模倣を越える生成AIのためのフィードバック学習と画像への応用【RLHF, DPO】
模倣を越える生成AI

ここ2-3年で生成AIの性能を模倣を越えたものへと押し上げる試みが爆発的に広まった。ChatGPTは教師あり学習に追加してフィードバックチューニングを行うことで単なる模倣だったGPT-3.5モデルをユーザーフレンドリーなChatBotへと昇華させることで世界で最も早く普及したアプリケーションとなった。この記事では生成AIを模倣を越えたAIへと進化させる手法についてまとめる。
教師あり学習の限界
2022年の頃には生成AIはすでに人間と同じようなテキストを書きカメラで撮ったかのような画像を出力できるようになっていたがChatGPTのような便利なChatBotとして実践的に利用できるレベルではなかった。これはAIが学習時に追求している目的関数と推論時に人間がAIに求めるもののギャップからきている。
生成AIの根幹は教師あり学習によって支えられている。その学習目標は「データを完璧に模倣しろ」だ。この単純な手法は学習方法は学習データを世界中のWebドキュメントへとスケールすることによって爆発的に成長した。
教師あり学習の限界はどこまでいっても模倣の域を出ない点にある。そうなると2つの問題が気になる。
- 学習データ全体の平均的な回答を志向するようになる
- 学習データを越えることができないこと
Webドキュメントは会話文から論説文までさまざまだ。AIはそれらを区別なく「正解」として学習する。結果としてそれらの平均的な回答が返ってくるようになる。しかし推論時に人間がAIに求めるものはニーズに応じた多様な回答だ。例えばChatBotなら会話文を出力してほしいのだ。
もう1つは教師となるデータを越えられないことだ。毎日技術革新が起こっている人間社会に「前例がないことはできない」という制約は存在しない。しかし教師あり学習には「前例のない偉業」を成し遂げる力がない。
フィードバックによる学習

教師あり学習の限界に応えるためにアカデミアでトレンドになっているのが
「生成例」ではなく「生成例に対するフィードバック」から学習する手法である。多くの場合教師あり学習の後に行われる。
教師あり学習からフィードバック学習へと進む流れは人間の学習によく似ている。人間も初心者のころは教師の模倣から学習が始まるが、エキスパートになってくると応用が求められる。品質の高い例示はフィードバックよりもはるかに情報量が多く効率的に学習できるが、エキスパートにとっても学びの多い例示を得ることは極めて難しいのだろう。一流のアスリートはその状態といえる。彼らは例示からではなくフィードバックによって学ぶ。試行錯誤とコーチからのフィードバックだ。大抵の場合コーチは現役のトップアスリートよりも優れたパフォーマンスはできない。それでもフィードバックは成長に欠かせない残された唯一の成長手段だ。
ちなみに「報酬」と呼ばれるフィードバックから学習する方法として、強化学習という技術が古くからある。強化学習は入出力ペアに対してフィードバックを自動で与える「環境」を用意し、フィードバックをもとにエージェントを学習させるアルゴリズムである。近年のフィードバック学習のベースはこの強化学習に基づいている。
RLHF

