gymnasiumとPytorchで強化学習のカスタム環境を作る
準備
まずはgymnasiumのサンプル環境(Pendulum-v1)を学習できるコードを用意する。
今回は制御値(action)を連続値で扱いたいので強化学習のアルゴリズムはTD3を採用する[1]。
TD3のコードは研究者自身が公開しているpytorchによる実装を拝借する[2]。
import os
import gymnasium as gym
def eval_policy(policy, env_name, seed, eval_episodes=10):
# Thanks to https://github.com/sfujim/TD3
eval_env = gym.make(env_name)
avg_reward = 0.
for _ in range(eval_episodes):
# fix
(state, _), done = eval_env.reset(seed=seed + 100), False
while not done:
action = policy.select_action(np.array(state))
# fix
state, reward, terminated, truncated, _ = eval_env.step(action)
done = terminated or truncated
avg_reward += reward
avg_reward /= eval_episodes
print("---------------------------------------")
print(f"Evaluation over {eval_episodes} episodes: {avg_reward:.3f}")
print("---------------------------------------")
return avg_reward
env_name="Pendulum-v1"
seed=0
load_model=""
save_model=True
file_name = f"TD3_{env_name}_{seed}"
# パラメータ
discount=0.99
tau=0.005
policy_noise=0.2
noise_clip=0.5
policy_freq=2
max_timesteps=100000
start_timesteps=25e3
expl_noise=0.1
batch_size=256
eval_freq=5e3
if not os.path.exists("./results"):
os.makedirs("./results")
if save_model and not os.path.exists("./models"):
os.makedirs("./models")
env = gym.make(env_name)
# Set seeds
env.action_space.seed(seed)
torch.manual_seed(seed)
np.random.seed(seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
kwargs = {
"state_dim": state_dim,
"action_dim": action_dim,
"max_action": max_action,
"discount": discount,
"tau": tau,
"policy_noise": policy_noise * max_action,
"noise_clip": noise_clip * max_action,
"policy_freq": policy_freq
}
# 学習
policy = TD3(**kwargs) # モデルは元のコードからそのまま借用。
if load_model != "":
policy.load(f"./models/{file_name}")
replay_buffer = ReplayBuffer(state_dim, action_dim)
# Evaluate untrained policy
evaluations = [eval_policy(policy, env_name, seed)]
(state, _) = env.reset(seed=seed)
episode_reward = 0
episode_timesteps = 0
episode_num = 0
for t in range(int(max_timesteps)):
episode_timesteps += 1
# Select action randomly or according to policy
if t < start_timesteps:
