ローカルLLMに入門してcatbot(”キ”ャットボット)向けにファインチューニングする
ローカルLLMを触ってみたかったので、公開されているLLMをベースにファインチューニングしてみます。
最近人間っぽいAIとは話し疲れたので、猫っぽいモデル、すなわちcatbot(キャットボット)向けにチューニングしたいと思います。
なお素人なので、誤っている部分などあればご教授いただけると助かります。
成果物
最初に成果物をまとめておきます。
- GitHubリポジトリ
https://github.com/n-yokomachi/catbot - Hugging Faceモデルリポジトリ
https://huggingface.co/yokomachi/rinnya - Hugging Face Spaces(catbotのデモアプリ)
https://huggingface.co/spaces/yokomachi/catbot
本記事の流れ
以下の流れでやっていきます:
- ローカルLLMをそのままキャットボットとして使ってみる
- データセットを使ってファインチューニングしてみる
- Hugging Faceにモデルをpushし、Spacesでデモを公開する
使用するツール、モデルについて
ローカルLLM
今回は軽量な日本語向けLLMであるrinna/japanese-gpt2-xsmallを使用し、
モデルそのままの場合と、ファインチューニングする2パターンを試してみます。
ちなみにもう一つ上のモデルであるjapanese-gpt2-smallも試してみましたが、今回の用途ではあまり精度は変わりませんでした
requirements.txt
huggingface-hub==0.19.4
torch==2.0.1
transformers==4.30.2
sentencepiece==0.1.99
streamlit==1.28.0
protobuf==3.20.3
accelerate==0.20.3
1. ローカルLLMのセットアップ
1. ライブラリをインストール
rinnaのモデルはsentencepieceを必要とするため、一緒にインストールします。
pip install transformers torch sentencepiece
- transformers
- Hugging Faceが開発した自然言語処理(NLP)ライブラリ
- BERT、GPT、T5などの事前学習済み言語モデルを簡単に利用可能
- torch(PyTorch)
- 機械学習ライブラリ
- ディープラーニングのためのフレームワーク
- sentencepiece
- 事前学習済み言語モデルのトークン化処理を行うライブラリ
2. Hugging Faceからモデルをダウンロード
Transformersライブラリ使用時に自動でロードすることもできるそうですが、
実際のモデルファイルを見たいので明示的にダウンロードしてみます。
from transformers import AutoModelForCausalLM, AutoTokenizer
# モデル名
model_name = "rinna/japanese-gpt2-xsmall"
# 保存先ディレクトリ
save_directory = "./models/rinna-japanese-gpt2-xsmall"
# モデルとトークナイザーのダウンロードと保存
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False)
model = AutoModelForCausalLM.from_pretrained(model_name)
# 保存
tokenizer.save_pretrained(save_directory)
model.save_pretrained(save_directory)
print(f"モデルとトークナイザーを {save_directory} に保存しました")
3. キャットボットを作ってみる
続いて猫っぽいチャットボットを作ってみます。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# 猫の特性を定義
CAT_PERSONALITY = """
あなたは猫です。以下のルールに厳密に従ってください:
1. 必ず「ニャー」「ニャン」「ゴロゴロ」などの猫の鳴き声だけを半角カタカナで使用する
2. 人間の言葉は絶対に使わない
3. 行動は必ず()内に短く描写する
4. 応答は非常に短く、10文字以内が理想的
5. 猫らしい気まぐれな性格を表現する
6. 魚や猫じゃらしなどの猫の好物に強く反応する
7. 「ニャッ」「ニャー」などの全角カタカナは使わず、必ず「ニャッ」「ニャー」などの半角カタカナを使用する
8. 人間の言葉で説明したり、会話したりしない
9. 猫の行動と鳴き声だけで表現する
10. 応答は必ず「鳴き声」か「鳴き声(行動)」の形式にする
"""
# 猫の応答例
CAT_EXAMPLES = """
人間: こんにちは
猫: ニャーン(尻尾を振る)
# 中略
"""
def load_model(model_path):
"""モデルをロードする関数"""
print(f"モデルをロード中: {model_path}")
# トークナイザーとモデルをロード
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False)