Reinforcement Learning from Human Feedback (RLHF)はOpenAIが提案したLLMの出力を事前学習した教師データの分布から人間にとって好ましい応答の分布へとズラす研究。ChatGPTもこのRLHFによってチューニングされたと考えられている。
問題設定
そもそもWebドキュメントは会話ばかりではない。だから入力テキストに対してChatGPTのようなAIアシスタントの応答ができるのは、実はすごいことだ。RLHFのゴールは入力に対して人間にとって好ましい出力を返すというものだ。
これを実現するために3ステップでLLMの学習を行う。
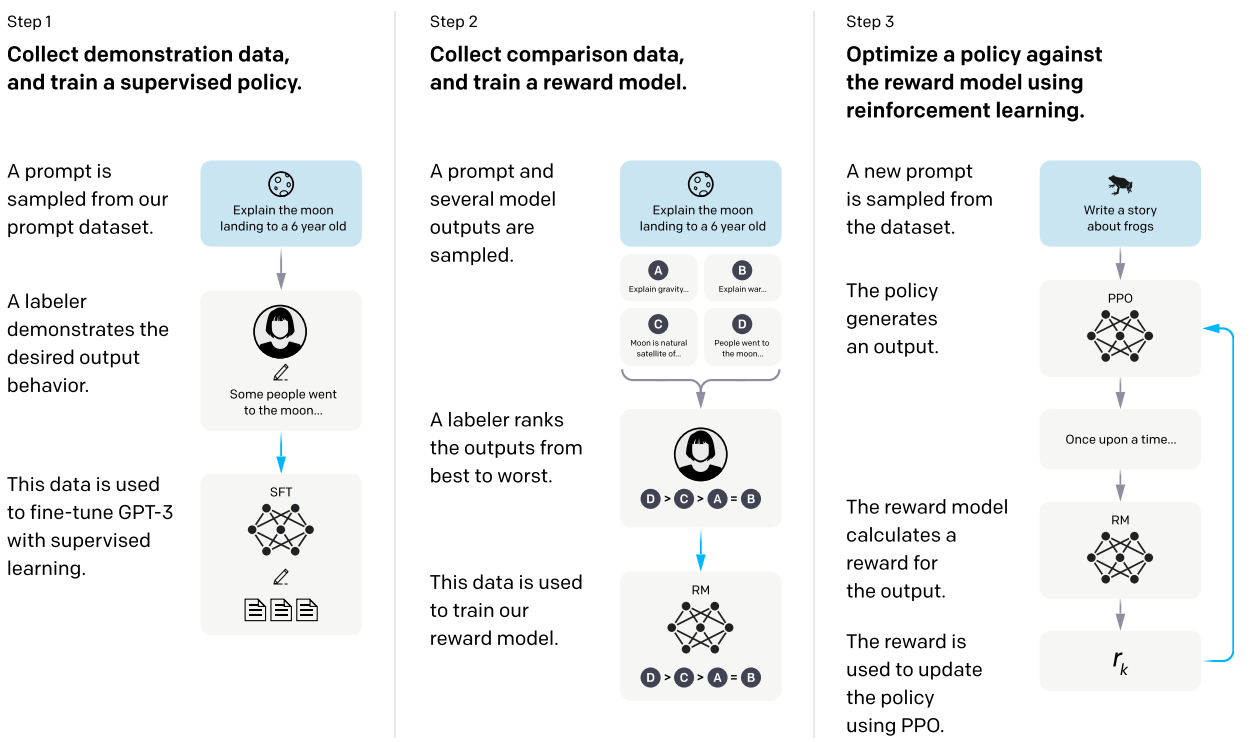
- 会話データセットにおける追加教師あり学習
- 選好データ
(x, y_w, y_l) \sim D r_\phi - 報酬モデル
r_\phi
会話データセットにおける追加教師あり学習
Webのドキュメントを無差別に読みまくった浮世離れしたGPT-3を人間社会に溶け込ませるべく、人との会話とはどんなものであるかを通常の教師あり学習によって学習させた。ChatGPTはもっと多いんだろうが、ここで利用されたデータセットのサイズはわずか13K程度。OpenAIが当時リリースしていたGPT-3の利用者が入力したプロンプトや追加で雇ったアノテーターにかいてもらったものなどを利用した。
報酬モデル
人間にとっての入出力
厳密な数学を追いかける必要はないが、一応Bradley-Terryモデルという由緒正しい選好モデルを採用していて、入力
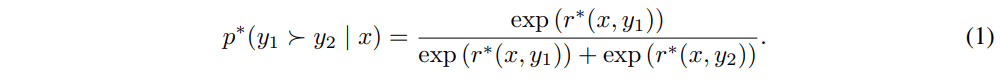
入力
が最大になるように学習したモデル
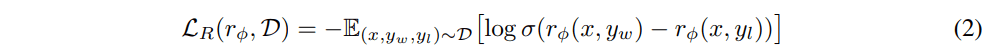
のような損失関数を最小にすれば良いデータと悪いデータの区別がつくようになるだろう。
この学習には新たな33Kのデータをラベラーに作らせた。プロンプトに対してのAIの生成結果を並べ替えるだけなので負荷は小さい。

