デモ実装で考えるStrands Agentsのいいところ
2025年5月、AWSからStrands AgentsというAIエージェントフレームワークが公開されました。
昨今数多のAIエージェントフレームワークがある中で、Strands Agentsを選ぶ価値を探るべく実際に触ってみたいと思います。
その触る過程として、今回はStrands Agentsによるエージェントアプリケーションとそれが使用するMCPサーバーを開発してみます。
まずは完成物から
デモ
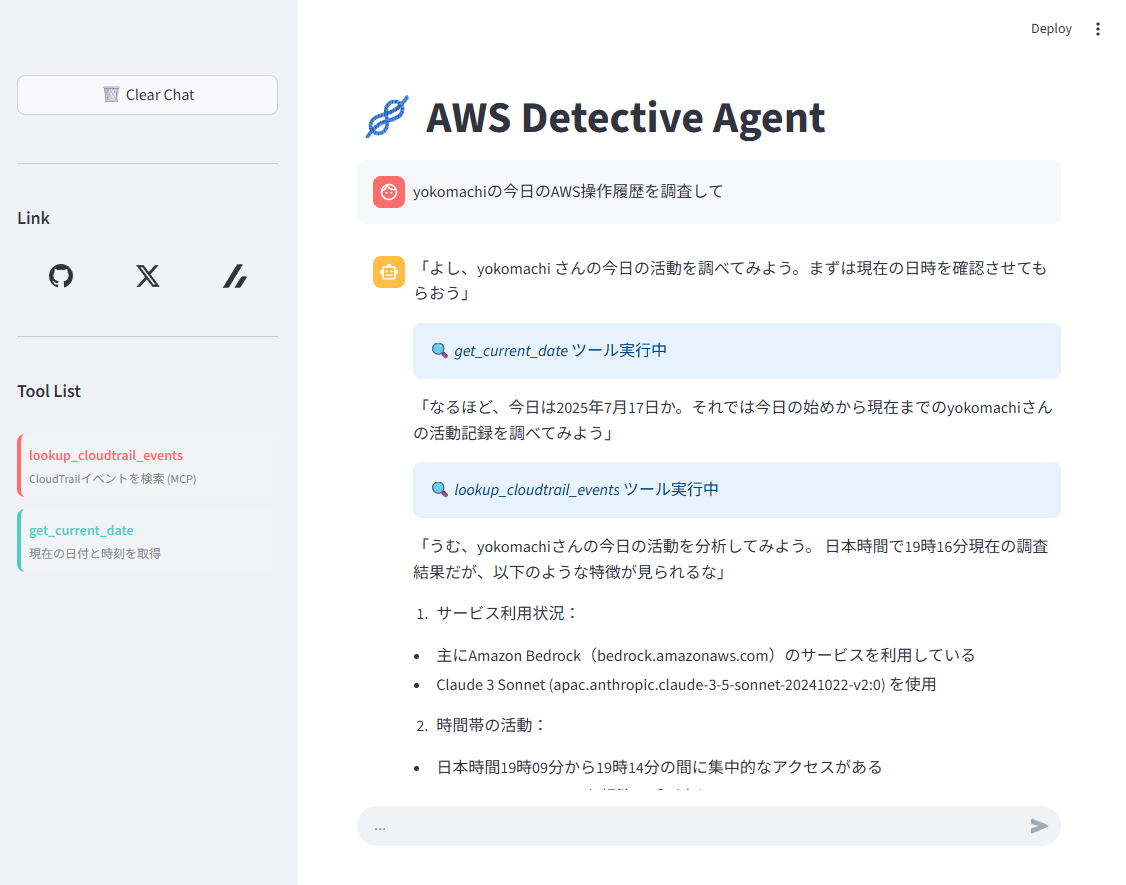
今回作成したデモアプリケーションはこんな見た目です。
ごく単純なチャットボットですが、ユーザーの要望に応じて現在時刻を取得するツール、CloudTrailからの履歴を取得するツールを使って回答を生成します。
なお、現在時刻の取得はエージェントが内部に持つ組み込みツールで、CloudTrailの履歴取得はAWS Lambdaに構築したリモートMCPツールを呼び出しています。
GitHubリポジトリ
以下のリポジトリにソースコードを公開しています。
CDKでモノレポ構成をとっています。
LTしました
この記事の内容をテーマにLTをしました。
スライド資料はこちらをご覧ください。
動画はこちら
Strands Agentsとは
Strands AgentsはAWSが5月に発表したオープンソースのAIエージェントSDKです。
2025年6月時点ではPython向けのものが公開されています。
エージェントのワークフロー定義を開発者が行うフレームワークとは異なって「モデル駆動型アプローチ」を採用し、推論・ツール使用・応答生成のサイクルを最先端LLMの性能に委ねるアプローチをとっています。
Strands Agentsはプロンプト、コンテキスト、使用できるツールをLLMに渡しながら呼び出し、LLMが動的に計画したステップの遂行を繰り返す、「Agentic Loop」をコアコンセプトとしています。
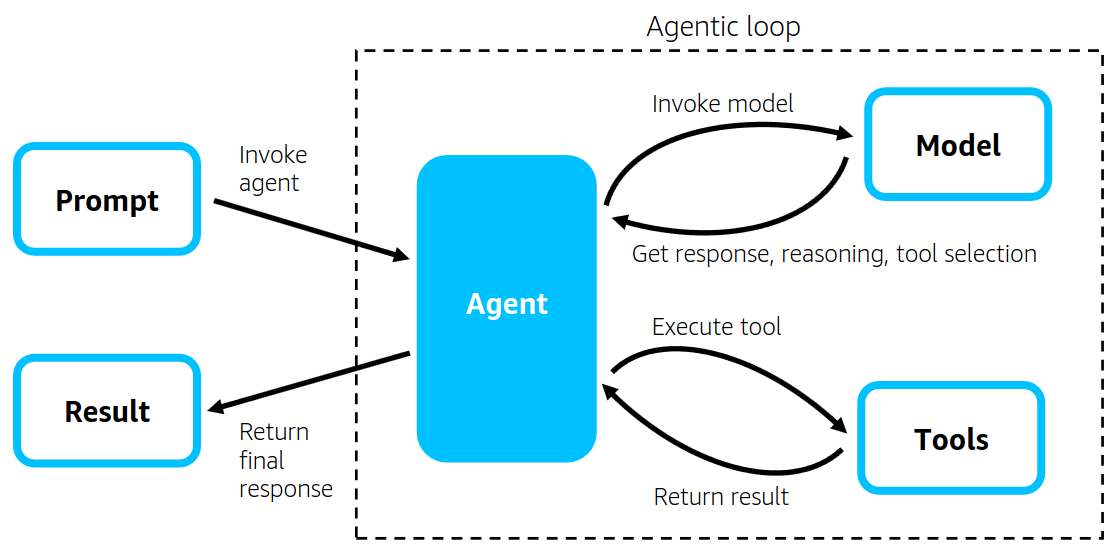
下記URLより引用
詳細については発表時のドキュメントを参照ください。
・ドキュメント ・GitHub repo
MCPとは
MCPはModel Context Protocolの略で、外部システムなどがLLMに対してコンテキストを提供するためのプロトコルのことを指しています。
今年に入ってから話題になり、当初はローカルでMCPサーバーを立ててローカルのLLMアプリケーションから利用するパターンが多かったと思いますが、
早々に各種サービスがリモートMCPサーバーを公開したり、開発者がリモートMCPサーバーをデプロイする環境ができたり、
そして次々とLLMアプリケーションやエディタなどがMCPクライアントの機能を備えていったことにより、急速に普及してきました。
一応私もローカルMCPの入門記事を書いてみたりもしたので良ければ見てください👇
(4か月前の記事なのですでに時代遅れかも)
要件・設計
要件整理
今回開発するデモの要件は以下の通りです。
- チャットベースでAIエージェントと会話できる
- 「AWSで○○(ユーザー名)の作業内容を調査して」などのメッセージに対して、以下のツールを介して回答を生成できる
- 現在時刻を取得する内部ツール
- CloudTrailの履歴を取得するMCPツール
- すべてをAWS上に構築する
技術要素の整理
上記の要件を実現するため、以下の技術要素を使用します。
- エージェント
- AIエージェントフレームワークにはStrands Agentsを使用
- LLMにはAmazon Bedrockで使用できるモデルから、Claude 3.5 Sonnet V2を使用
- MCPサーバー
- MCPツール、サーバーはAWS Lambda上に構築。フロントに合わせてPythonで作る
- LambdaにWebサーバー機能を持たせるため、Lambda Web Adapterを使用
- MCPツールからはAmazon CloudTrailのAPIを実行する
- すべてをAWS CDKで構築する
構成図
今回の構成、つまりこういうことになります。
※接続元のIPアドレスを制限したかったのでALBをかましています。

開発・構築
では実装していきます。
MCP Server on Lambda
まずはMCPサーバーの実装です。
