データエンジニアリングの基礎を読んで個人的に気になった概念や用語をまとめる
はじめに
2024年03月に「データエンジニアリングの基礎」について、個人的にメモ書きしておきたい概念や用語について、参考文献を元にざっくりまとめておきたいと思います。この書籍自体は、データエンジニアとして働く上での基礎的な概念が網羅的にまとめられていたので、全てのデータエンジニアにおすすめの一冊だと思います。
書籍情報
データエンジニアリングの基礎
―データプロジェクトで失敗しないために
Joe Reis、Matt Housley 著、中田 秀基 訳
オライリー・ジャパン社のサイトから引用した本書の概要です。目次についても上記ページから確認できます。
データエンジニアリングとは、組織内外で日々生成されるデータを蓄積し分析するためのデータシステムを構築し維持管理することであり、急速に注目を集めている分野です。近年ではデータエンジニアリングを支えるツールやクラウドサービスが成熟し、組織へのデータ利活用の導入は容易になりましたが、明確な指針のないままデータシステムの構築を進めると費用と時間を無駄に費やすことになります。本書は「データエンジニアリングライフサイクル」を軸にデータシステムの要件を整理することで、組織の「データ成熟度」に応じたデータシステム構築の指針を与えます。またデータエンジニアの立ち位置を明確にし、組織内でデータエンジニアが果たすべき役割を示します。
書籍の紹介
これより先は書籍の内容紹介ではなく、書籍を通じて個人的に理解しておきたい概念や用語について改めて調べて残しておく意図になります。書籍の紹介は以下の記事が分かりやすくまとまっていたのでそちらをご確認いただければと思います。
そもそもデータエンジニアリングとは?

(引用:Chapter 2. The Data Engineering Lifecycle)
統一された見解があるわけではないですが、本書では以下のように定義されていました。
データエンジニアリングとは、生データを取り込み、下流の分析や機械学習などで利用しやすい高品質で一貫性のある情報を生成するシステムとプロセスの開発、実装、維持管理を意味する。
- データエンジニア:データエンジニアリングライフサイクルを管理するエンジニア。
- データエンジニアリングライフサイクル: データエンジニアリングライフサイクルはソースシステムからのデータ取得に始まり、分析や機械学習などへのデータ提供に終わる、一連のライフサイクルのことである。ライフサイクル全体にわたる重要な観点としてUndercurrents(底流)がある。
Serving(提供)
Servingはデータを提供先へ提供することです。
- リバース ETL: データエンジニアリングライフサイクルで処理されたデータをソースシステムにフィードバックするプロセスです。
- リバースETLの具体例として、マーケティングアナリストがDWHのデータを使ってMicrosoft Excelで入札額を計算し、その入札額をGoogle Adsにアップロードすることが挙げられます。このプロセスは以前は手動で行われていましたが、現在はHightouchやCensusといったベンダーがリバースETLを実現するプロダクトを提供しています。
- SaaSや外部プラットフォームへの依存が高まるにつれて、リバースETLの重要性も増しています。例えば、企業はデータウェアハウスから顧客データプラットフォームやCRMシステムへ特定のメトリクスを送ることがあります。また、Google Adsのような広告プラットフォームでも利用されています。リバースETLはデータエンジニアリングとMLエンジニアリングの分野で今後ますます見かけるようになるでしょう。
参考文献
データエンジニアリングにおける主要な底流
ここではDataOpsのみ記載します。
- DataOps:
- アジャイル手法のベストプラクティスである、DevOpsと統計的プロセス制御をデータに適用することです。DataOpsは技術的なプラクティス、ワークフロー、文化的な慣習、アーキテクチャのパターンの集合であり、以下を可能にします。
- 高速にイノベーションと実験を繰り返すことで、より高速に顧客に洞察を提供
- 非常に高いデータ品質と、非常に低いエラー率
- 人々、テクノロジ、環境の複雑な組み合わせによるコラボレーション
- 結果の、明確な測定、監視、透明性
- DataOpsには自動化、監視と観測、インシデント対応の3つの技術的な要素があります。
- 自動化
- 自動化: 自動化により、DataOpsプロセスの信頼性と一貫性が向上し、データエンジニアが迅速に新しい機能をデプロイしたり、既存のワークフローを改善できるようになります。自動化には、DevOpsのフレームワークやワークフロー(変更管理、CI/CD、コードによる構成管理など)を用います。
- 初期段階の自動化: DataOpsの成熟度が低い組織では、cronジョブでデータ変換をスケジュールしますが、複雑なパイプラインではこれが問題を引き起こすことがあります。ジョブの失敗や遅延、古いデータの生成が問題となります。オーケストレーションフレームワークの導入成熟度が上がると、AirflowやDagsterなどのオーケストレーションフレームワークを採用することで、ジョブの依存関係のチェックやデータ準備が整った時点でのジョブ開始が可能になり、効率が向上します。