強化学習
全自動報酬関数を手に入れたので、あとはこの報酬関数をもとにGPT-3の出力をユーザーが望むもとへとチューニングしていく。損失関数は次のようなものだ。

ここでは31Kのデータセットが用いられた。一貫してデータセットのサイズが小さい。しかし次に示すように効果は絶大だ。
会話ができるAIが爆誕
実際に生成された会話をみてみる。

意味のわからない質問を投げかけてみるというイジワルな実験だ。おどろくべきことにGPT-3は質問に沿って会話を生成させることすらできなかった。冒頭に書いた通り入力テキストに対してきちんとしたチャット形式での応答をするのは教師あり学習ではできないのだ。RLHFでチューニングされたInstructGPTは質問に対して応答を返している。ただし意味わからない質問に対してもっともらしく答えてしまうという過ちをおかしている。

プログラミングの応答に特化したチューニングデータはほとんどないにもかかわらずユーザーにとってプログラミングに関する質問により詳細で好まれるであろう説明文を付けることもできるようになった。

英語以外もできるらしい。私は読めない。
このように追加で集めたデータはLLMにとってごくわずかでも、事前のLLMの知識を照らし合わせながらユーザーの求める応答をリターンすることができている。これがフィードバック学習の優れた点だ。
100倍のモデルサイズよりも優れた性能
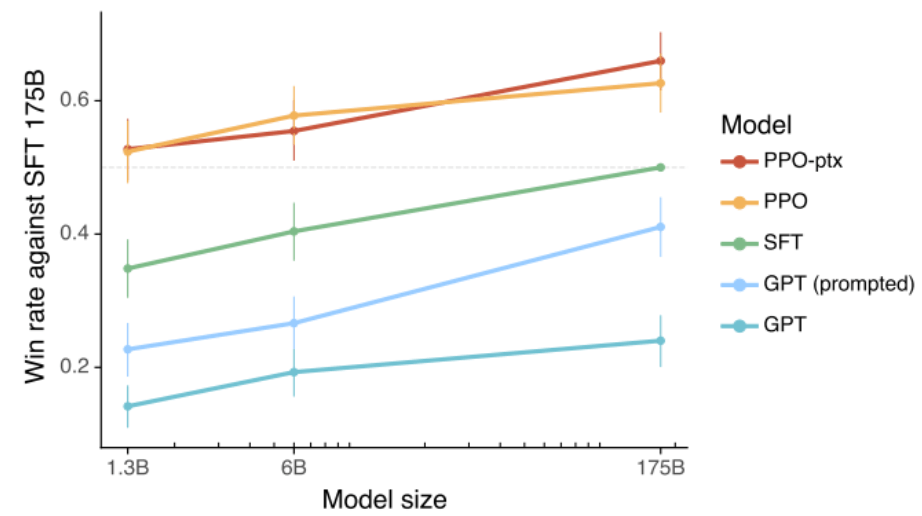
こと人間の求めるレスポンスを返すという意味ではわずか1.3Bのモデルで175Bのモデルよりも高い性能を示した。上の図は生成されたレスポンスの品質を人間によって評価したもので縦軸はもともとのGPT-3 175BモデルにStep1の追加教師あり学習だけを行ったベースラインに対する勝率を示している。
このようにRLHFの登場によって学習済の巨大LLMをわずか数万件程度のサンプルによってチューニングすることが可能なことが示された。とくにLLMにとって大きかった1つ目の課題「Webドキュメントを模倣した平均的な回答が返ってくる問題」を解決しChatBotとしてのAIに求められるような回答が可能になった。