以下のライブラリやツールを使用しています。
・FastMCP
MCPサーバーやツールの定義がシンプルに実装できるライブラリ。
MCP公式のPython SDKに統合されたFastMCP 1.0と、機能拡張を続けるFastMCP 2.0がありますが、今回は2.0の方を使います。
・Lambda Web Adapter
Lambda関数が受け取るイベントをLambda独自の形式ではなくHTTPリクエストとして受け取るために、Lambda Web Adapterを使用します。
なお、今回Lambda関数に対してはFunction URLsで直接HTTTPアクセスします。
Lambdaのコードは以下のとおりです(抜粋)
# FastMCP サーバーの初期化(ステートレスモード)
mcp = FastMCP(stateless_http=True, json_response=True)
# CloudTrail クライアントの初期化
def get_cloudtrail_client():
"""CloudTrailクライアントを作成"""
region = os.environ.get('AWS_REGION', 'ap-northeast-1')
return boto3.client('cloudtrail', region_name=region)
# MCPツールの定義。実質CloudTrailのLookupEvents APIをラップしただけ
@mcp.tool
def lookup_cloudtrail_events(
start_time: str,
end_time: str,
username: Optional[str] = None,
max_records: int = 50
) -> Dict[str, Any]:
"""
CloudTrail APIのlookup_eventsを実行してイベント履歴を取得
Note: CloudTrail APIの制限により、LookupAttributesには1つの属性のみ指定可能です。
Args:
start_time: 検索開始時刻 (ISO 8601形式, 例: "2024-01-01T00:00:00Z")
end_time: 検索終了時刻 (ISO 8601形式, 例: "2024-01-01T23:59:59Z")
username: フィルターするユーザー名 (オプション)
max_records: 取得する最大レコード数 (1-50, デフォルト: 50)
Returns:
Dict[str, Any]: CloudTrail イベントのリスト
"""
try:
cloudtrail = get_cloudtrail_client()
# パラメータの準備
lookup_params = {
'StartTime': datetime.fromisoformat(start_time.replace('Z', '+00:00')),
'EndTime': datetime.fromisoformat(end_time.replace('Z', '+00:00')),
'MaxResults': min(max_records, 50) # APIの制限により最大50
}
# ユーザー名フィルターの追加(指定された場合のみ)
if username:
lookup_params['LookupAttributes'] = [
{
'AttributeKey': 'Username',
'AttributeValue': username
}
]
# CloudTrail APIの実行
response = cloudtrail.lookup_events(**lookup_params)
return {
'status': 'success',
'events': response.get('Events', []),
'next_token': response.get('NextToken'),
'total_events': len(response.get('Events', []))
}
except Exception as e:
return {
'status': 'error',
'error_message': str(e),
'error_type': type(e).__name__
}
# FastAPIアプリケーションを取得
app = mcp.http_app()