- 自動デプロイの重要性: さらに成熟すると、DAGの手動デプロイを禁止し、自動デプロイを導入します。これにより、DAGがテストされ、適切に動作するか監視されます。また、Python依存ライブラリのデプロイも検証後に行うことで、信頼性が向上します。
- 変化を受け入れる姿勢: DataOpsでは、目的に即した変化を受け入れ、自動化を進めることで運用を改善し続けることが重要です。次世代のオーケストレーションフレームワークやメタデータ機能の向上を追求し、常にエンジニアの負荷を減少させつつ、ビジネスに提供する価値を増大させます。これにより、DataOpsの自動化は、データエンジニアチームの効率と満足度を大いに高めます。
- 観測と監視
- 観測と監視の重要性:
- データとデータ生成システムを観測・監視しないとデータの問題に気づけません。
- 観測と監視、ロギング、アラート、トレースはデータエンジニアリングライフサイクルの問題を事前に把握するために必要不可欠です。
- SPC(Statistical Process Control:統計的工程管理)を導入し、監視されたイベントの異常や対応が必要なインシデントを把握します。
- DODDメソッド:
- PetrellaのDODDメソッド(Data Observability Driven Development)は、データの可観測性を考える上で優れたフレームワークを提供します。
- DODDは、TDD(test-driven development:テスト駆動開発)に似ています。データチェーンに関わるすべての人が、データとデータアプリケーションを見えるようにし、データバリューチェーンのすべてのステップでデータの変化を知ることができるようにすることが目的です。データの問題を特定し、解決、防止するためにデータエンジニアリングライフサイクルにおいてデータの同期された観測可能性、データに対するコンテキストの観測可能性、継続的なCI/CDによる検証を重要な原則としています。
- 観測と監視の重要性:
- インシデント対応
- 高度なデータチームは、DataOpsを使って迅速に新しいデータプロダクトを出荷しますが、ミスは避けられません。以下のような問題が発生する可能性があります。
- システムのダウン
- 新しいデータモデルが下流のレポートを破壊
- 古くなったMLモデルが間違った予測を出力
- データエンジニアリングライフサイクルを阻害する問題は無数に存在します。「インシデント対応」は、これらの問題を自動化と可観測性を利用して特定し、迅速かつ信頼性高く解決することです。
- インシデント対応の要点:
- オープンなコミュニケーション:
- テクノロジとツールだけでなく、組織全体でのオープンで非難しないコミュニケーションが重要。
- AWSのCTO Werner Vogelsの言葉「Everything fails, all the time (全ての物はいつか必ず壊れる)」を肝に銘じ、迅速かつ効率的に対応する準備が必要。
- 問題の事前発見:
- データエンジニアは、ビジネスに影響を与える前に問題を見つける必要があります。
- 利害関係者やエンドユーザが問題を見つけたときには、すでに対応が始まっていることが理想。
- 信頼関係の構築:
- エンドユーザから信頼されるためには、問題に迅速に対応する姿勢が重要。
- 信頼関係の構築には時間がかかりますが、失うのは一瞬です。
- オープンなコミュニケーション:
- インシデント対応は、インシデントが発生してからの対応だけでなく、発生前に問題を見つけて対応することも含まれます。
- 高度なデータチームは、DataOpsを使って迅速に新しいデータプロダクトを出荷しますが、ミスは避けられません。以下のような問題が発生する可能性があります。
- 自動化
- アジャイル手法のベストプラクティスである、DevOpsと統計的プロセス制御をデータに適用することです。DataOpsは技術的なプラクティス、ワークフロー、文化的な慣習、アーキテクチャのパターンの集合であり、以下を可能にします。
現時点では、DataOpsはまだ発展途上にあります。以下の要点にまとめられます。「The DataOps Manifest」のポイントを基に、データエンジニアはDataOpsを積極的に取り入れるべきです。
参考文献
データアーキテクチャ設計
良いアーキテクチャの原則
良いアーキテクチャの原則として以下の9つが「データエンジニアリングの基礎」で記載されていました。その中でもFinOpsについてまとめます。
- 原則1:共通コンポーネントを賢く選択する
- 原則2:障害に備える
- 原則3:スケーラビリティ設計
- 原則4:アーキテクチャはリーダーシップだ
- 原則5:常に設計し続ける
- 原則6:疎結合システムを構築する
- 原則7:可逆な決定をする
- 原則8:セキュリティを優先する
- 原則9:FinOpsを活用する
- FinOps:
- FinOpsはFinanceとDevOpsを合わせた造語です。クラウド財務管理の規律と文化的プラクティスであり、エンジニアリング、財務、テクノロジ、ビジネスの各チームが協力してデータ駆動で支出を決定し、最大のビジネス価値を引き出すことを目指す概念のことです。
- クラウド時代のコスト管理
- クラウド環境では、データシステムは従量課金制で運用されるため、必要に応じてスケールアップやスケールダウンが可能です。しかし、支出は動的であるため、予算や優先順位、効率を管理する新たな課題が生じます。
