるため、アプリケーションが常時起動している必要がある。
扱うデータを設計する際に、この性質を考慮する必要がある。なかでも3つのポイントがある。
- Messageのデータ型
- スキーマ構造を持つデータフォーマットの利用とスキーマエボリューション
- データの表現方法
Messageのデータ型
ProducerとConsumerでMessageの型について不整合が生じないようにしなければならない。(Kafkaはデータ型の管理を行っていないので、注意が必要)
スキーマ構造を持つデータフォーマットの利用
ストリーム処理ではJSONやApache Avroがよく利用される。
スキーマエボリューション
スキーマ定義を運用中に変更すること。ストリーム処理ではアプリケーションを気軽に停止させられないので、スキーマエボリューションの前後でスキーマの互換性を考慮する。
データの表現方法
例えば日時を表現する場合、UnixTimeなのか文字列なのか、文字列だとして YYYY/MM/DD hh:ii:ss なのか YYYY年MM月DD日 ... なのか、表現方法にルールを決める。
データハブアーキテクチャへの応用例
- ECサイトに実店舗の在庫情報を表示する
- 在庫管理 -> データハブ -> ECサイト
- 毎月の販売予測を行う
- ECサイト・POS -> データハブ -> 販売予測
- 自動発注を実現する
- 在庫管理・販売予測 -> データハブ -> 自動発注