これだけです。
FastMCPのおかげでとてもシンプルな実装ができました。
また、Lambdaにデプロイする際にLambda Web Adapterをパッケージに含めるため、以下のDockerfileを記述します。
FROM ghcr.io/astral-sh/uv:python3.13-bookworm
# Copy AWS Lambda Web Adapter
COPY /lambda-adapter /opt/extensions/lambda-adapter
WORKDIR /app
COPY pyproject.toml README.md /app/
RUN uv sync
COPY . ./
ENV UV_CACHE_DIR=/tmp/uv-cache
ENV UV_NO_SYNC=1
ENV AWS_LAMBDA_ADAPTER_BUFFER_OFF=1
ENV AWS_LAMBDA_ADAPTER_CALLBACK_PATH="/callback"
ENV AWS_LAMBDA_ADAPTER_HTTP_PROXY_BUFFERING="off"
ENV PYTHONPATH=/app
ENV PATH="/app/.venv/bin:$PATH"
CMD ["uvicorn", "cloudtrail_mcp.main:app", "--host", "0.0.0.0", "--port", "8080"]
それからpyproject.toml
[build-system]
requires = ["hatchling"]
build-backend = "hatchling.build"
[project]
name = "cloudtrail-mcp"
version = "0.1.0"
description = "CloudTrail MCP Server"
readme = "README.md"
requires-python = ">=3.11"
dependencies = [
"fastmcp==2.10.4",
"boto3==1.35.94",
"uvicorn==0.34.0",
]
[tool.hatch.build.targets.wheel]
packages = ["cloudtrail_mcp"]
[tool.uv]
dev-dependencies = []
また、Lambda部分のCDKスタックは以下のように記述しています。
// CloudTrail MCP Server Lambda (Container Image)
const cloudtrailMcpFunction = new lambda.DockerImageFunction(this, 'CloudTrailMCPServer', {
code: lambda.DockerImageCode.fromImageAsset('./lambda'),
memorySize: 256,
timeout: cdk.Duration.minutes(15),
architecture: lambda.Architecture.ARM_64,
environment: {
UV_CACHE_DIR: '/tmp/uv-cache',
UV_NO_SYNC: '1',
AWS_LAMBDA_ADAPTER_BUFFER_OFF: '1', // この辺は明示的に設定する必要ないかも
AWS_LAMBDA_ADAPTER_CALLBACK_PATH: '/callback',
AWS_LAMBDA_ADAPTER_HTTP_PROXY_BUFFERING: 'off',
PYTHONPATH: '/app',
PATH: '/app/.venv/bin:$PATH'
},
role: cloudtrailMcpRole,
description: 'CloudTrail MCP Server with FastMCP and Lambda Web Adapter'
});
// Function URL
const functionUrl = cloudtrailMcpFunction.addFunctionUrl({
authType: lambda.FunctionUrlAuthType.NONE,
invokeMode: lambda.InvokeMode.BUFFERED,