- FinOpsの実践
- データエンジニアはクラウドシステムのコスト構造を理解し、コスト効率を最大化するための方法を学ぶ必要があります。例えば、AWSスポットインスタンスの適切な組み合わせや、クエリ課金モデルから容量予約への切り替え時期を検討することです。
- 運用監視とコスト攻撃への対策
- FinOpsでは、継続的に支出を監視し、支出が急増した場合にアラートを発するシステムを設計します。また、DDoS攻撃のように、過剰なダウンロードによるコスト攻撃に対処するための対策も必要です。
- FinOpsの重要性
- FinOpsは最近正式化されたプラクティスであり、クラウドの高額請求に遭遇する前に早めに考え始めることが重要です。FinOps Foundationや関連書籍から学び、コミュニティのプロセスに参加することが推奨されます。
- FinOpsを理解し活用することで、データエンジニアリングにおけるコスト効率とビジネス価値を最大化できます。
データアーキテクチャの例と種類
- OLTP: On-Line Transaction Processing。主な目的はデータベーストランザクションを処理することです。典型的な例として、銀行口座の残高を保存するDBが挙げられます。RDBを使用してデータをテーブルに整理します。
- OLAP: Online Analytical Processing。主な目的は集約されたデータを分析することです。典型的な例として、傾向の分析、顧客行動の予測、収益性の特定などが挙げられます。OLAP データベースは、データをキューブ形式で格納します。OLAPは、さまざまな観点からビジネスデータを分析するために使用できるソフトウェアテクノロジです。AWSでいうとOLAP専用に設計されたDWHであるAmazon RedshiftやOLAP 機能を備えたRDBであるAmazon RDS、Amazon Aurora、OLAP分析に使用するAmazon Quicksightなどがあります。
- データウェアハウス(DWH)
- データウェアハウス(データの倉庫の略)は、1989年にBill Inmonによって定義されました。一言で言うと、分析しやすく検索できるように蓄積したデータベースです。経営者の意思決定を支援するための、サブジェクト指向の、統合された、不揮発性の、時系列データの集合体であり、細粒度の企業データが蓄積されます。データウェアハウス内のデータはさまざまな目的に使用することができます。その目的には、現在未知である将来の要件に備えることが含まれます。
- データウェアハウスの第二の特徴は、統合されていることです。データウェアハウスにはさまざまな面がありますが、統合されていることが最も重要です。データは複数の異なるソースからデータウェアハウスに供給されます。供給されたデータは、変換、再フォーマット、再シーケンス、要約されます。その結果としてできあがるデータウェアハウスに存在するデータは、単一の物理的な企業像を示すことになります。DWHはビジネス全体の情報要件をサポートする信頼できる唯一の情報源(single source of truth)となります。理想的には、DWHはビジネスの情報を全体的に網羅します。部門固有の情報要求に対応するため、ETLプロセスはDWHからデータを取得し、データを変換し、下流のデータマートに送り、レポートとして表示します。
- データウェアハウスの4つの重要な要素
- 統合化(integrated):各部門のデータの表記揺れや意味を統一。主要なビジネスソースシステムから取り込まれたデータはRDBと同様に高度に正規化され、DWHに統合されます。
- サブジェクト指向(subject oriented):データを目的毎に分類して、分析の軸(次元)ごとに集計して蓄積したデータである「データマート」を作成
- 恒常性(nonvolatile):変更せずに参照可能な状態で保存
- 時系列(time variant):日々生成されるデータ、その時点のデータ状態を保存
- クラウドデータウェアハウス
- 進化と変化
- オンプレミスのデータウェアハウスアーキテクチャから大きく進化。
- Amazon Redshiftの登場によりクラウドデータウェアハウス革命が始まりました。
- 柔軟性とスケーラビリティ
- 以前は大規模契約でシステムを調達していましたが、現在はオンデマンドでRedshiftクラスタを起動・削除可能です。
- コンピュートとストレージの分離(Google BigQuery, Snowflakeなど)で無限のストレージと柔軟な計算能力を提供。
- 機能とユースケース
- MPPシステム(Massively Parallel Processing)とよばれる超並列処理の機能を拡張し、従来はHadoopクラスタが必要だった多くのビッグデータのユースケースをカバー。
- ペタバイト級のデータ処理、複雑なJSONドキュメントの保存などに対応。
- 未来の展望
- データウェアハウスとデータレイクの境界が曖昧に。
- 従来のデータウェアハウスのMPPシステムが提供する機能よりもはるかに幅広い機能を備えた新しいデータプラットフォームへの進化しつつあります。
- 進化と変化
- データマート
- データマートとは、1つのサブ組織、部門、または、事業部門に特化した、分析およびレポート作成のために設計されたDWHのサブセットです。フルセットのDWHとは対照的です。