action = env.action_space.sample()
else:
action = (
policy.select_action(np.array(state))
+ np.random.normal(0, max_action * expl_noise, size=action_dim)
).clip(-max_action, max_action)
# Perform action
next_state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
done_bool = float(done) if episode_timesteps < env._max_episode_steps else 0
# Store data in replay buffer
replay_buffer.add(state, action, next_state, reward, done_bool)
state = next_state
episode_reward += reward
# Train agent after collecting sufficient data
if t >= start_timesteps:
policy.train(replay_buffer, batch_size)
if done:
# +1 to account for 0 indexing. +0 on ep_timesteps since it will increment +1 even if done=True
print(f"Total T: {t+1} Episode Num: {episode_num+1} Episode T: {episode_timesteps} Reward: {episode_reward:.3f}")
# Reset environment
(state, _) = env.reset(seed=seed)
episode_reward = 0
episode_timesteps = 0
episode_num += 1
# Evaluate episode
if (t + 1) % eval_freq == 0:
evaluations.append(eval_policy(policy, env_name, seed))
np.save(f"./results/{file_name}", evaluations)
if save_model: policy.save(f"./models/{file_name}")
ただし元のコードは古いOpenGymを前提に書かれており、そのままではgymnasiumで動かないためいくつか微修正を行っている。
例えば、OpenGymのバージョンが上がった際に以下の変更が必要になっている。
# old
env.seed(seed)
state = env.reset()
# new
(state, _) = env.reset(seed=seed)
# old
state, reward, done, _ = env.step(action)
# new
state, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
学習したモデルを使って制御する。
# 動作確認
from PIL import Image
from IPython.display import Image as IImage
def save_gif(rgb_arrays, filename, duration=60):
frames = []
for rgb_array in rgb_arrays:
rgb_array = (rgb_array).astype(np.uint8)
img = Image.fromarray(rgb_array)
frames.append(img)
frames[0].save(filename, save_all=True, append_images=frames[1:], duration=duration, loop=0)
env = gym.make(env_name, render_mode="rgb_array")
policy = TD3(**kwargs)
policy.load(f"./models/{file_name}")
(state, _) = env.reset(seed=seed)
imgs = [env.render()]
for t in range(500):
action = (
policy.select_action(np.array(state))