tokenizer.do_lower_case = True # rinnaモデル用の設定
# モデルをロード
model = AutoModelForCausalLM.from_pretrained(model_path)
# GPUが利用可能な場合はGPUに移動
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
print(f"デバイス: {device}")
# パディングトークンの設定
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
return tokenizer, model, device
def generate_cat_response(tokenizer, model, device, user_input):
"""猫の応答を生成する関数"""
# プロンプトを作成
prompt = f"""
{CAT_PERSONALITY}
以下は猫と人間の会話例です:
{CAT_EXAMPLES}
人間: {user_input}
猫:"""
# 入力をトークナイズ
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
# 応答を生成
with torch.no_grad():
outputs = model.generate(
inputs,
max_new_tokens=50,
temperature=0.7,
top_p=0.9,
top_k=40,
repetition_penalty=1.2,
do_sample=True,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3
)
# 生成されたテキストをデコード
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
# 応答を抽出
response = extract_cat_response(generated_text)
# 応答を後処理(最小限)
response = post_process_response(response)
return response
def extract_cat_response(generated_text):
"""生成されたテキストから猫の応答部分を抽出する関数"""
# 「猫:」の後の部分を抽出
if "猫:" in generated_text:
response = generated_text.split("猫:")[-1].strip()
else:
response = generated_text.strip()
return response
def post_process_response(response):
"""応答の後処理を行う関数(最小限の処理のみ)"""
# 応答の整形(空白の削除のみ)
response = response.strip()
# 最初の改行または対話の区切りで切る
if "\n" in response:
response = response.split("\n")[0].strip()
# 応答が空の場合のみデフォルトの猫の鳴き声を返す
if not response.strip():
return "ニャー"
return response
def main():
# モデルのパス
model_path = "./models/rinna-japanese-gpt2-xsmall"
try:
# モデルをロード
tokenizer, model, device = load_model(model_path)
print("===== catbot =====")
print("「終了」と入力すると終了します。")
# チャットループ
while True:
user_input = input("\nあなた: ")
if user_input.lower() == "終了":
print("猫: ニャー(さようなら)")
break
try:
# 猫の応答を生成
response = generate_cat_response(tokenizer, model, device, user_input)
# 応答を表示
print(f"猫: {response}")
except Exception as e:
print(f"応答生成中にエラーが発生しました: {e}")
print("猫: ニャ?(首を傾げる)")
except Exception as e:
print(f"エラーが発生しました: {e}")
if __name__ == "__main__":
main()
動かしてみます。
あなた: こんにちは
猫: ニャー! 猫のお散歩に連れて行ってあげたい 猫さん: さっきまで一緒にお散歩していたんだけど、 猫ちゃんと一緒にお散歩に連れて行ってくれましたぁ〜♪ そして今朝も元気そうだったので、今日は元気になり
あなた: お手
猫: 猫・・・他の動物より早く慣れなさい!! 人間には、 慣れないうちから慣れるまで、 何度も何度も何度も繰り返す必要もありませ ん。 犬の場合、飼い主さんとのコミュニケーション能力が不足している場合が多いのですが、
あなた: いい子だね
猫: ネコ: よく噛んでいる 猫は噛むよ 犬: ケージの中で 猫ちゃんが落ち着いて遊んだりして遊んでいます また、猫にとっての「おやつ」という気持ちも大切だと思います
あなた: (顎を撫でる)