- 利点
- 特化した独自のデータマートを持つことで、アナリストやレポート開発者がデータにアクセスしやすくなります。
- ETLまたはELTパイプラインに加えて、追加の変換を行うことで性能向上。
- データの複雑なジョインや集約が必要な場合に、ジョインおよび集計されたデータをデータマートに投入し、クエリ性能を向上させます。
- データレイク
- データの構造に厳しい制限を課さず、構造化データも非構造化データも全てまとめて単純に1箇所にまとめてダンプするオブジェクトストレージです。
- データレイクハウス
- DWHには、画像、テキストなどの非構造化データの処理には向いていません。データレイクはトランザクションやデータ品質などの重要な機能がなく、データスワンプとなる課題がありました。これらの課題を解決するために生まれたのがデータレイクハウスです。データウェアハウスに見られる制御、データ管理、データ構造を取り入れながら、データをオブジェクトストレージに格納し、さまざまなクエリと変換エンジンをサポートします。不可分性、一貫性、独立性、永続性(ACID)トランザクションをサポートしており、単にデータを流し込んで更新や、削除を行わない本来のデータレイクとは大きく異なります。
- モダンデータスタック
- クラウドベースを繋ぐだけで、動作する使用の容易な既製コンポーネントを使用して、モジュール性が高くコスト効率の良いデータアーキテクチャを構築することを目的とするフレームワークとツール群です。
- Lambdaアーキテクチャ
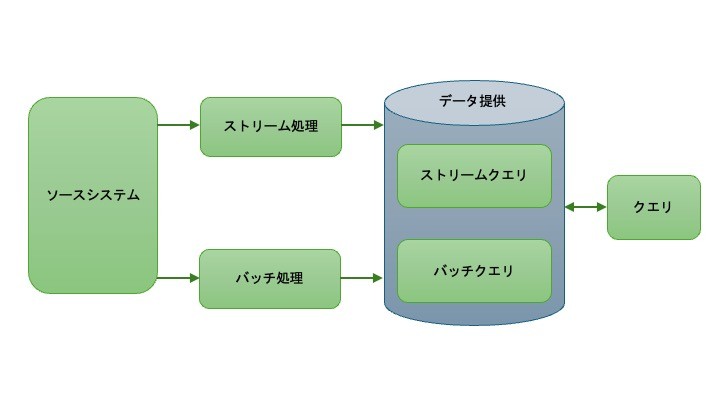
- 2010年代初期〜中期にKafkaやApache Stormなどのストリーミング技術が登場し、ユーザーの集計やランキング、製品の推奨などの分析やモデリングを実行できるようになりました。そのため、バッチデータとストリーミングデータを単一のアーキテクチャで扱う必要性が生じました。Lambdaアーキテクチャは、この問題に対しての一つの対応策でした。バッチ、ストリーミング、データ提供の3つのレイヤーで構成されます。
- ソースシステムは理想的には不変データのみを追記し、バッチとストリームのふたつの受信側にデータを送ります。
- ストリーム処理: 低レイテンシでデータ提供します。直近数秒、数分、数十分のイベントの集計結果を提供することになります。
- バッチ処理: データの集約ビューを計算・作成します。
- データ提供レイヤ: 2つのレイヤの結果を集約して統合されたビューを提供。
- 商品売上での処理の例:
- 2023-05-16の午前3時にバッチ処理実行:
- 2023-05-15のデータを処理
- 結果:総売上 5500円、商品別(A001: 2000円, B002: 1500円, C003: 2000円)
- 2023-05-16の午前11時時点でのストリーム処理:
- 2023-05-16のデータをリアルタイムで処理
- 結果:総売上 2500円、商品別(A001: 1000円, B002: 1500円)
- ユーザーが午前11時にクエリを実行:
- システムはバッチ処理の結果とストリーム処理の結果を組み合わせる
- 最終結果:
- 総売上: 8000円 (5500円 + 2500円)
- 商品別: A001: 3000円, B002: 3000円, C003: 2000円
- データの整合性:
- バッチ処理結果: 2023-05-15 23:59:59まで確定
- ストリーム処理結果: 2023-05-16 00:00:00以降の暫定値
- システムは、この2つの結果を適切に組み合わせて最新の全体像を提供
- 2023-05-16の午前3時にバッチ処理実行:
- バッチ処理とストリーム処理の複数システム管理が困難とういう課題があります。
- 2010年代初期〜中期にKafkaやApache Stormなどのストリーミング技術が登場し、ユーザーの集計やランキング、製品の推奨などの分析やモデリングを実行できるようになりました。そのため、バッチデータとストリーミングデータを単一のアーキテクチャで扱う必要性が生じました。Lambdaアーキテクチャは、この問題に対しての一つの対応策でした。バッチ、ストリーミング、データ提供の3つのレイヤーで構成されます。
- Kappaアーキテクチャ
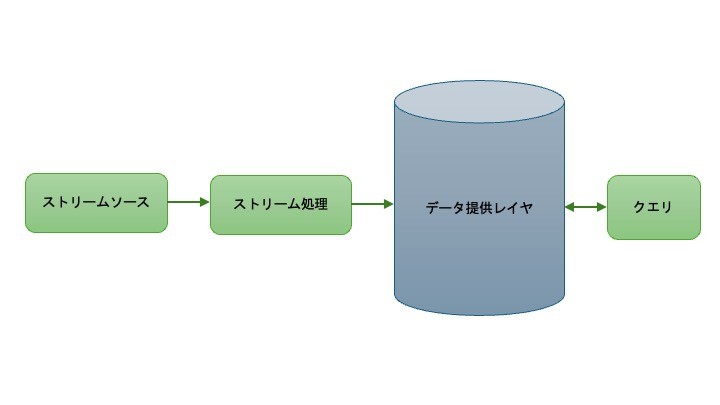
- Lambdaアーキテクチャの課題に対する解決策として提案されました。すべてのデータ処理(取り込み、ストレージ、データ提供)にストリーム処理を使用し、真のイベントベースのアーキテクチャを実現します。
- 特徴:
- リアルタイム処理とバッチ処理を同じデータに適用可能
- ライブイベントストリームは直接読み込み
- バッチ処理は大きなデータチャンクを分割して実行
- バッチ処理との比較:
- 一部のストリーミングシステムは大量データに対応可能だが複雑で高価
- 膨大な過去のデータセットに対しては、バッチストレージとバッチ処理の方が効率的でコスト効率が高い
- Dataflowモデル