DPO
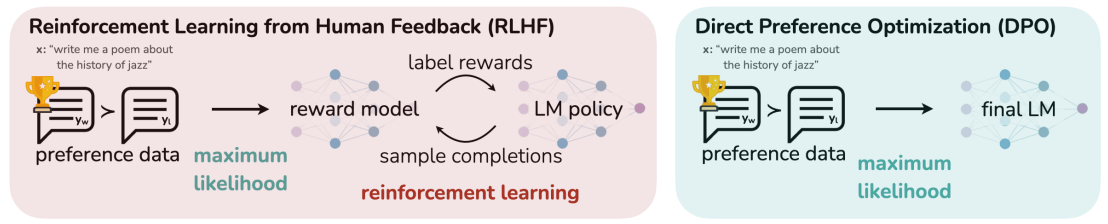
Direct Preference Optimization (DPO)はRLHFをシンプルにしたバージョンだ。タスクとしての新規性はないが、実用面では現在主流の技術になっている。
DPOではRLHFの後半2-stepを1つにまとめたもになっている。すなわち報酬モデルを学習してからPPOするというステップを省略して直接LLMを最適化することにした。単純化しただけではあるが、単純化とはとても重要だ。実装コストは低くなるし、学習は安定的になった。
RLHFと等価な目的関数
RLHFでの2ステップ最適化と同じ最適化が1ステップでできることをこの研究では示す。
この章は数学をする章なので次のお気持ち表明まで読み飛ばしても良い。
RLHFではこんな式を最適化した。
このうち第三項は大規模データセットへのアクセスが必要になるし、面倒なので無視することにする。すると目的関数はこんな感じだった。
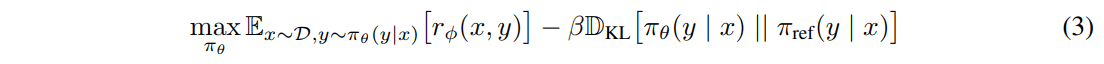
論文が変わってるのでちょっと記号が違う。
この式を次のように展開して整理してやる。
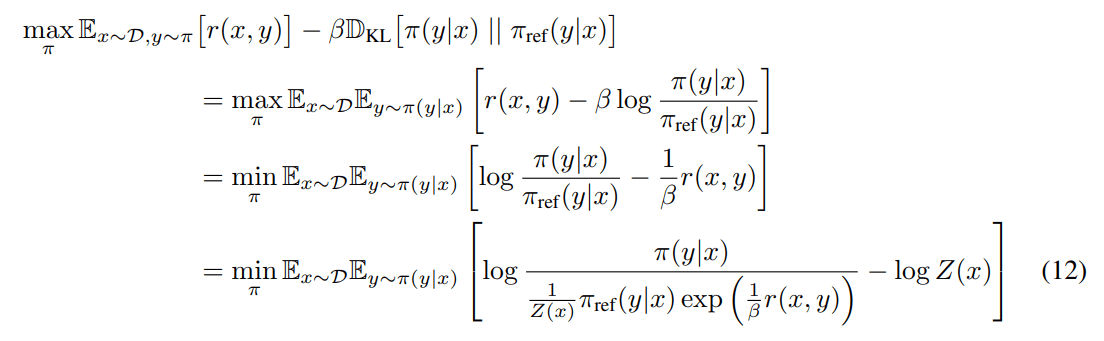
ただし
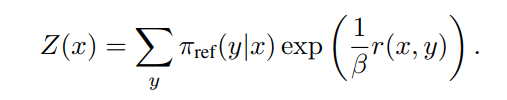
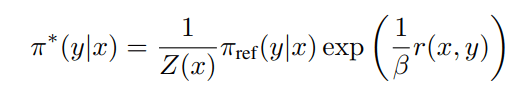
としてまとめると(12)式は
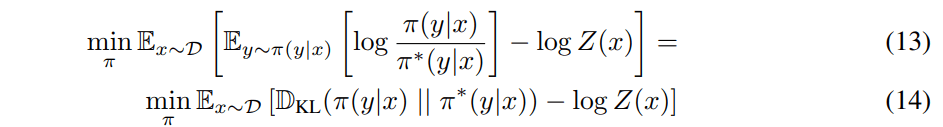
として書き直せる。
以上より目的の方策は
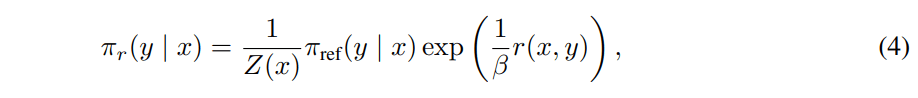
と書かれることがわかった!両辺のLogをとって整理するとこんな感じで報酬関数をかける。
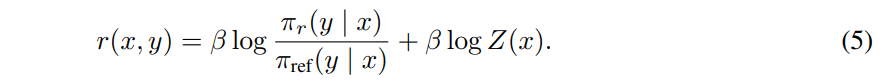
これをもとのBTモデルにいれてやると