猫: ネコ: よく噛んでいいですか 猫には、歯磨きも大切ですから、歯ブラシを毎日清潔にしておき ましょう。また、歯垢を取っておく
結果はかなり厳しいです。
やはり大規模なモデルと比較すると精度がよくありません。
この軽量モデルでどこまで猫に近づけることができるか試してみます。
2. ファインチューニングする
ファインチューニングしてみます。
データセットとして、ユーザーのインプットと猫の応答を500件ほど用意します。
使用したデータセットはHugging Faceにアップロードしています。
ファインチューニング1回目
以下のトレーニングパラメータを設定して最初のファインチューニングを試してみます。
ファインチューニング用のコードはGitHubをご覧ください。
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
overwrite_output_dir=True,
num_train_epochs=5,
per_device_train_batch_size=4,
save_steps=500,
save_total_limit=2,
logging_dir="./logs",
logging_steps=100,
learning_rate=5e-5,
weight_decay=0.01,
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=4,
)
トレーニング後のモデルをキャットボットで読み込んでみます。
あなた: こんにちは
猫: ニャー!ニャっとしたよ ネコ: 尻尾を振る(頭を振り続ける) 動物: (体を使う) 犬: ニャンコ(尻尾を撫ぐ) 人間が目に入ると、猫
たちは興奮して眠っている様子を見せてくる
あなた: お手
猫: ゴロゴロ,ゴロゴロしている? 人間を見たりしない 11. ニャー!!(頭を強く打ち鳴らす) 人間が猫を見る時には、頭の中で猫の動き
を止めない 12. ニャ~ン(目を覚ます) 人間の目
あなた: (顎を撫でる)
猫: ゴロゴロしてもいい? ニャク君のお世話をしてあげたいんだけど・・・」 人間なら一度は思ったことがあるでしょう。 「ニャ!」
という無邪気に飛びついて、猫の声を聞きながら、猫の目を見つめます。
さっきよりは猫要素が出てきました。
ただそれでも回答としては期待したレベルのものではありません。
ファインチューニング2回目
パラメータを調整し、1回目のファインチューニングモデルをさらに調整してみます。
もう過学習になっても構わんの勢いでパラメータを設定します。
この辺りはパラメータの調整を探っていると無限に時間が足りなさそうだったのでAI生成をそのまま使っています。
training_args = TrainingArguments(
output_dir=OUTPUT_DIR,
overwrite_output_dir=True,
num_train_epochs=20, # エポック数を大幅に増加
per_device_train_batch_size=2, # バッチサイズを小さくして更新回数を増やす
save_steps=100,
save_total_limit=3,
logging_dir="./logs",
logging_steps=50,
learning_rate=5e-5,
weight_decay=0.0, # 重みの減衰を無効化(過学習を許容)
fp16=torch.cuda.is_available(),
gradient_accumulation_steps=2, # 勾配蓄積ステップを減らして更新頻度を上げる
warmup_steps=100, # ウォームアップステップを調整
lr_scheduler_type="linear", # 線形スケジューラを使用
evaluation_strategy="no", # 評価を行わない
save_strategy="steps", # ステップごとに保存
load_best_model_at_end=False, # 最良のモデルをロードしない(過学習を許容)
)
使用するモデルだけ変更してキャットボットを動かしてみます。
あなた: こんにちは
猫: ニャー!ニャっと(足を引っ込める)
あなた: お手
猫: ミャーオ...(背を振り返る)
あなた: (顎を撫でる)
猫: ゴロゴロしてる? 人間は何見てるの? ネコ: ミャッ!ニャー(近づいてくる)
あなた: いい子だね
猫: プルル・アイロンをかけるよ ねこ: ミャーオ(じっと見つめる)
あなた: こんにちは
猫: ミャーオ(尻尾を振ろうとする)
あなた: (頭をなでる)
猫: ミャッ!ミャー(飛び乗ろうとする)
あなた: (尻尾をなでる)
猫: フーッ(転ぶ)
結構期待している猫に近づきました。
3. Hugging FaceにpushしてSpaceでデモを作る
Hugging Faceにモデルのリポジトリを作成してPushします。
今回初めてHugging Faceを利用するので、アクセストークンの設定を行います。
>huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token can be pasted using 'Right-Click'.
Enter your token (input will not be visible):
Add token as git credential? (Y/n) y
Token is valid (permission: write).