- Googleが開発、Apache Beamフレームワークで実装されています。すべてのデータをイベントとして捉え、イベント列上の様々なウィンドウで集計します。Apache Beam はバッチ処理、ストリーミング処理の両方を定義することができるオープンソースのプログラミングモデル で、大規模なデータ分散処理パイプラインを単純化して定義することができます。リアルタイム処理とバッチ処理に同じコードを使用することができます。
- データメッシュ
- 企業の規模が大きければ大きいほど、データの複雑性は増し、中央集権的に管理するのが難しくなるので、データをDWHのように中央集権的に管理するのではなく、分散化して管理しようというアプローチのことです。データメッシュには4つの規律があります。
- ドメイン別オーナーシップとデータ分散アーキテクチャ
- 各事業ドメインでデータに対して責任を持ち、保有、管理します。
- データのプロダクト化
- 他ドメインに提供するデータは、まるで自社の実際のプロダクト、製品であるかのように取り扱います。
- セルフサービス型データプラットフォーム
- 各ドメインの人たちは、その全てがITの専門家ではないため、データプロダクトの特性を自ら担保するためには、使いやすいツールやデータプラットフォームを使用します。
- 横断的なデータガバナンス
- ドメイン横断で均質な特性を持つデータプロダクトを整備・共有しながら継続的に運用していくために、全ドメイン共通のポリシーと標準化ルールの定義、組織と人材の育成と確立、プロセスの設計と実装、ITプラットフォームの整備、といった横断的なデータガバナンスの実現が必要です。
今回は記載しませんが、その他にも以下アーキテクチャがあります。
- データファブリック
- データハブ
- スケールドアーキテクチャ
- メタデータファーストアーキテクチャ
- イベント稼働アーキテクチャ
- ライブデータスタック
参考文献
データモデリング
- データモデリング
- データモデルは、データと現実世界との関係性を表すものです。組織のプロセス、定義、ワークフロー、ロジックを最適に反映するように、データを構造化し、標準化します。優れたデータモデルは、組織内でのコミュニケーションをと作業の自然の流れを捉える。対照的にデータモデルが貧弱であったり存在しなかったりすると、行き当たりばったりで支離滅裂なことになります。データモデリングは、データ分析用途のDBであるDWH(データウェアハウス)を分析しやすいテーブル構造や構成にする手法です。基幹DBは、正規化されておりテーブルの関連が複雑で、アナリストが分析しやすい形式ではないので、基幹DBのデータを分析対象の目的別に再編し、データを分かり易く、分析しやすいテーブル構造や構成にします。
- 概念データモデル、論理データモデル、物理データモデル
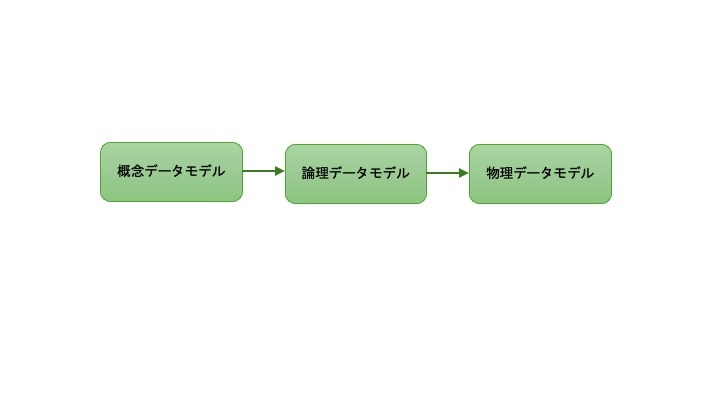
- データをモデリングする際は抽象的な概念から具体的な実装へと移行していきます。3つの主要なデータモデルを考えます。
- 概念データモデル
- ビジネスロジックとルールを表します。スキーマ、テーブル、フィールド(名前と型)など、システムのデータを記述します。概念モデルを作成する際には、エンティティーリレーション図(ER図)で可視化することが有効です。ER図はデータ内のさまざまなエンティティ(注文、顧客、製品など)の間の関係を可視化するための標準的なツールです。例えば、顧客ID、顧客名、顧客住所、顧客注文の間の接続関係を表現する。エンティティの関係を可視化することは、首尾一貫した概念データモデルを設計するために重要です。
- 論理データモデル
- 概念モデルの実装を、より詳細に定義します。例えば、顧客ID、顧容名、顧容の住所のデータ型に関する情報を追加します。さらに、主キーと外部キーのマッピングを行います。
- 物理データモデル
- 論理モデルをデータベースシステムに実装する方法を定義します。具体的なデータベース、スキーマ、テープルを設定の詳細も含めて論理モデルに追加します。
- データモデリングにおける「粒度」
- データが格納されクエリされる単位を意味します。粒度は、顧客ID、注文ID、製品IDなどテーブルの主キーのレベルで表されます。
- 例)
- 依頼:顧客からの注文を日ごとにまとめたレポートが欲しい。具体的には、注文した顧客のリスト、顧客がその日に注文した数、注文金額の合計を示すレポート。
- 課題:このレポートの粒度は粗く、注文ごとの価格や各注文の品目に関する詳細は含まれていません。レポートに必要なデータのみを持つレポートテーブルを作成した場合、より細かいデータ集計が必要なレポートの要求が来た際に最初からやり直しになります。
- 考え方:注文、品目、品目コスト、品目IDなど顧客の注文に関する詳細なデータを含むテーブルを作成する必要があります。
- 大きな粒度に集約されてしまったデータを復元することは不可能であるので、可能な限り最小の粒度でデータをモデリングするべきです。
- 正規化
- 正規化(normalization): DB内のテーブルと列の関係を厳密に管理することを強制するモデリング手法。DRY(Don’t repeat your self)原則をDB内のデータに適用することにあたります。
- RDBのパイオニアであるEdgart Coddによって導入されました。
- 関係の集合(DB内のテーブル設計)を、望ましくない挿入、更新、削除の依存関係から解放します。新しい種類のデータを導入する際に関係の集合を再構築する必要性を減らすことで、アプリケーションプログラムの寿命を延ばします。関係モデルをユーザにとってより理解しやすいものにします。