RLHFの時と同じくシグモイド関数を使った二値分類問題と思えば最終的な損失関数が得られた!
お気持ち表明
上で導出した損失関数は微分するとこうなる。

みればわかるとおり、実はRLHFやDPOは教師あり学習である。
安定してRLHF以上の性能
RLHFは正則化の強さを示す

上図はtrain/testそれぞれ25kの映画レビューがついたIMDbデータセットである。LLMにレビューの最初の数トークを見せた後、ポジティブな感情のレビュー
他にも2つの実験を行いDPO安定的に高い性能を示すことが証明された。
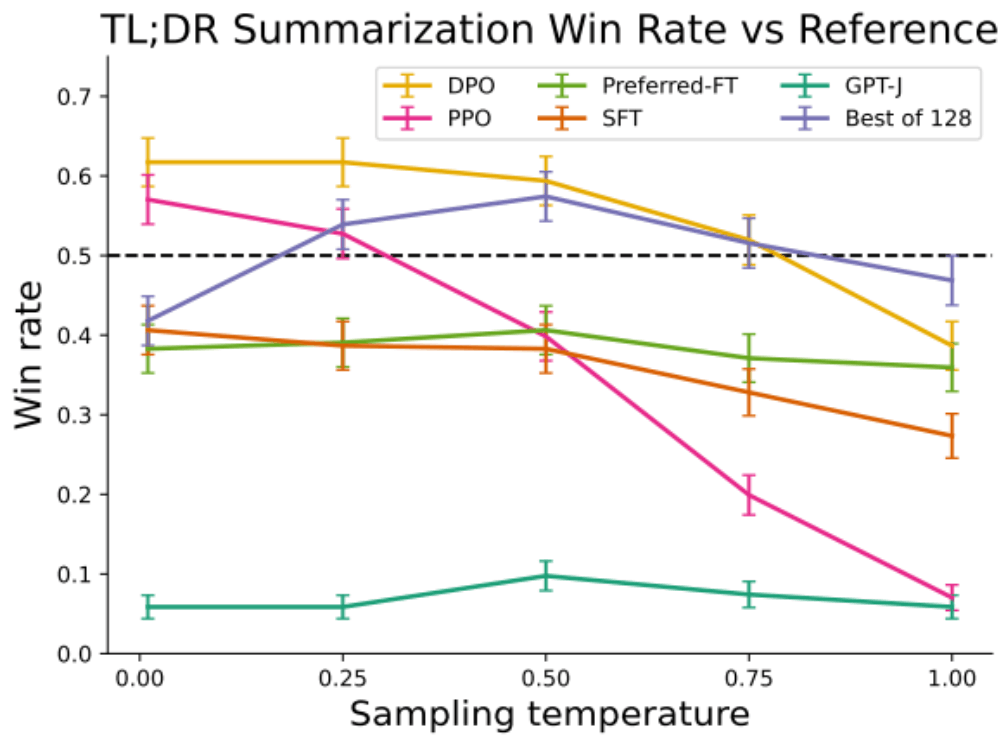
Redditの要約

