【初級者向け】ChatGPTにSQLを作ってもらおう
はじめに
今回の記事では"SQLでのデータ抽出"に着目して"SQL初級者"のChatGPTの活用方法について掘り下げていきます。
ChatGPTをはじめとする対話型のAIの登場により、非専門家がSQLを書くハードルが大きく下がった一方、「ChatGPTに質問してSQLを書いてもらったがほしいデータが抽出できなかった」という声も聞くようになりました。
中級者以上の方であれば返ってきた結果を見て、質問を調整しながら、ほしい結果を得ることも可能だと思いますが、初級者の場合は難しいのではないかと思います。
そこで「SQLの生成においてChatGPTから精度の高い回答を得るために気を付けるべきこと」を調査しまとめることにしました。
対象読者
以下のような方を読者として想定しています:
- SQL初級者の方でChatGPTと対話しながらSQLを書いてみたいと考えている方
- ChatGPTでSQLを書く方法についてSQL初級者の方にアドバイスをしたい方
世の中にはAPIやGPTs(GPT Builder)を活用したSQL生成の事例もありますが、ここではシンプルに対話形式のChatGPTを活用してSQLを効率的に書く方法について書いていきます。
一般的なプロンプトエンジニアリングの手法に詳しいわけではないので、さらに良いやり方やアイデアがあれば、ぜひ共有していただけるとうれしいです。
ChatGPTによるSQLクエリ生成の利点と欠点
具体的なプロンプト(ChatGPTへの指示や質問)作成のポイントについて説明する前に、利用の前提として把握しておくべき「ChatGPTによるSQLクエリ生成の利点と欠点」についてまとめます。
利点
-
ハードルの低さ:ChatGPTは自然言語を理解し、それをSQLクエリ(クエリは命令文のこと)に変換できます。これにより、データベースの構造を深く理解していないユーザでも情報を簡単に取得できます
-
スピード:SQLクエリ自体を生成してくれるため自分で書く時間を大幅に短縮できます。エラー発生時の対応方法やその他不明点についても人に聞く、検索で聞くよりも速く解決できる場合がほとんどです。そして人と違っていつでも・何度でも質問できます
-
学習の効率化:ベースとして幅広い知識を有するため関数の利用やベストプラクティスを知ることができます。SQLクエリの構造についても解説してくれるため学習の助けになります
-
SQL方言への対応:異なるDBMS(データベース管理システム)のSQL方言に対応しています。「検索結果からコピペしてきたけどシステムの違いによるSQL仕様の差異で動かない」というような事態を防げます
欠点
-
コンテキストの欠如:ビジネス上の文脈やデータ構造などの情報を完璧にChatGPT側に渡すのは難しく、またChatGPTの理解力もまだ完璧ではありません
-
複雑な問題への対応:複雑なSQLクエリが必要なタスクや高いパフォーマンス(実行スピードなど)が求められるようなタスクなど専門家の知識が必要なケースは引き続き存在しています
-
意図しない結果:ユーザーの質問文が不正確だったり曖昧だったりすると期待する結果が得られないことがあります。ChatGPTは生成したSQLクエリの正しさを担保してくれないため、結果を業務に活用できるかどうかは人間が判断する必要があります
-
セキュリティ懸念:ChatGPTなど外部のツールにどのような情報を渡して良いかについては所属する組織等のルールに従う必要があります
ChatGPTを用いたSQLクエリ作成のコツ
プロンプトに盛り込むべきポイントをまとめます。
-
前提知識:以下のような情報を盛り込みます
- 使用しているデータベース管理システムの種類
- テーブル構造
- テーブル間の関係
- (可能であれば)サンプルデータ
-
制約とほしい出力結果:
- 適用したいフィルタ
- 出力結果のソート(順序づけ)の必要の有無
- 集計条件(合計・平均など)
- (必要であれば)全テーブルスキャンの回避などのパフォーマンスに関する考慮事項
SQLクエリを生成するプロンプトの具体例
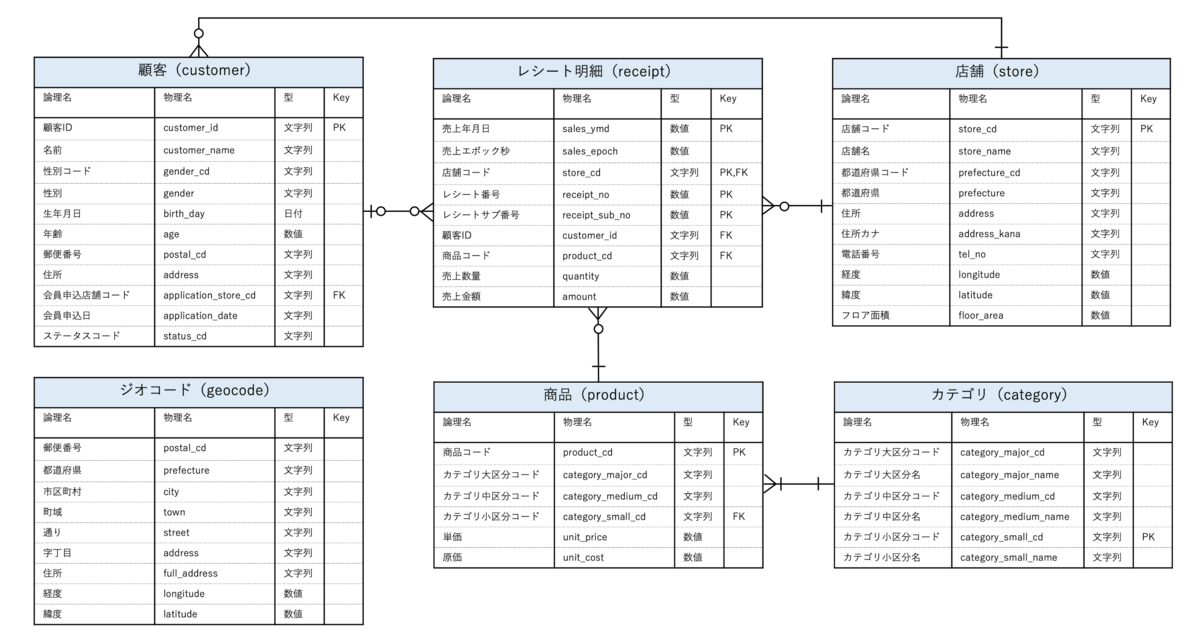