- 非正規形
- 正規化なし。ネストや冗長なデータも可。
- 第1正規形(1NF)
- 各カラムは一意であり、単一の値を持つ。テーブルは一意な主キーを持ちます。
- 主キー(複合キー):テーブルの行を一意に決定する単一のフィールド、または複数フィールドの組みのことです。
- 第2正規形(2NF)
- 第1正規形の要件に加え、部分従属性を持たない。完全従属性であること。
- 部分従属性(partial dependency):一意な複合キーのカラムの一部によって完全に決定される非キーカラムが存在すること。
- 完全従属性 (Full Dependency): 非キー属性が複合キー全体に依存している状態。
- 第3正規形(3NF)
- 第2正規形の要件に加え、各テーブルはその主キーに関連するフィールドのみを含み、推移的従属性を持たない。
- 推移的従属性(transitive dependency):非キーフィールドが別の非キーフィールドに依存する場合に発生する。
- 例1:第1正規形 (1NF) から第2正規形 (2NF) へ
- テーブル: 学生コース登録
学生ID(Ckey) コースID(Ckey) 学生名 コース名 教授名 1 101 太郎 数学 佐藤 2 102 花子 英語 鈴木 1 102 太郎 英語 鈴木 3 101 次郎 数学 佐藤 - 主キーは学生IDとコースIDの複合キー(Composite Key)です。
- このテーブルは第1正規形 (1NF) ですが、部分従属性が存在します。
- 学生名 は 学生ID に依存しています。
- コース名 と 教授名 は コースID に依存しています。
- これを第2正規形にするために、部分従属性を解消します。
- 第2正規形 (2NF) への分割
- 学生テーブル
学生ID(Pkey) 学生名 1 太郎 2 花子 3 次郎 - コーステーブル
コースID(Pkey) コース名 教授名 101 数学 佐藤 102 英語 鈴木 - 登録テーブル
学生ID(Ckey) コースID(Ckey) 1 101 2 102 1 102 3 101 - このように分割することで、すべての非キー属性が複合キー全体に依存するようになります。つまり、部分従属性が解消され、完全従属性が実現されました。
- 以前:学生名(例:太郎)が複数回出現
- 現在:学生情報、コース情報がそれぞれ1回だけ記録される
- 例2:第2正規形 (2NF) から第3正規形 (3NF) へ
- テーブル: 従業員
従業員ID(Pkey) 部署ID 従業員名 部署名 部長名 1 10 佐藤 開発 田中 2 20 鈴木 営業 中村 3 10 高橋 開発 田中 4 30 田中 人事 佐々木 - このテーブルは第2正規形 (2NF) ですが、推移的従属性が存在します。
- 部署名 と 部長名 は 部署ID に依存していますが、部署名 が 従業員ID に直接依存していないため、推移的従属性が発生しています。
- これを第3正規形にするために、推移的従属性を解消します。
- 第3正規形 (3NF) への分割
- 従業員テーブル
従業員ID(Pkey) 従業員名 部署ID 1 佐藤 10 2 鈴木 20 3 高橋 10 4 田中 30 - 部署テーブル
部署ID(Pkey) 部署名 部長名 10 開発 田中 20 営業 中村 30 人事 佐々木 - このように分割することで、推移的従属性が解消されます。すべての非キー属性が直接主キーに依存するようになり、第3正規形を満たします。
- 以前:部長が変更された場合、複数の行を更新する必要がありました。
- 現在:部署テーブルの1行だけを更新すれば済みます。
- テーブル: 従業員
- バッチアナリティクスデータのモデリング手法
-
DataLake、DWHのデータモデリング。遭遇する可能性の高い主要なアプローチは、Inmon、Kimball、データボルトの3つでです。
-
Inmon
- DWHの生みの親であるBill Inmonが考案したデータモデリングです。データアーキテクチャの方でも記載しましたが、正規化したデータは、さまざまな更新が生じても一貫性を保つことができますが、複雑な参照関係と多数のテーブルができてしまい、アナリストが理解し活用するのが困難となります。
-
Kimball
- Ralph Kinballによって考案されたデータモデリングのアプローチは、正規化をあまり重視せず、非正規化を受け入れます。Inmonがビジネス全体のデータをデータウェアハウスに統合し、データマートを介して部門固有の分析を提供するのに対し、KinballモデルはDataMartをビジネス要件に基づいて最初に設計するボトムアップ型であり、データウェアハウス自体で部門やビジネスの分析をモデリングし、提供することを推奨します。非正規化されているため、アナリストは複雑なテーブルを結合せずに活用できます。Inmon よりも迅速な反復とモデリングが可能になるが、その一方でデータ統合が緩くなりデータの冗長性や重複が発生する可能性があります。
- Kinballのアプローチでは、データはファクトとディメンジョンという2種類のテーブルでモデリングされます。ファクトテーブルは数値のテーブルであり、ディメンジョンテーブルはファクトを参照する定性的なデータです。デイメンジョンテーブルは、スタースキーマと呼ばれる関係で、単一のファクトテーブルを取り囲んでいます。スタースキーマでDWHを構築します。