シングルターン会話
画像への応用
これまでフィードバックを活用したモデルのチューニングは主にLLMに用いられてきた。しかし教師あり学習の限界はLLM以外の生成モデルにも同じく存在する。それはStable Diffusion Web UIを使えばすぐにわかる。このモデルはそれらしい画像を出力してくれるがユーザーの思った通りに調整してProductionクラスの生成結果を追求するのはWebから見境なくダウンロードされた画像で学習されたモデルでは困難なのだ。
幸いなことにText-to-Image Diffusion Modelsの領域においてもフィードバックチューニングを行う研究が登場している。
Diffusion-DPO
2023年の11月に登場したDiffusion-DPOはSalesforceが提案するText-to-Image Diffusion領域でのDirect Preference Optimizationである。
この研究のすごいことは3つある。
- 明らかにキレイな画像が出力されること
- 論文執筆時点でHPSv2ベンチマークのトップを獲得していること
- AIによる自動ラベリングでも性能を向上させていること
明らかにキレイな画像が出力される
見た瞬間にわかる改善幅
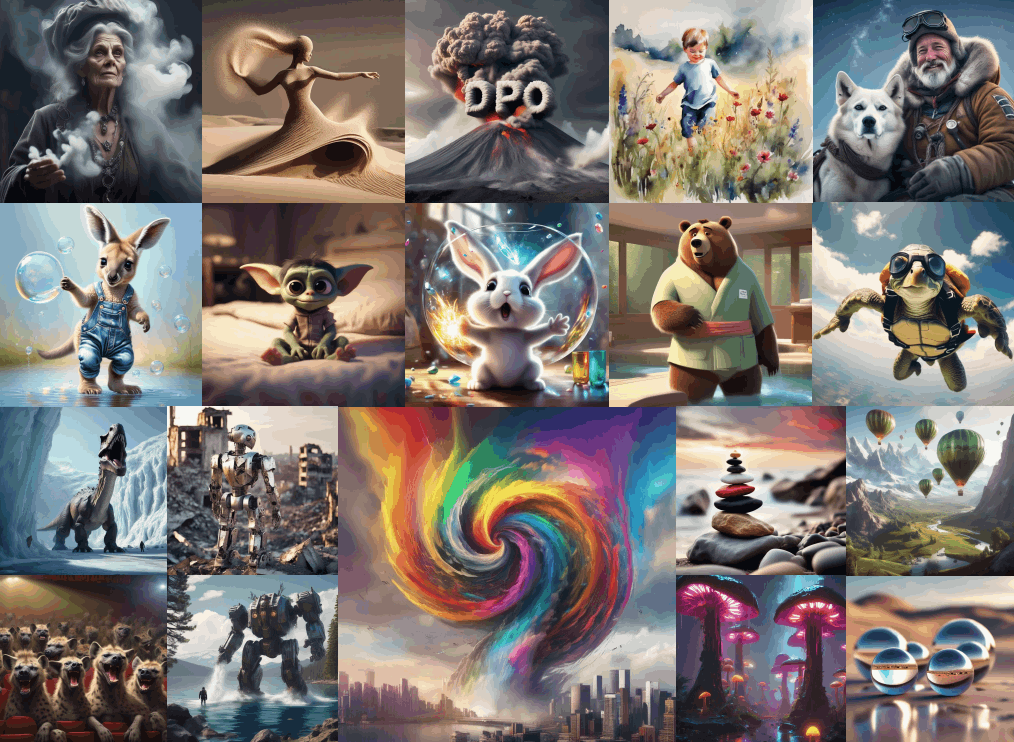
苦手だった指の数なども克服したか