Data Scientist Society(データサイエンティスト協会)が提供する、データサイエンス100本ノック(構造化データ加工編)の演習問題をもとに実際にプロンプトを書いてみましょう。
店舗の売上情報を管理するような業務を想定しています。
ER図(テーブル構造やテーブル間の構造を示した設計書)
プロンプトの例
業務シーンを想定して「やりたいこと」から「プロンプト」に変換していきます。
演習問題というのは誰が解いても同じ答えになるようになっているので、そのまま入力しても問題ないレベルで曖昧さが排除されています。そのためデータサイエンス100本ノック(構造化データ加工編)の演習問題の問題文とプロンプトは非常に似通っています。
問題作成者の気持ちになってプロンプトを書くと良いかもしれませんね。
注意点
- 利用するデータベースはBigQueryを想定しています。
- 便宜上プロジェクト名を'sales_project'、データセット名'sales_dataset'とします。
単純な列抽出と行数指定~シンプルなselect~
やりたいこと
売上の明細についてどんなデータが入っているのか簡単に見てみたい。
プロンプト
レシート明細データ(sales_project.sales_dataset.receipt)から売上年月日(sales_ymd)、
顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、
10件表示してください。
ChatGPTが生成したSQL
SELECT
sales_ymd,
customer_id,
product_cd,
amount
FROM
`sales_project.sales_dataset.receipt`
LIMIT
10;
ポイント
そのままコピペして動く精度の高いSQLクエリを提供してもらうために、以降の例にも共通するポイントをあげていきます
- 利用するデータベースの情報を書く
- SQL方言に対応した書き方をしてもらいやすくなります
- テーブルの名前を不足なく書く
- プロジェクト名とデータセット名を書くことで実行環境によるエラーが発生しづらくなります
- 抽出したい列名について意味とテーブル上の名称の両方を書く
- ほしい出力結果を明示する
テーブルの結合などもないシンプルな条件なので経験上サンプルデータまでは必要ないかなと思います
コンテキストが欠如したプロンプトの例
先ほどの例で問題文をそのまま投入するとうまくいきません。
ChatGPT側からすると「データベースのテーブルに対してSQLクエリを発行したい」という前提がわからないためです。

参考問題
S-002: レシート明細データ(receipt)から売上年月日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上金額(amount)の順に列を指定し、10件表示せよ。
条件指定によるフィルタの適用~whereの活用~
やりたいこと
ある特定の顧客で一定規模以上の売上がいつあったのかリスト形式で確認してみたい
プロンプト
BigQueryで実行するSQLクエリを書いてください。
レシート明細データ(sales_project.sales_dataset.receipt)から売上日(sales_ymd)、
顧客ID(customer_id)、商品コード(product_cd)、売上数量(quantity)、売上金額(amount)の順に
列を指定し、以下の全ての条件を満たすデータを抽出してください。
顧客ID(customer_id)が"CS018205000001"
売上金額(amount)が1,000以上または売上数量(quantity)が5以上
ChatGPTが生成したSQL
SELECT
sales_ymd,
customer_id,
product_cd,
quantity,
amount
FROM
sales_project.sales_dataset.receipt
WHERE
customer_id = 'CS018205000001'
AND (amount >= 1000 OR quantity >= 5)
ポイント
- フィルタしたい条件があることを明記する
- 条件が複数あるときに条件同士の関係が「かつ(AND条件)」なのか「または(OR条件)」なのかがわかるように書く
参考問題
