📌
マトリョーシカ・レトリーバーとは?次元削減で検索が早くなる!
OpenAIのAPIに次元削減という機能がつきました。
dimensionsというキーに次元数を指定すると、その次元に削減ができます。
openai.embeddings.create({
model: 'text-embedding-3-large',
input: 'The cat chases the mouse',
dimensions: 1024, # 1024まで次元削減する
})
ちなみにdimensionsを指定しないとフルサイズで埋め込みが作成されます。
このオプションについてLangChainが記事を出していたので解説します。
埋め込みとは文章、画像、動画などの類似度を得ることができるベクトル表現です。
物の位置を知るためにX,Y,Z軸の3軸で表現しますが、これは3次元のベクトル表現です。
埋め込みベクトルはこれが数千とか数万になります。
[-0.023972103, -0.01711244, 0.003479407, ...(数千続く)]
X,Y,ZならXは幅だなとかY軸は高さだとかありますが、この埋め込みベクトルはどれが何を現してるのか理解するのは困難ですが、この次元の一つ一つに文章の意味がこめられていると言われています。
LangChainの新機能、マトリョーシカ・レトリーバーは削減された次元の埋め込みベクトルを検索に使うことで検索速度をあげる試みです。
削減された次元のベクターストアで検索を高速に行い、その後メタデータに保存していたフルサイズの埋め込みベクトルを使って順位付けをします。
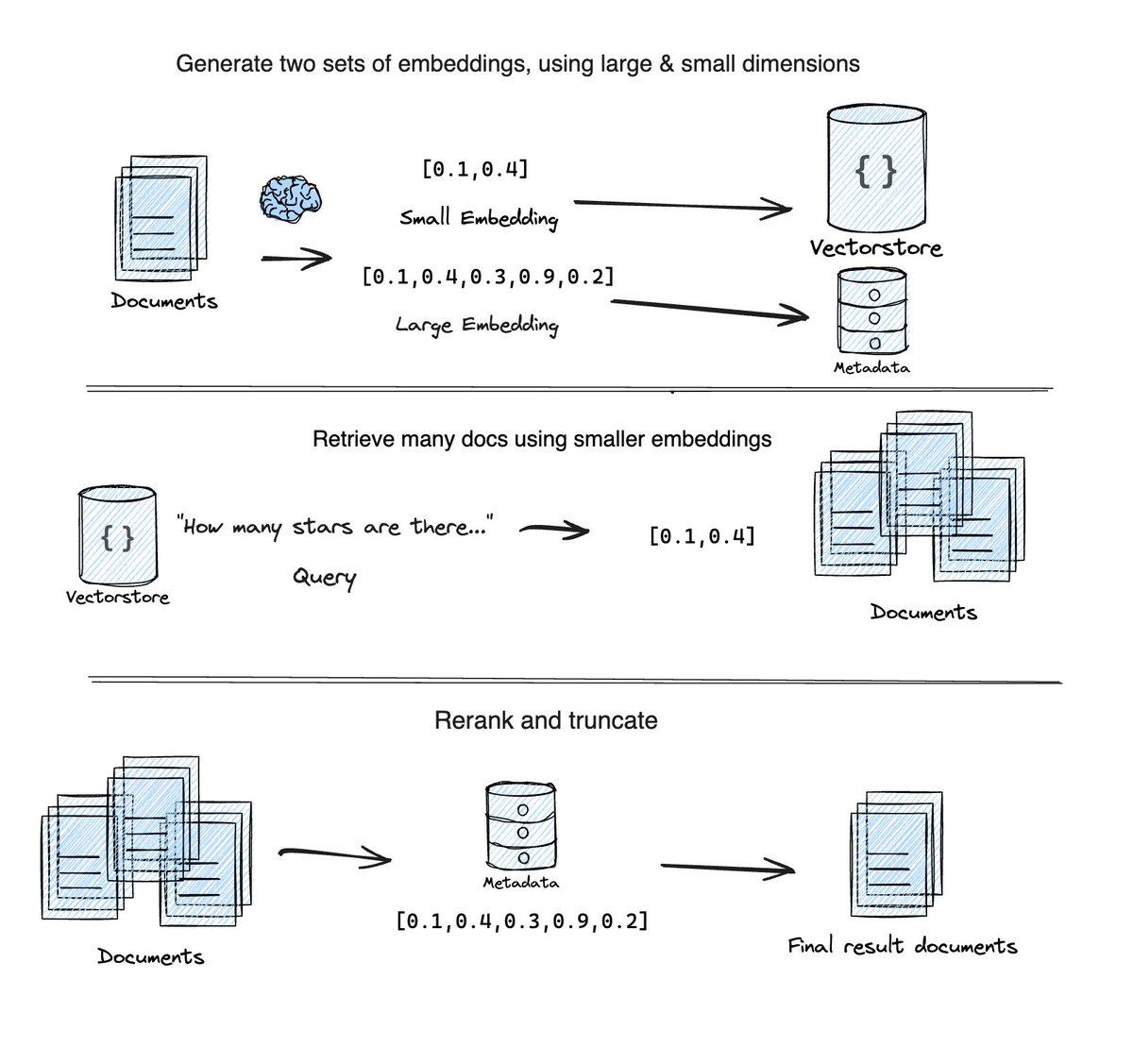
そのソースコードは以下のとおりです。
import { MatryoshkaRetriever } from "langchain/retrievers/matryoshka_retriever";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenAIEmbeddings } from "@langchain/openai";
import { Document } from "@langchain/core/documents";
import { faker } from "@faker-js/faker";
# 低次元の埋め込みベクトル
const smallEmbeddings = new OpenAIEmbeddings({
modelName: "text-embedding-3-small",
dimensions: 512, // 512次元に削減される
});
# フルサイズの埋め込みベクトル
const largeEmbeddings = new OpenAIEmbeddings({
modelName: "text-embedding-3-large",
dimensions: 3072, // Max num for large
});
# 検索に低次元の埋め込みベクトルを使う
const vectorStore = new Chroma(smallEmbeddings, {
numDimensions: 512,
});
const retriever = new MatryoshkaRetriever({
vectorStore,
largeEmbeddingModel: largeEmbeddings,
largeK: 5,
});
const irrelevantDocs = Array.from({ length: 250 }).map(
() =>
new Document({
pageContent: faker.lorem.word(7), // Similar length to the relevant docs
})
);
const relevantDocs = [
new Document({
pageContent: "LangChain is an open source github repo",
}),
new Document({
pageContent: "There are JS and PY versions of the LangChain github repos",
}),
new Document({
pageContent: "LangGraph is a new open source library by the LangChain team",
}),
new Document({
pageContent: "LangChain announced GA of LangSmith last week!",
}),
new Document({
pageContent: "I heart LangChain",
}),
];
const allDocs = [...irrelevantDocs, ...relevantDocs];
/**
* IMPORTANT:
* `MatryoshkaRetriever` の `addDocuments` メソッドは、
* すべてのドキュメントに対して小さい埋め込みと大きい埋め込みを生成します。
*/
await retriever.addDocuments(allDocs);
const query = "What is LangChain?";
const results = await retriever.getRelevantDocuments(query);
console.log(results.map(({ pageContent }) => pageContent).join("\n"));
supabaseさんが書いたマトリョーシカ埋め込みの記事では、512次元に削減するのが最もよい検索精度とスピードが得られたそうです。
Discussion