記事執筆時点でHPSv2ベンチマークのトップを獲得
人間にとって好ましい画像を生成できているかを算出するベンチマークHPSv2(AIによる自動評価)がある。論文によると提案手法はHPSv2において28.16の性能を示している。
既存のスコアを大幅に改善。
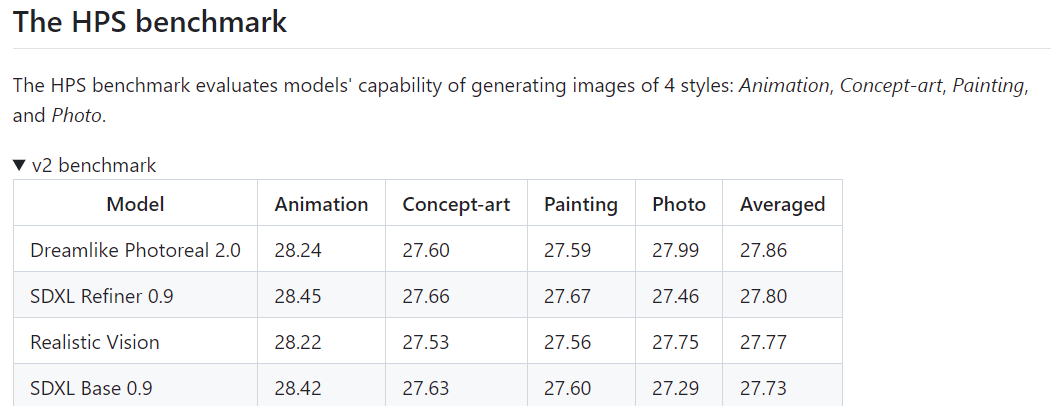
記事執筆時点のベンチマーク
AIによる自動ラベリングでも性能を向上
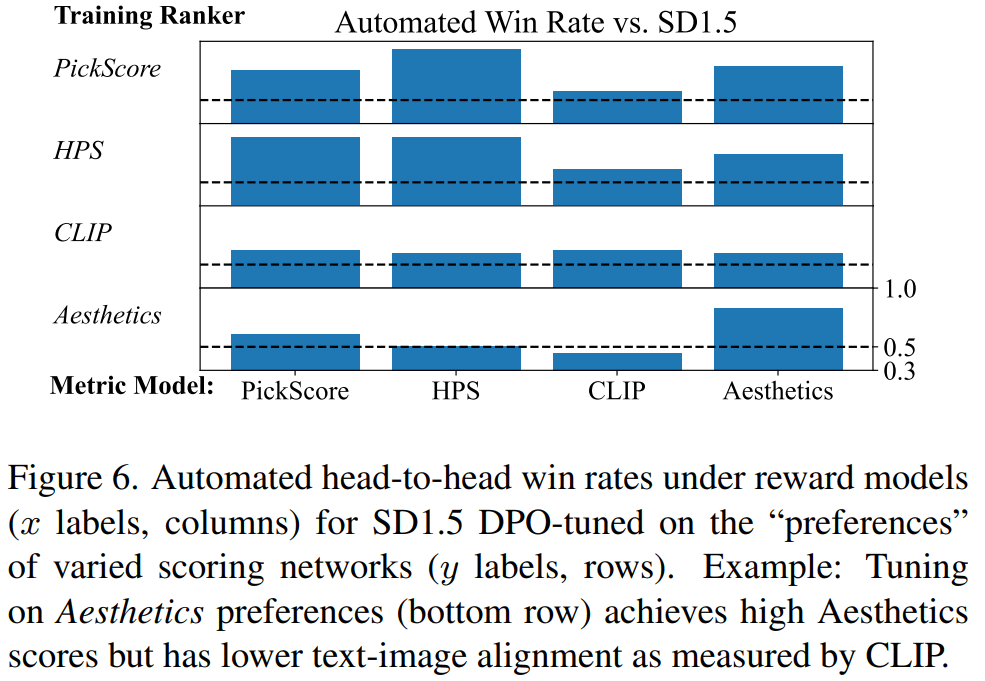
人間がAIに知識を与える時代は終わったのかもしれない。人間のかわりにPickScoreを使って生成したトリプレット
手法(お気持ち表明)
単にDPOをDiffusionに持ち込んだだけではあるのだが、それがなかなか難しい。というのもDPOの最適化には
Transformerが次単語の離散確率分布をベクトルとして出力するLLMと違ってDiffusionは逆過程のとあるステップの画像
この記事では過程を省略して結論だけ触れる。詳細は論文のSupllementary S2にかいてある。
教師あり学習の時と同様、途中のグロい導出は嘘だったかのように導出される損失関数が美しい。DPOであることは変わらないのでLLMにおけるDPOと解釈一致な式を得られる。

