🐕
[KVCache] SQUEEZEATTENTION
Issue to Solve
Layer wise importance
some layers are not important -> reduce max_KVCache_token

Full Cache
waste to keep the same amounts of KVCache for all layers

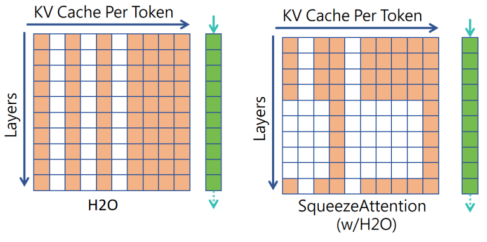
Key Contributions
H2O + SqueezeAttention
H20(keep only top-k important tokens) + layerwise k(max_token) based on importance of each layer
Sliding Window + SqueezeAttention
Sliding Window(keep only k recent tokens) + layerwise k(max_token) based on importance of each layer

Reference
SQUEEZEATTENTION: 2D MANAGEMENT OF KVCACHE IN LLM INFERENCE VIA LAYER-WISE OPTIMAL BUDGET
Discussion