S-006: レシート明細データ(receipt)から売上日(sales_ymd)、顧客ID(customer_id)、商品コード(product_cd)、売上数量(quantity)、売上金額(amount)の順に列を指定し、以下の全ての条件を満たすデータを抽出せよ。
顧客ID(customer_id)が"CS018205000001"
売上金額(amount)が1,000以上または売上数量(quantity)が5以上
集計関数の利用~group byの活用~
やりたいこと
顧客ごとに最初に売上があった日がいつだったか知りたい。
プロンプト
BigQueryで実行するSQLクエリを書いてください。
レシート明細データ(sales_project.sales_dataset.receipt)に対し、顧客ID(customer_id)
ごとに最も古い売上年月日(sales_ymd)を集計してください。
ChatGPTが生成したSQL
SELECT
customer_id,
MIN(sales_ymd) AS earliest_sales_ymd
FROM
sales_project.sales_dataset.receipt
GROUP BY
customer_id;
ポイント
- 〇〇ごとにxxを集計するという形式で書く。xxの部分には最も大きい・新しい(MAX)、最も小さい・古い(MIN)、合計(SUM)、ユニークにカウント(COUNT DISTINCT)、平均(AVG)などを入れることができます
参考問題
S-025: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに最も古い売上年月日(sales_ymd)を求め、10件表示せよ。
テーブルのジョイン~joinの活用~
**やりたいこと**
売上の明細に店舗名の情報を追加したい
プロンプト
※プロンプト例にはサンプルデータをつけましたが、つけないバージョンでも成功しました。
※問題文はSQLがある程度わかっていることが前提となっているのでプロンプト例は少し変更しています。
BigQueryで実行するSQLクエリを書いてください。
レシート明細テーブル(rsales_project.sales_dataset.receipt)と
店舗テーブル(sales_project.sales_dataset.store)を結合し、
レシート明細データの全項目と店舗データの店舗名(store_name)を表示してください。
2つのテーブルはstore_codeをキーに結合できます。
サンプルデータを以下に示します
レシート明細テーブル(rsales_project.sales_dataset.receipt)
sales_ymd sales_epoch store_cd receipt_no receipt_sub_no customer_id product_cd quantity amount
20181103 1541203200 S14006 112 1 CS006214000001 P070305012 1 158
20181118 1542499200 S13008 1132 2 CS008415000097 P070701017 1 81
店舗テーブル(sales_project.sales_dataset.store)
store_cd store_name prefecture_cd prefecture address address_kana tel_no longitude latitude floor_area
S12014 千草台店 12 千葉県 千葉県千葉市稲毛区千草台一丁目 チバケンチバシイナゲクチグサダイイッチョウメ 043-123-4003 140.118 35.63559 1698.0
S13002 国分寺店 13 東京都 東京都国分寺市本多二丁目 トウキョウトコクブンジシホンダニチョウメ 042-123-4008 139.4802 35.70566 1735.0
ChatGPTが生成したSQL
SELECT
r.*,
s.store_name
FROM
sales_project.sales_dataset.receipt r
INNER JOIN
sales_project.sales_dataset.store s
ON