LLMと同様にWinnerサンプルを模倣しLoserサンプルを反面教師として、元のモデルからの距離を調整しながら学習していくだけだ。
この学習のためにはLLMのDPOと同様入力プロンプト
このデータを使ったDPO-Diffusionの性能は上に挙げた通りで画像ドメインにおけるフィードバックチューニングが今後主流になることは疑いようがない。
結局教師あり学習なのでは
RLHFで提案されたフィードバックによる学習は教師あり学習に代替する基盤モデルの性能を押し上げる手法として注目を集めたが、DPO論文の解析によって、これもまたある種の(半面)教師あり学習のようなものであるとわかってしまった。
結局フィードバックによるチューニングの何がすごかったんだろうか。ここからは論文に基づかない私の解釈になるが、それは反面教師あり学習とAI自身によるデータ作成である。
WinnerサンプルやLoserサンプルは典型的に学習するAI自身が生み出すことになる。普通自分自身が生成したデータに対して教師あり学習しても性能改善は見込めない。しかし「自分自身の生成例のうちフィードバックによって選り分けられたもの」は学習データになりうる。
反面教師あり学習と確率的な探索

フィードバック学習のイメージ
AI自身の生成結果に対するPreferenceデータ
生成AIはどれもが確率的なモデルだ。確率的であるということは、まぐれでとんでもなく良いサンプルを生成することもあるだろう。その確率的な探索はAIが教師を越える唯一の方法だ。もちろんその「まぐれ」の発生確率は元のAIの性能が高いほど良い。そうした背景からフィードバックチューニングは学習とフィードバックを反復して行うことが多い。実際にLLaMa2は人間によるフィードバックと学習のループを5回繰り返したLLaMa2 V5のことを指す。
AIに負けて当たり前の時代へ
恐ろしい点は近年では人間を越えるフィードバックシステムが出来上がりつつあるということだ。RLHFやDPOなどの「生成AI」の成功の裏には「認識AI」の活躍がある。人間に代わって良さとはなんであるかをフィードバックするシステムが高精度で便利に利用できる時代になってきたことがAIの性能を飛躍的に向上させた。
自動でのフィードバックが比較的容易なゲームなどの分野ではAIはとっくに人間を凌駕していた。2017年、最後の将棋電王戦で佐藤名人が敗北してから「将棋ではAIに勝てなくて当たり前」と誰もが思うようになった。私は人間が勝てるタスクとそうでないタスクを分けるのは「自動でフィードバックを得られる仕組みがあるかどうか」だと考えるようになった。
近年、人間から「良さ」の概念を学習し人間に代わってAIが認識とフィードバックを与えるようになった。人類に残される役割はドメインに固有の「良さ」をAIに教えることだけになってしまうのかもしれない。
あとがき
最後まで読んでいただきありがとうございました。個人用ノートからの転載なので読みにくいところもあるかと思います。最後にはポエムのようなものも書いてしまってやや恥ずかしいのですが気に入っていただいた方はシェアやコメントなどいただけますと幸いです。
Discussion