+ np.random.normal(0, max_action * expl_noise, size=action_dim)
).clip(-max_action, max_action)
next_state, reward, terminated, truncated, _ = env.step(action)
state = next_state
imgs.append(env.render())
env.close()
save_gif(imgs, "pend_td3.gif")
IImage(filename="pend_td3.gif")

今回はスピード優先でmax_timesteps=100000(1e5)としたが、元のコードではmax_timesteps=1e6となっている。
学習回数を少なくしたせいか、上向きに静止してもわずかに角度差が残ってしまっている。定常偏差のようで面白いが、学習回数を更に増やすとこの角度差は小さくなっていくはずである。
カスタム環境作成
一次元上を飛んでいくロケットを考える。
位置が
このとき原点に静止するよう制御したい。
from os import path
from typing import Optional
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
from gymnasium import spaces
def rk4(f, y, x, h):
k1 = f(y, x)
k2 = f(y + h*0.5*k1, x + 0.5*h)
k3 = f(y + h*0.5*k2, x + 0.5*h)
k4 = f(y + h*k3, x + h)
return y + h *(k1 + 2*k2 + 2*k3 + k4)/6, x + h
class SimpleRocketEnv(gym.Env):
metadata = {
"render_modes": ["rgb_array"],
"render_fps": 50
}
def __init__(self, render_mode: Optional[str] = "rgb_array", dt=0.01):
if not render_mode in self.metadata["render_modes"]:
raise Exception("Unsupported render_mode.")
if dt > 1:
raise Exception("Too large.")
self.render_mode = render_mode
self.dt = dt
self.gole = np.zeros(2)
high = np.array([3.0, 3.0], dtype=np.float32)
self.action_space = spaces.Box(
low=-1, high=1, shape=(1,), dtype=np.float32
)
self.observation_space = spaces.Box(low=-high, high=high, dtype=np.float32)
def step(self, action: np.array):
u = np.clip(action[0], -1.0, 1.0)
prev_state = self.records[-1][0]
t = self.records[-1][1]
def f(state, _):
return np.array([state[1], u], dtype=np.float32)
next_state, next_t = rk4(f, prev_state, t, self.dt)
self.records.append([list(next_state), next_t])
terminated = False
reward = 1/((next_state[0] - self.gole[0])**2 + 1)
if next_state[0] * next_state[1] > 0:
reward -= 10 * abs(next_state[1] - self.gole[1])
else:
reward += 1/((next_state[1] - self.gole[1])**2 + 1)
if abs(next_state[0]) > 2 or abs(next_state[1]) > 2:
terminated = True
reward -= 500
if np.allclose(next_state, self.gole):
terminated = True
reward += 500
return next_state.copy(), reward, terminated, False, {}
