BigLake external tablesを使って GCS 上の Delta Lake のデータを参照する
記事の背景
多くの企業でマルチクラウド環境が当たり前の時代です。例えば、GCP Databricks と GCP が混在した環境があり、GCP Databricks 側でデータ処理を行った後の Delta Lake テーブルのデータを GCP で参照したいという要件があった際に、 ETL パイプラインの開発なしに BigQuery で参照できると、移行コストが大幅に低減できる上に、オープンテーブルフォーマットを使っていることのメリットがわかりやすく伝えられることができます。
なお、BigQuery でのオープンテーブルフォーマット対応は、 BigLake external tables という機能として数年前から提供されており、Iceberg より Delta Lake の方が先行しています。Big Lake external tables は GA になってから時間が経っており、成熟している機能なので、本番環境でも利用可能です。
よって BigLake external tables を実際に使って、GCS 上の Delta Lake テーブルのデータを参照してみようと考えて、本記事の検証になりました。
技術的なアプローチの概要
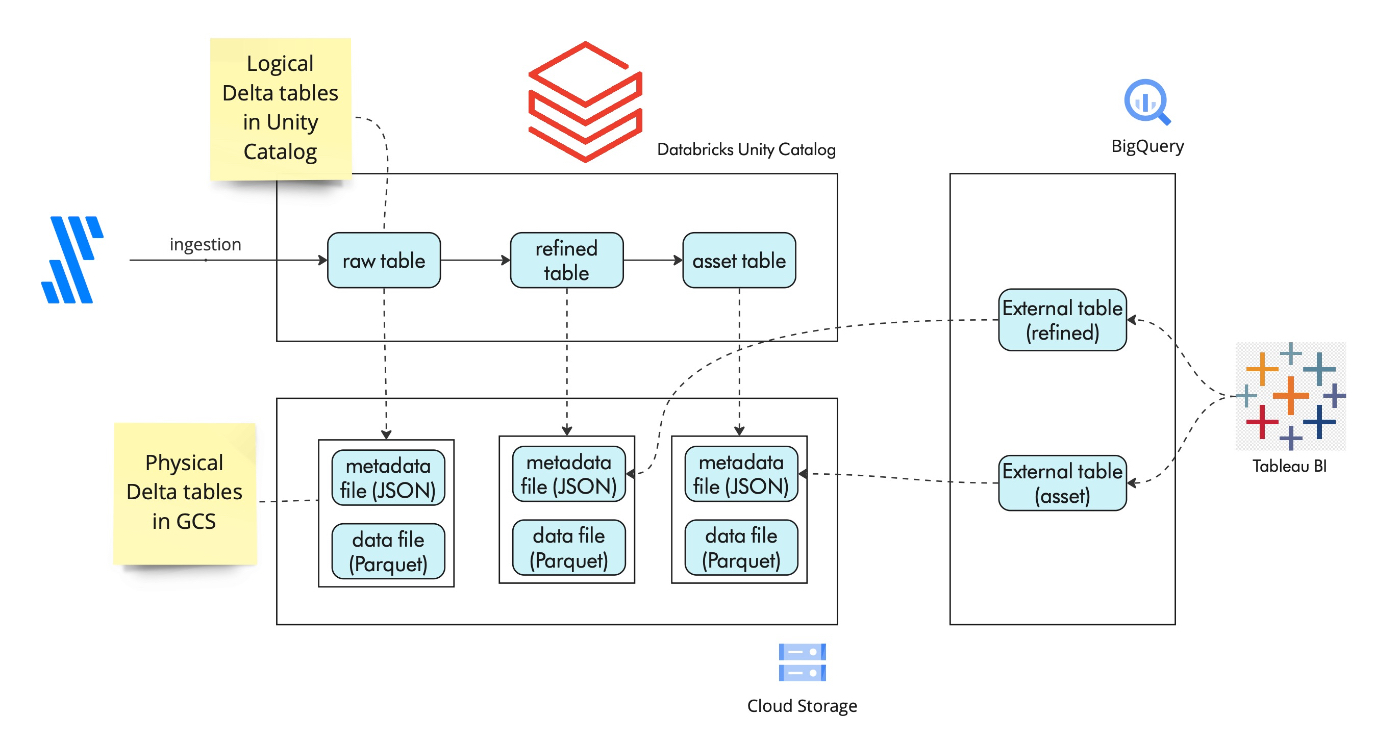
大まかなアーキテクチャとしては以下を想定しています。
- 論理的な Delta Lake のテーブルは Databricks 上の Unity Catalog で管理されている。
- 物理的なデータとメタデータは GCS バケットに保存される。テーブルの保存先パスは Storage Location として Databricks UI 上で確認できる。
- BigQuery 上で外部テーブルを作成する際に、Delta Lake テーブルの Storage Location を指定する。
- BigQuery が GCS 上の Delta Lake メタデータファイルから自動的にテーブルスキーマを検出し、 BigQuery 上のテーブルに同期する。よってスキーマ同期を手動で実施する必要がない。
- Tableau など BigQuery クライアントで外部テーブルをクエリすると、BigQuery は実際には GCS 上の Delta Lake のデータファイル (Parquet) をクエリする。
利用可能な BigQuery の外部テーブルのオプション
BigQuery で利用できるオープンテーブルフォーマットに対応したテーブルの種類は以下の通り。

- Standard BigQuery tables は BigQuery のネイティブテーブルであり、Delta Lake には対応していません。
- 左から 2 番目と 3 番目が外部テーブルのオプションであり、左から 2 番目の "BigLake external tables" のみ Delta Lake に対応しています。https://cloud.google.com/bigquery/docs/create-delta-lake-table
- 右側 2 つは両方とも最近リリースされた機能であり、BigQuery 内に Iceberg のメタストアを設けるアプローチのため、今回の記事には関係ありません。