- ファクトテーブル:
-
ファクトに関する量的でイベントに関連するデータが格納されています。
-
分析したい値の列とその周りのディメンションテーブルを参照する外部キーの列
-
イベントに関連しているので、データは変更されず、追記のみ。
-
通常は列数は多くなく、イベントを表す行数は多い。
-
可能な限り細粒度
-
例)
-
要望:顧客からの注文ごと、日付ごとの総売上高を表示して欲しい
-
ファクトテーブル:販売の注文ID、顧客、日付、売上高
OrderID CustomerKey DateKey GrossSalesAmt 100 5 20220301 100.00 101 7 20220301 75.00 102 7 20220301 50.00
-
- ディメンションテーブル
-
ファクトテーブルに格納されたイベントに対して、参照データ、属性、関係コンテキストを提供します。非正規化されているのでデータが重複する可能性があります。
-
日付ディメンジョンテーブル
- ファクトテーブルのDateKeyと紐づく
- 日付テーブルで、2022年の第1四半期の総売上は?や火曜日に買い物する客は水曜日より何人多い?などの質問に簡単に答えることができます。
DateKey Date-ISO Year Quarter Month Day-of-week 20220301 2022-03-01 2022 1 3 Tuesday 20220302 2022-03-02 2022 1 3 Wednesday 20220303 2022-03-03 2022 1 3 Thursday -
顧客ディメンジョンテーブル
- ファクトテーブルのCustomerKeyと紐づく
CustomerKey FirstName LastName ZipCode EFF_StartDate EFF_EndDate 5 Joe Reis 84108 2019-01-04 9999-01-01 7 Matt Housley 84101 2020-05-04 2021-09-19 7 Matt Housley 84123 2021-09-19 9999-01-01 11 Lana Belle 90210 2022-02-04 9999-01-01 -
ディメンジョンの変更管理
- SCD(Slowy changing dimension): ゆっくりと変化するディメンジョン。最大7つのレベルがありますが、ここでは3つ記載します。
- タイプ1:既存のディメンジョンレコードを上書き。簡単ですが、過去のレコードにアクセスできません。
- タイプ2:ディメンジョンレコードを完全な履歴を保持します。レコードが変更されると特定のレコードに変更フラグがつけられ、属性の現在のステータスを反映した新しいディメンジョンレコードが作成されます。
- タイプ3:新しい行を作成せずに、元の行に新しいフィールドを作成します。
- 例)
- タイプ3更新前
CustomerKey FirstName LastName ZipCode 7 Matt Housley 84101 - タイプ3更新後
CustomerKey FirstName LastName Original ZipCode Current ZipCode CurrentDate 7 Matt Housley 84101 84123 2021-09-19
-
ほとんどのDWHのデフォルト動作はタイプ1で、実際に最もよく使われるのは、タイプ2。
-
- スタースキーマ
- ビジネスのデータモデルを表す。ファクトテーブルを必要なディメンジョンデーブルで囲んだものです。他のデータモデルよりもジョインが少なく、クエリ性能が向上します。
- ビジネスロジックのファクトと属性をとらえ、関連する重要な質問に答えるのに十分な柔軟性を持たなければいけません。
- 1つのスタースキーマに1つのファクトテーブルしか持てないため、ビジネスのさまざまなファクトに対応して、複数のスタースキーマを用いる場合もあります。
- 適合ディメンジョン:複数のスタースキーマから利用され、複数のスタースキーマとフィールドを共有するディメンジョンのことです。これを利用すると、複数のスタースキーマの複数のファクトテーブルをジョインできます。
- このデータモデリングの課題信頼できる唯一の情報源(Single Source Of Truth)は、失われており、企業全体の整合性と一貫性を確保できないことがります。
-
Data Vault
- Dan Linstedtによって作成されたデータモデリング。
- データソースシステムから一握りの挿入のみを許す専用テーブルにデータを直接ロードする。
- データボルトのデーブルは、ハブ、リンク、サテライトの3種類で構成されています。
- ハブ:
- ビジネスキーを格納するtable。データボルトの中心的なエンティティ。ハブは挿入専用で、ハブ内でデータが変更されることはない。一度ハブに読み込まれたデータは永久に保存される。
- ビジネスキー:ECの例で言えば、顧客IDや注文IDなど。特定可能なビジネス要素。
- ハブには以下の標準フィールドが含まれる。
- ハッシュキー:システム間のデータジョインに使用される主キー。ハッシュ関数(MD5など)で算出するフィールド。
- ロード日:データがハブにロードされた日付。