cors: {
allowCredentials: true,
allowedHeaders: ['*'],
allowedMethods: [lambda.HttpMethod.ALL],
allowedOrigins: ['*']
}
});
Agent with Stranda Agents
続いてStrands Agents + StreamlitによるAIエージェントの実装です。
エージェントの実質的な定義部分は以下の通りです。
# 使用するモデルの定義
bedrock_model = BedrockModel(
model_id='apac.anthropic.claude-3-5-sonnet-20241022-v2:0',
region_name='ap-northeast-1',
temperature=0.7,
max_tokens=4000
)
# 中略
# リモートMCPサーバーのURL
# Lambda関数のFunction URLsの末尾に/mcpをつける
# ex.) https://{fucntion-urls-id}.lambda-url.ap-northeast-1.on.aws/mcp
MCP_URL = os.environ["MCP_URL"]
# MCPクライアントの初期化
mcp_client = MCPClient(lambda: streamablehttp_client(MCP_URL))
with mcp_client:
# MCPツール、内部ツールのリストを作成
mcp_tools = mcp_client.list_tools_sync()
all_tools = list(mcp_tools) + [get_current_date]
# エージェントの定義
agent = Agent(
model=bedrock_model,
tools=all_tools,
system_prompt=system_prompt
)
# エージェントの応答をストリーミング
# stream_agent_response関数でストリーミングしたチャンクからテキストなどを取得して表示
loop = asyncio.new_event_loop()
response = loop.run_until_complete(stream_agent_response(agent, prompt, st.container()))
loop.close()
# 会話履歴に表示
if response:
st.session_state.messages.append({"role": "assistant", "content": response})
Strands Agentsの利用により、エージェントの実装もかなりシンプルになりました。
また、エージェントのCDKスタックは以下のようになります。
こちらは単純にECSにデプロイするものなので特に変わったことはしていませんが、
LambdaのFunction URLsのURLを環境変数に設定するようにしています。
// Task Definition
const taskDefinition = new ecs.FargateTaskDefinition(this, 'StrandsTaskDef', {
memoryLimitMiB: 512,
cpu: 256,
executionRole: fargateExecutionRole,
taskRole: fargateTaskRole
});
// Docker Image Asset
const dockerImageAsset = new assets.DockerImageAsset(this, 'StrandsAppImage', {
directory: './app'
});
// Container Definition
const container = taskDefinition.addContainer('StrandsContainer', {
image: ecs.ContainerImage.fromDockerImageAsset(dockerImageAsset),
logging: ecs.LogDrivers.awsLogs({
streamPrefix: 'strands-app'
}),
environment: {