r.store_code = s.store_code;
ChatGPTによる解説も詳しくされていました。
このクエリでは、以下のポイントに注意しています:
INNER JOINを使用して両方のテーブルを結合しています。これは、両方のテーブルでマッチするstore_codeのレコードのみを取得するためです。
r.*はreceiptテーブルの全項目を選択しています。
s.store_nameはstoreテーブルからの店舗名を選択しています。
テーブルの別名(r と s)を使って、クエリをより読みやすくしています。これにより、どのテーブルのどのフィールドを参照しているかが明確になります。
テーブルの構造やデータ型に依存して、実際のクエリでは微調整が必要になる場合があります。
ポイント
- 2つのテーブルがどの列で結びつけられるのかを明記する
- 明記しなくてもChatGPTは列名から想像して正しいSQLクエリを生成することが多いですが、明記した方が精度はあがります
少しレベルがあがりますが結合条件についても意識する必要があります。
例えば店舗テーブルにすべての店舗が存在しない場合INNER JOINでは店舗テーブルに存在しないstore_cdのレシート明細が結果に表示されなくなってしまいます。
ChatGPTの解説でいうと以下の部分が該当します
INNER JOINを使用して両方のテーブルを結合しています。これは、両方のテーブルでマッチするstore_codeのレコードのみを取得するためです。
店舗テーブルの中身に関わらずレシート明細テーブルの全行を取得したい場合はその旨を明記した方が良いです(もちろん「左外部結合」のようにSQLの書き方に近い形で指定してもOKです)
BigQueryで実行するSQLクエリを書いてください。
レシート明細テーブル(rsales_project.sales_dataset.receipt)と店舗テーブル>(sales_project.sales_dataset.store)を結合し、レシート明細データの全項目と店舗データの店舗名(store_name)を表示してください
2つのテーブルはstore_codeをキーに結合できます。
なお、店舗テーブルの中身に関わらずレシート明細テーブルの全行を取得してください。
参考問題
S-036: レシート明細データ(receipt)と店舗データ(store)を内部結合し、レシート明細データの全項目と店舗データの店舗名(store_name)
データベース間の違い~BigQueryとRedshiftを例に~
いままで例ですと、標準のSQLでクエリを書けるため、データベース名を明記するメリットを感じにくかったかもしれません。
そこでデータベースにより仕様が異なる内容でSQLクエリを書くケースを元にデータベース名を明記するメリットを説明します。
やりたいこと
現在の日付を取得する
プロンプト~BigQuery~
BigQueryで実行するSQLクエリを書いてください。
現在の日付を取得してください
ChatGPTが生成したSQL
SELECT CURRENT_DATE() AS today;
プロンプト~Redshift~
Amazon Redshiftで実行するSQLクエリを書いてください。
現在の日付を取得してください
ChatGPTが生成したSQL
SELECT CURRENT_DATE;
ポイント
CURRENT_DATEの後ろに()があるかないかで書き方に違いがあり、それぞれのシステムで正しい書き方をしないとエラーになります。
ただし利用するデータベースのシステムを指定しても、ChatGPTの学習が情報が古いなど様々な理由んいより正しい結果が返ってくることは保証できません!過信しないようにしてください
BigQueryのドキュメントを確認し上記の差異は正しいことを確認しました
おわりに
繰り返しになりますが、ChatGPTはSQLクエリの正しさは保証してくれません!そのことを肝を銘じた上でChatGPTでの効率的で快適なSQLクエリ作成にトライしてみてください。
生成AIをめぐる技術革新は日々続いており、ChatGPTと対話しながらSQLクエリを書くという期間もあっという間に終わってしまうかもしれません。
それでも今日明日の生産性向上のお役に立てればうれしいです!
Discussion