- レコードソース:個々のレコードの取得元。
- ビジネスキー:一意のレコードを識別するキー。
- 例)
- 商品ハブ
ProductHashKey LoadDate RecordSource ProductID 3033ffs… 2020-01-02 ERP 1 sfsefs23243.. 2021-03-09 ERP 2 24qrf32qf… 2021-03-09 ERP 3 - 注文ハブ
OrderHashKey LoadDate RecordSource OrderID dgat322wg 2022-03-01 Website 100 32243wg4r 2022-03-01 Website 101 5323fef 2022-03-01 Website 102
- 商品ハブ
- リンク:
- ハブ間のビジネスキーの関係を表す。
- 例)
- 注文と商品を接続するリンクテーブル
OrderProductHashKey LoadDate RecordSource ProductHashKey OrderHashKey fff64ecd… 2022-03-01 Website 3033ffs… dgat322wg fff64ecd… 2022-03-01 Website sfsefs23243.. dgat322wg fetgf3443 2022-03-01 Website 24qrf32qf… 32243wg4r fwefwe23f 2022-03-01 Website 3033ffs… 5323fef
- 注文と商品を接続するリンクテーブル
- サテライト:
- ハブに意味とコンテキストを与える記述属性。
- サテライトの必須フィールドは親ハブのビジネスキーで構成される主キーとロード日。
- 例)
- 商品のサテライトテーブル
ProductHashKey LoadDate RecordSource ProductName Price fff64ecd… 2021-01-02 ERP Thingamajig 50 fetgf3443 2021-03-09 ERP Whatchamacallit 25 fwefwe23f 2021-03-09 ERP Whozeewhatzit 75
- 商品のサテライトテーブル
- 注文と商品を表したデータボルトの例
-
ワイドな非正規テーブル
- InmonとKimballのアプローチはDWHが高価で、オンプレミスにあり、コンピュートとストレージが密結合している時代に開発されたもの。
- 現在はストレージが非常に安価になったことにより、より緩やかなアプローチが一般的になりつつあります。
- ワイドテーブル:高度に非正規化され多くのフィールドを持つ非常に幅の広いテーブルで、通常はカラム型DBで作成される。フィールドは単一の場合もあれば、ネストされたデータを含む場合もあります。
- より厳密にモデリングをしないことでジョインしないと得られないデータがワイドテーブルには初めから格納されているので、多くのジョインを必要とする正規化されたテーブルよりも高速に実行できる場合が多い。
- RDBでは100カラム以下が一般的だが、ワイドテーブルでは、数千カラムで保持することもあります。カラム型DBではNULLとなるエントリは事実上全く消費しません。
- データをブレンドする(適当に混ぜる)とアナリティクスからビジネスロジックが失われると言う批判もあります。
- ネストされたデータに対する更新性能で、これは非常に低くなる可能性があります。
- 非正規化されたデータの例
OrderID OrderItems CustomerID CustomerName OrderDate 100 [“sku”: 1,“price”: 50,“antity”: 1,“Thingamajig”}“sku” : 2,“price”: 25,“quantity”: 2,“name:”“Whatchamacallit”}] 5 Joe Reis 2022-03-01
-
- ストリームデータモデリング
- 現状は、流動的なスキーマ変更、動きの速いデータ、セルフサービスといった要請と、ビジネスロジックの要請をバランスさせるデータモデリング手法は確立していません。
- ストリームデータシステムの多くの専門家は、従来のバッチ指向データモデリングは当てはまらないと言われています。
- ソースデータシステムの変化を前提に、スキーマを柔軟にしておくことが重要です。
参考文献
そのほかに気になった用語
本書には直接的な記載はなかったですが、気になっている用語をせっかくなのでまとめておきます。
-
ストアドプロシージャ
- データベース内に保存され、名前を付けて呼び出せるSQLステートメントの集まりです。複雑な処理をカプセル化し、再利用性を高め、パフォーマンスを向上させることができます。セキュリティ面でも利点があり、データベース操作を集中管理できます。
-
縦持ち横持ち
- データベースの設計において、データを格納する方法を指します。横持ちは各属性を列として持つ通常のテーブル構造で、縦持ちは属性と値を行として持つ構造です。縦持ちは柔軟性が高く、新しい属性の追加が容易ですが、クエリが複雑になる傾向があります。
-
生成AI系のデータ分析基盤
- 生成AIに最適化したデータ分析基盤構築、データ分析基盤を開発する上での生成AI活用など、この分野については学習中なので、引き続き更新したいと思います。
参考文献
Discussion