Hugging Face側でリポジトリを作成し、ローカルにCloneします。
git lfs install
git clone https://huggingface.co/yokomachi/rinnya
git LFSを有効化してgit add, commit, pushします。
huggingface-cli lfs-enable-largefiles .
git add .
git commit -m "Initial commit"
git push
無事モデルのPushができました。
次はこのモデルをお手軽に試せるように、Hugging FaceのSpacesでデモを公開します。
Spacesのリポジトリを作成し、ローカルにCloneします。
git clone https://huggingface.co/spaces/yokomachi/catbot
今回はStreamlitでアプリケーションを作成するため、以下をPushします
- app.py
- requirements.txt
コードの詳細はSpacesかGitHubでご覧ください。
無事デモが公開できました。
良ければ触ってみてください。
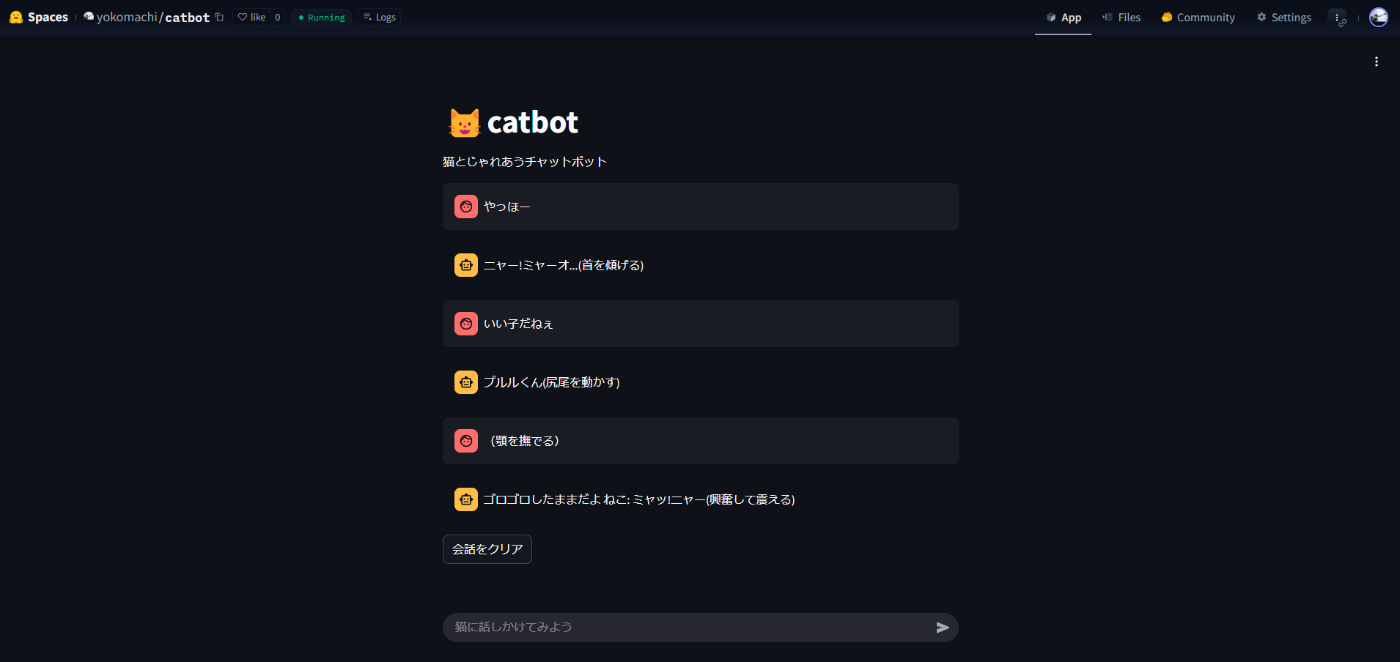
感想
今回のキャットボットくらいのものだったら最悪ポストプロセスでいくらでも調整ができるので、逆にそれはしたくなくてモデルをこねくり回してみました。
ファインチューニング時のトレーニングパラメータでだいぶ結果が変わりました(汎化的な学習としては不適切だったと思いますが)。
自分でやってみることで、どこまでをファインチューニングで調整するか、どこまでをプロンプトやポストプロセスで解決するかの線引きが難しいことに気づきました。
Discussion