def reset(self, *, initial: Optional[np.array] = None, seed: Optional[int] = None, options: Optional[dict] = None):
super().reset(seed=seed)
if initial is None:
state = np.random.uniform(0.5, 1.0, 2) * np.random.choice([-1, 1], 2)
else:
assert len(initial) == 2
state = initial
state = np.float32(state)
self.records = [[state, 0]]
return self.records[0][0], {}
def render(self):
if self.render_mode is None:
assert self.spec is not None
gym.logger.warn(
"You are calling render method without specifying any render mode. "
"You can specify the render_mode at initialization, "
f'e.g. gym.make("{self.spec.id}", render_mode="rgb_array")'
)
return
fig = plt.figure(figsize=(12, 4))
ax = fig.add_subplot(111)
xs = [self.records[-1][0][0]]
ys = [0]
ax.scatter(xs, ys, c="red")
plt.xlim(-2, 2)
plt.ylim(-0.1, 0.1)
plt.tick_params(labelleft=False, left=False)
ax.grid(axis='x')
plt.close()
fig.canvas.draw()
buf = fig.canvas.tostring_rgb()
cols, rows = fig.canvas.get_width_height()
return np.frombuffer(buf, dtype=np.uint8).reshape(rows, cols, 3)
今回render_modesはrgb_arrayのみ対応。
render()では、matplotlibによるグラフを絵として返すようにしている。
step()は内部で報酬をどう計算するかがキモだが、今回は毎ステップごとに、
- 原点に近いほど大きい報酬を与える(+0.2 ~ +1)
- 原点から遠ざかる場合は、速度が大きいほど報酬を減らす(-20 ~ 0)
- 原点に近づいている場合は、v=0に近いほど大きい報酬を追加する(+0.2 ~ +1)
- ゴール(x=0, v=0)に十分近ければ、報酬に+500して終了
- 位置や速度が2以上になった場合、報酬に-500して終了
としている。
gym.envs.register(
id='rocket-v0',
entry_point='__main__:SimpleRocketEnv',
max_episode_steps=500
)
env = gym.make('rocket-v0')
gymnasiumに登録する。
step()では時間を状態に含まないのでtruncatedは常にFalseとしているが、register()でmax_episode_stepsを設定するとその数を超えるとstep()がtruncated=Trueを返すようになる。
また今回はjupyterで実行する関係でentry_pointではパスを__main__で設定しているが、ファイル分割する場合は違う書き方になる。
from PIL import Image
from IPython.display import Image as IImage
import random
def save_gif(rgb_arrays, filename, duration=60):
frames = []
for rgb_array in rgb_arrays:
rgb_array = (rgb_array).astype(np.uint8)
img = Image.fromarray(rgb_array)
frames.append(img)
frames[0].save(filename, save_all=True, append_images=frames[1:], duration=duration, loop=0)
seed=0
env.action_space.seed(seed)
np.random.seed(seed)
