Text To SQLは使えない子?社運かけDBベンダー挑む
「1000人以上の組織で働く人々が最も使いたいと考えているインフラツールとその理由は何ですか?」
あなたがチャットアプリの開発者だとして、この質問にどう返すように設計しますか?
単にOpenAIのAPIに質問を送った場合、APIは広大なネットの海から関連しそうな記事を取ってきて返答してくれます。
しかしその記事は本当に正しいのでしょうか。
関連しそうな記事がない場合は?
「1000人以上の組織で働く人々が最も使いたいインフラツール」というコンテキストがあるので、ソースとなるドキュメントからSQLを実行したいですよね。
Text-To-SQLはクエリをSQLに変換する技術です。
回答の根拠が見えることやハルシネーションが起きないことなどメリットがありますが、反面テーブル名やカラム名、データを直接指す質問ばかりとは限らない(リンク先は課題の詳細)などの課題もあります。
またデータベースのカラム名が英語であることが一般的なので、日本語の質問では翻訳する必要があり精度が下がるとも言われています。
そんな発展途上のText-To-SQLですがそれを使って、データベースベンダーのClickHouseがチャットアプリを作ったので紹介します。
意見をまとめるアプリをつくりたい
つくりたいものはHacker NewsやStack Overflowからユーザの意見をまとめてくれるチャットアプリです。
ちょうど冒頭の
「1000人以上の組織で働く人々が最も使いたいと考えているインフラツールとその理由は何ですか?」
「100人未満の従業員を持つ企業で働く人々が最も使いたいと思っているウェブ技術とその理由は何ですか?」
のような質問ですね。
質問には一般的に「構造化された質問」「非構造化の質問」「その組み合わせ」の3つに分類されます。
この間説明した構造化データとは名前が似ていますが違います。
構築するパイプラインも変わってきますので以下に説明します。
構造化された質問
「最も人気のあるデータベースは?」というような、シンプルでSQLにしやすい質問です。
OpenAIにクエリをSQLへ変換してもらい、その結果をClickHouseというDBで検索してその結果をそのまま答えにします。

非構造化の質問
「ClickHouseの評判を教えて」といった現行の技術ではSQLにしにくい質問です。
クエリを埋め込みベクトルに変換し、ClickHouseのDBからコサイン類似度で最も近いベクトルを取得します。
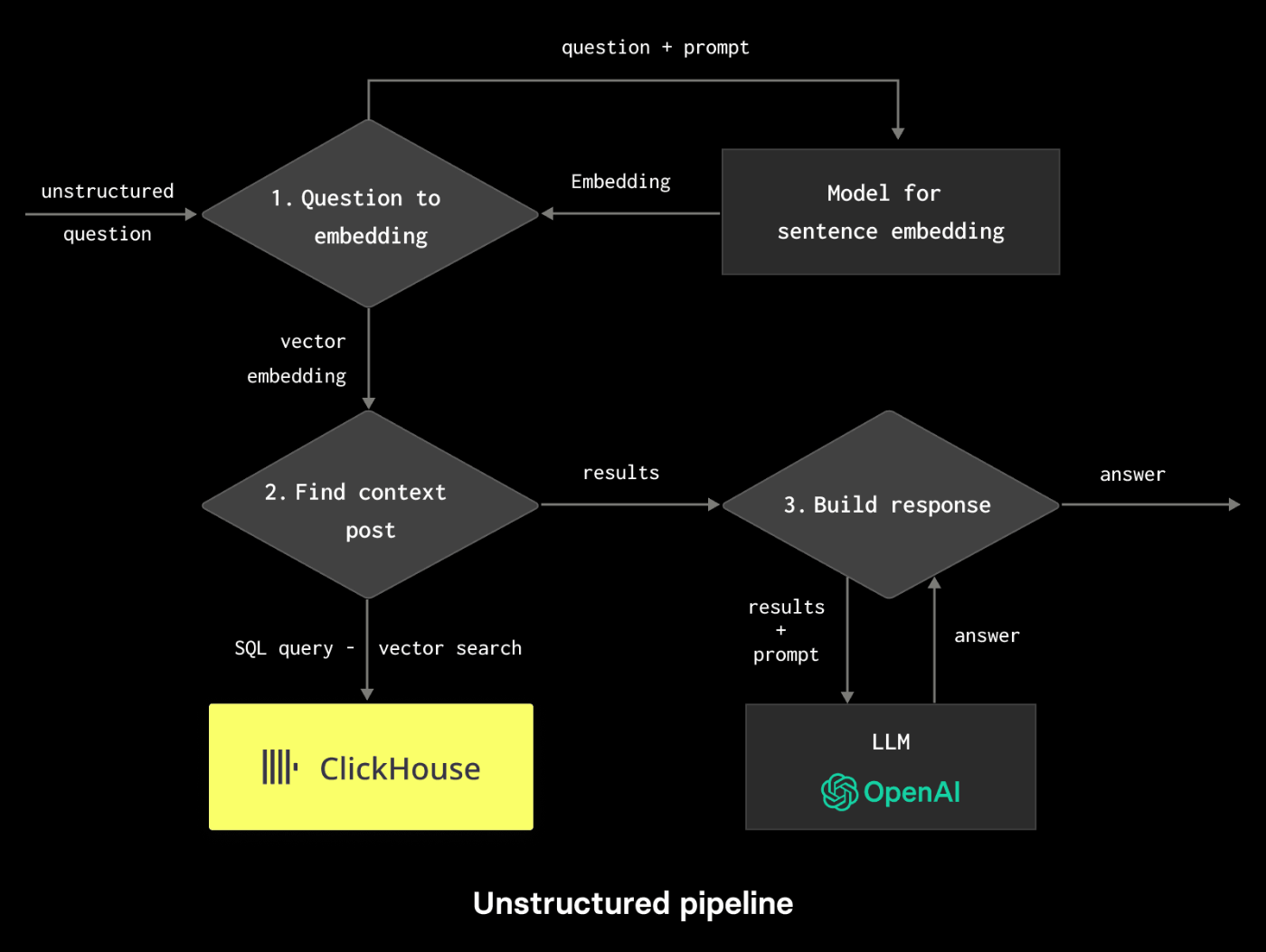
ClickHouseにはコサイン類似度が近いものを検索できるWhere句があり、図左下のSQL queryはそのクエリを指しています。
その組み合わせ
「1000人以上の組織で働く人々が最も使いたいと考えているインフラツールとその理由は何ですか?」
のような、構造化と非構造化の質問を組み合わせた質問です。
このケースでは構造化された質問と非構造化の質問とにクエリ分解(リンク先はクエリ分解の解説)を行い、構造化された質問をSQLに変換し回答を得ます。
その回答と非構造化の質問を組み合わせて質問を作り直し、埋め込みベクトルのコサイン類似度からコンテキストを生成します。

LlamaIndexではルーター機能でリトリーバを自動的に選択させることが出来ます。
使い方は以下の通り。QueryEngineToolがルーター機能を持ったクラスです。
#(1) 上記のようにエンジンを作成
vector_auto_retriever = VectorIndexAutoRetriever(
vector_index, vector_store_info=vector_store_info, similarity_top_k=10,
prompt_template_str=CLICKHOUSE_VECTOR_STORE_QUERY_PROMPT_TMPL, llm=OpenAI(model="gpt-4"),
