🦔
[FLEX ATTENTION]
Key Contributions
| speed | detail | |
|---|---|---|
| high resolution attention | slow | high |
| low resolution attention | high | low |
| flex attention | middle | high |

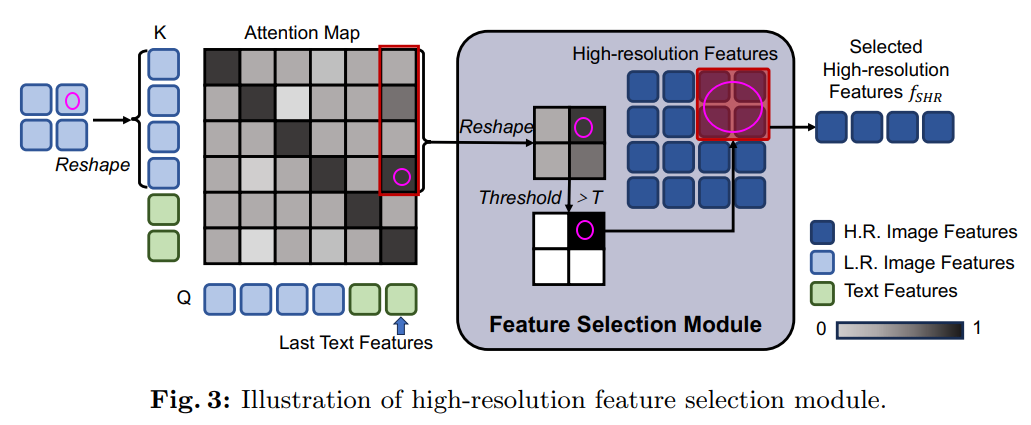
high-resolution feature selection
- self-attention with low resolution
- find high attention score pixels
- extract that pixel from high resolution map
Hierarchical Self-attention
make attention with
N: number of low resolution pixels
M: numer of high resolution pixels
Q: N
K: N+M
V: N+M
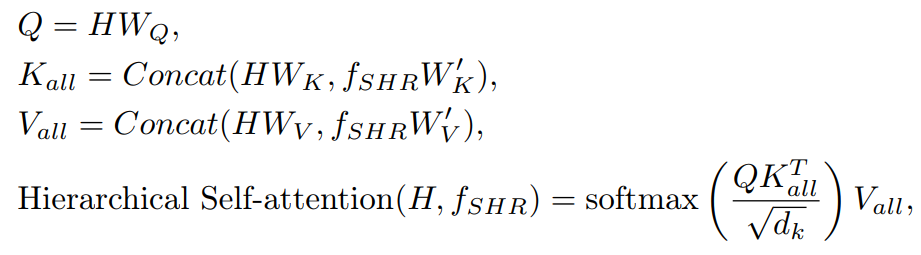
Reference
FlexAttention for Efficient High-Resolution Vision-Language Models
Discussion