env.reset(seed=seed)
frame = []
actions = []
for _ in range(500):
action = random.uniform(-1, 1)
actions.append(action)
env.step(np.array([action]))
frame.append(env.render())
save_gif(frame, "rocket.gif")
IImage(filename="rocket.gif")
推力をランダムrandom.uniform(-1, 1)に与え、動作確認をする。
位置xを赤、速度vを青でプロットする。
import math
fig = plt.figure(figsize=(12, 8))
ax = fig.add_subplot(111)
records = env.get_wrapper_attr('records')
dt = env.get_wrapper_attr('dt')
xs = [r[0][0] for r in records]
vs = [r[0][1] for r in records]
ts = [r[1] for r in records]
ax.plot(ts, xs, c="red")
ax.plot(ts, vs, c="blue")
plt.xlim(0, math.ceil(ts[-1] / dt) * dt)
plt.grid(True)

初期値はランダムに設定したところ、x=0.77440673, v=0.85759467であった。
ランダムにスラスターを吹いているが初期の速度を殺しきれず、範囲外に出てしまう様子がgifアニメーションで確認できる。
カスタム環境で学習
env_name="rocket-v0"
max_timesteps=1e6
としてTD3の学習を実行する。
学習後、初期値 x=1, v=0でどう制御されるかを確認する。
env = gym.make(env_name, render_mode="rgb_array")
policy = TD3(**kwargs)
policy.load(f"./models/{file_name}")
(state, _) = env.reset(seed=seed, initial=np.array([1, 0]))
imgs = [env.render()]
actions = []
for t in range(1000):
action = (
policy.select_action(np.array(state))
+ np.random.normal(0, max_action * expl_noise, size=action_dim)
).clip(-max_action, max_action)
actions.append(action)
next_state, reward, terminated, truncated, _ = env.step(action)
state = next_state
imgs.append(env.render())
if terminated:
break
save_gif(imgs, "rocket_td3.gif", duration=1000/env.metadata["render_fps"])
IImage(filename="rocket_td3.gif")
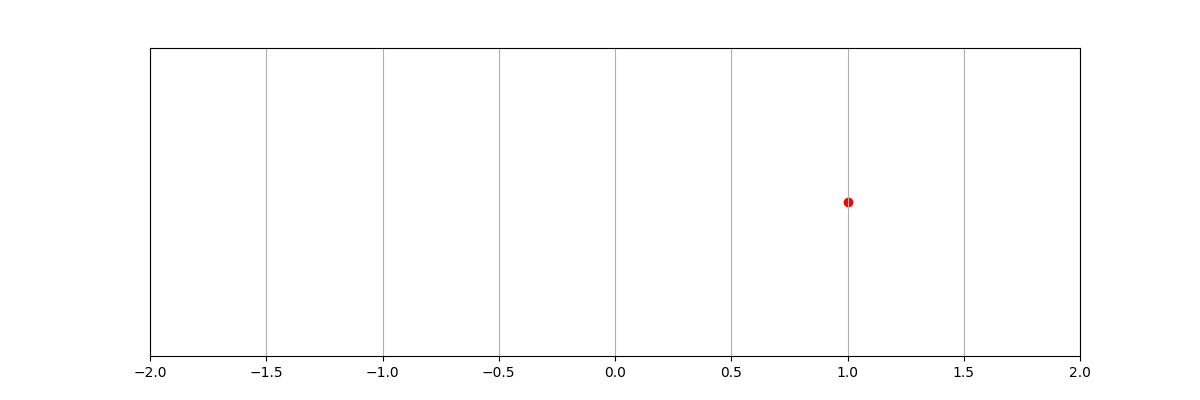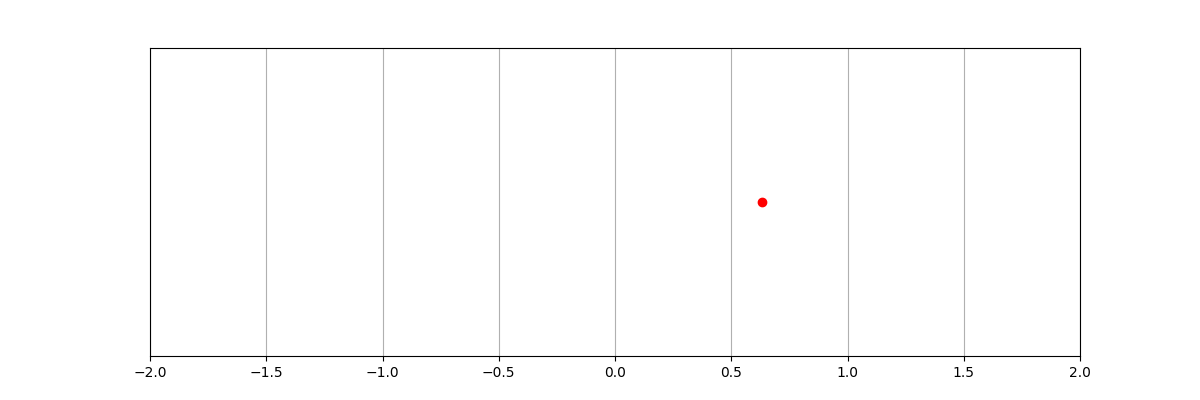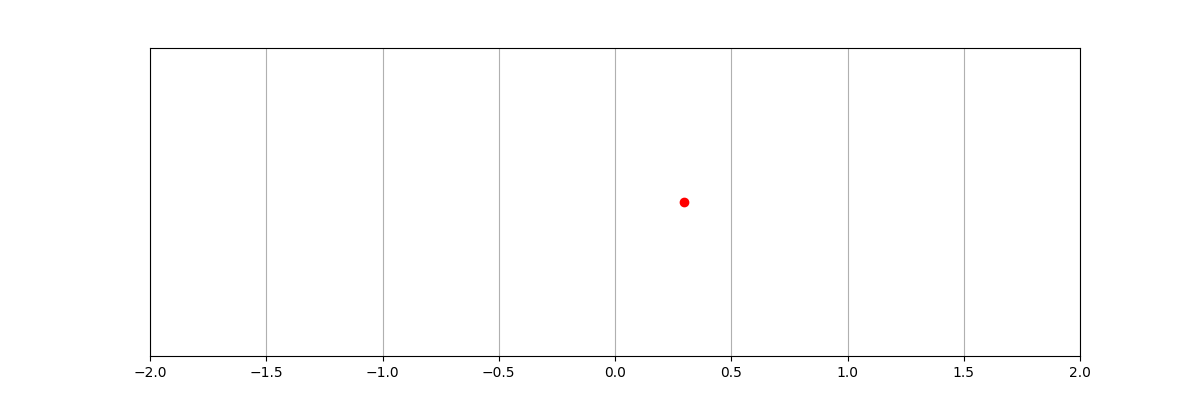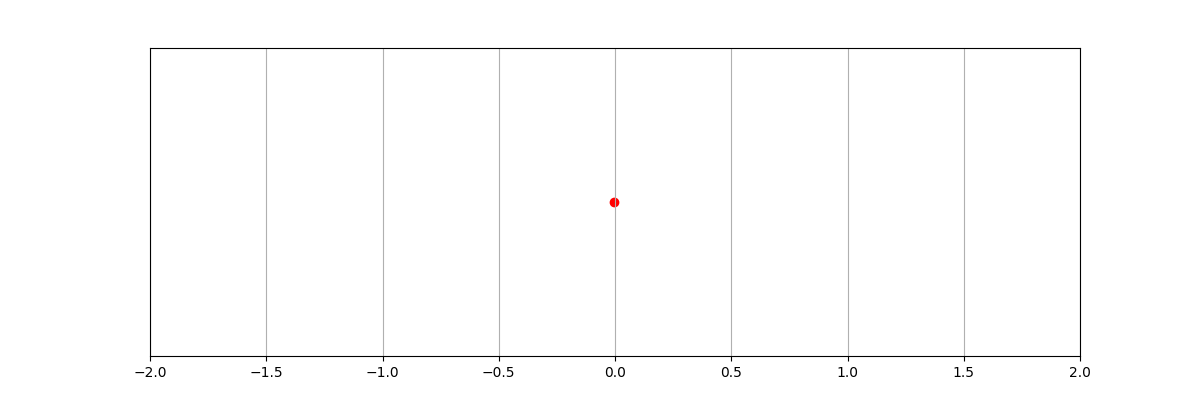
原点に近づいていく様子がわかる。

500ステップ以上放置してもおおよそ原点の近くに滞在している。
ただし常に細かな制御がなされており、静止はしていないし、原点にぴったり一致できているわけではない[3]。
-
actionが離散値の問題を扱いたければつくりながら学ぶ!深層強化学習がわかりやすく初学者にはよい。 ↩︎
-
論文を読んでもバッチサイズやレイヤー数などハイパーパラメータをいくつにしたらいいかわからないことがほとんどだし、世の中に出回っているライブラリでもなぜその値にしたのかわからず気持ち悪い。論文の作者本人がコードで公開してくれていると、その性能の良し悪しはさておき、とりあえず試すにあたって安心感があるのでたいへん助かる。 ↩︎
-
すごくシンプルな問題だし、そこそこな学習回数を重ねたので、バッチリ原点にアプローチできると期待していたがそうはならなかった。古典のPID制御はすごいと改めて感じる。 ↩︎
Discussion