# コンテキストに特定の長さを要求
vector_store_kwargs={"where": f"length >= 20"}
)
retriever_query_engine = RetrieverQueryEngine.from_args(vector_auto_retriever, llm=OpenAI(model="gpt-4"))
# (2) SQLAutoVectorQueryEngineを支援するために、各エンジンの説明を提供する
sql_tool = QueryEngineTool.from_defaults(
query_engine=nl_sql_engine,
description=(
"自然言語クエリをSQLクエリに変換するのに便利です"
f" a table: {stackoverflow_table}, ユーザが現在使用している、または使用したい様々な種類の技術に関する 調査回答を含む"
f" different types of technology users currently use and want to use"
),
)
vector_tool = QueryEngineTool.from_defaults(
query_engine=retriever_query_engine,
description=(
"自然言語クエリをテーブル上のSQLクエリに変換するのに便利です: {stackoverflow_table}は、ユーザーが現在使用している、または使用したい様々な種類の技術に関する調査回答を含んでいます。
),
)
# (3) SQLデータベースとベクトルデータベースの両方にクエリを実行するエンジン
sql_auto_vector_engine = SQLAutoVectorQueryEngine(
sql_tool, vector_tool, llm=OpenAI(model="gpt-4")
)
response = sql_auto_vector_engine.query("100人未満の従業員を持つ企業で働く人々が最も使いたいと思っているウェブ技術とその理由は何ですか?")
print(str(response))
ちなみに結果のレスポンスは記事にはありませんでした。React.jsが一番人気だそうです。
LlamaIndexを使う利点
ClickHouseベクターストアはlangchainでも使うことが出来ますが、LlamaIndexを使った理由をこう語っています。
LlamaIndexは、事前学習済みの言語モデルと情報検索システムの利点を組み合わせた、Retrieval-Augmented Generation (RAG) 技術を強化するために設計されています。コンテキストは通常、ベクトル検索を通じて他のソースから得られます。
RAGシステムは手動でも作れますが、LlamaIndexはデータソースを大規模言語モデルに接続するための柔軟なデータフレームワークとツールキットを提供します。ほぼ任意のデータストアが使えるため、自分で組み合わせなくて済みます。
LlamaIndexの強みの一つは、膨大な範囲の統合機能を持つことです。プラグ可能なベクトルストアインターフェースだけでなく、ユーザーは自分のLLM、埋め込みモデル、グラフストア、ドキュメントストアを統合し、RAGプロセスのほぼすべてのステップをカスタマイズすることができます。
私も両方使ってみて、LlamaIndexのほうが手軽に使える印象があります。
Text-To-SQLは難しい?
別の記事ですがClickHouseさんがGoogle Analyticsで評判など情報分析できるように
Text-To-SQLを使おうとした記事が見応えがあったので置いておきます。
結構がんばっているようですがなかなか実用は難しい様子…。
続報があればご紹介するかもです。
Discussion