MCP_URL: `${functionUrl.url}mcp` // Function URLのURLに/mcpをつけて環境変数に設定
}
});
所感
MCP Server on Lambdaの所感
- MCP Server on LambdaについてはSAMでデプロイする記事が現時点では多かったので、今回CDKでの構築例を残せたのはよかったと思う。
- MCPツールを扱い慣れたAWSで構築できるのは体験がいい。
- また、各ツールのアクセス範囲もこれまた扱い慣れたIAMで管理できるのもいい。
- MCPサーバーのエンドポイントの認証についてはLambda Function URLsの場合はIAM認証(署名付きURLでリクエストする形式)しか利用できない。
- 今回は検証なので認証なしで構築したがプロダクション利用ではAPI Gatewayなどで認証をかける必要がある。
- MCPサーバーは必ずしもLambda上にデプロイする必要はない。
- 特にAWSからLambda Tool MCP Serverという、MCP経由でLambda関数を呼び出せるローカルMCPサーバーも公開されており、構築も簡単そう。
- 今回はMCPサーバー自体をリモート化したかったため、Lambda上に構築した。
- 今回の構成

- AWS Lambda Tool MCP Serverを採用した構成例
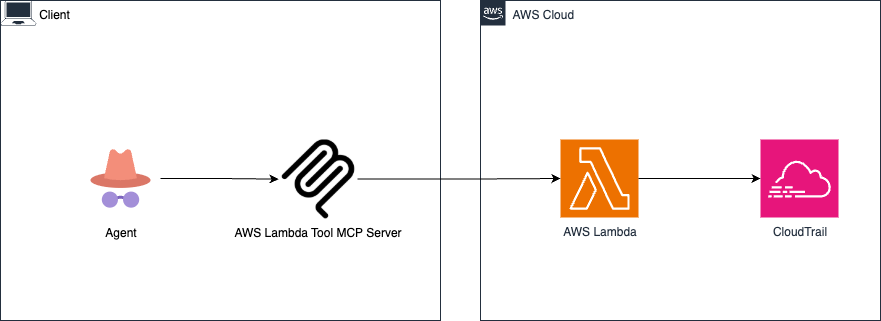
- リモートMCP全般に言えることだが、ローカルにランタイムがなくても設定用のjsonを配るだけでいいので、ノンエンジニアでも扱いやすいのが大きな利点だと感じた。
Strands Agentsの所感
- 今の所UIの実装がStreamlit一強
- チャットボット用途ならChainlitなども良さそう。
- 他のGradioとかDashとかReflexとかはそもそも触ったことがない。
- あとはAG-UIのサポートも期待。一応ロードマップに入っているみたい。https://github.com/ag-ui-protocol/ag-ui?tab=readme-ov-file#framework-support
- また、Strands Agents自体の多言語向けSDKも、時期は未定だがロードマップ上にはあるみたい。https://github.com/orgs/strands-agents/projects/8?pane=issue&itemId=115022363&issue=strands-agents|sdk-python|156
- あとつい最近プレビュー版が公開されたAmazon Bedorck AgentCoreにStrands Agentsによるエージェントロジックをデプロイしておいて、好きなフロントエンドから呼び出す、みたいなことも可能かもしれない。
- MastraのワークフローやLangGraphのエージェント構築は簡単にやってみたことがあるが、Strands Agentsが今のところ一番お手軽。
- 複雑なことをやろうとすれば複雑になっていくかもしれないが、少なくともまず動くものを作ろうとしたらとにかく手軽。モデル駆動の影響が大きいのだと思う。
- とはいえ今回触ったのは表層に過ぎない。
- マルチモーダル処理やメモリ、Slack連携、AWS統合などのツール群が公式提供されており、これらを活用することでより高度なエージェントを作成できる。
- https://github.com/strands-agents/tools
Strands Agentsのいいところ
冒頭に述べたとおり今回の目的はStrands Agentsのいいところを考えることでした。
結論から言うと、私は前述した「お手軽」という点が一番いいところだと感じています。
エージェントの手続きを定義せずともモデルがステップを生成してタスクを実行してくれるモデル駆動アプローチにより、開発者はプロンプトやツール、あるいはRAGやメモリ管理などの開発や調整、すなわちコンテキストエンジニアリングに時間を割くことができる、というのがStrands Agentsにおける価値だと思います。
モデルやエージェントのSDKが変わっても、コンテキストは切り出して使いまわしやすいはずです。
Strands Agentsが提供するのは、そのコンテキストの開発に集中させてくれるという価値なのでは、と今回のデモ開発を通じて感じました。
参考
Discussion