なお、BigLake は BigQuery 上のガバナンスレイヤーであり、外部テーブル上に Row Level Security / Column Level Security などの機能を適用できます。
Delta Lake 用の BigLake external table を作成する
BigQuery で外部テーブルを作成する際のクエリの構文は以下を参照。
format としては DELTA_LAKE を指定します。
uris には参照したい Delta Lake テーブルのストレージロケーションを指定します。テーブルのストレージロケーションは、Databricks の UI で確認できます。
CREATE EXTERNAL TABLE IF NOT EXISTS
lakehouse_poc.diamonds OPTIONS (
format = "DELTA_LAKE",
uris = ["gs://databricks-aaa-unitycatalog/bbb/__unitystorage/catalogs/ccc/tables/ddd"] );
なお、サンプルのテーブルは dbt のチュートリアルで使われているダイアモンドのテーブルを使用しています。Databricks 側でのテーブルの作成方法は以下を参照ください。
BigQuery 側で以下のクエリを実行し、実際にデータが参照できていることが確認できました。
SELECT
SUM(carat) AS sum_carat,
cut
FROM
lakehouse_poc.diamonds
WHERE
price > 300
GROUP BY
cut;
例えば、Databricks 側でカラム追加など後方互換性のあるテーブルスキーマ変更を行なっても、BigQuery 側のテーブルに変更が適用され、また SELECT 文を再実行してもクエリは成功します。
ALTER TABLE my_catalog.lakehouse_poc.diamonds
ADD COLUMN test INT;
本アプローチの懸念事項
以下は、筆者が ChatGPT と議論していた際に出てきた懸念事項です。
BigQuery external tables が将来的に最新バージョンの Delta Lake をサポートしなくなる可能性がある
今回は Databricks のデフォルトのテーブルフォーマットとして Delta Lake を使いましたが、Databricks と Microsoft Fabric を除くと、ほとんどのプラットフォームが Iceberg をメインのオープンテーブルフォーマットとして採用しています。Google Cloud も最近の動向を見ると、Iceberg に専念しているのが分かります。
e.g. Microsoft Fabric https://learn.microsoft.com/en-us/fabric/fundamentals/delta-lake-interoperability
また、Databricks も 2025/3/28 のウェビナーでデータ保存用のテーブルフォーマットとして Iceberg 対応を発表しました。よって、Databricks 自身も相互運用性を高めるため、Iceberg 対応を高めていくと思います。市場動向を確認し、ベンダーの発表を確認しながら、 Delta Lake の外部テーブルを利用することのリスクが顕在化しないように気をつける必要があります。
外部テーブルはプルーニングなどの最適化がうまく機能しない可能性があり、物理テーブルに比べるとクエリパフォーマンスが劣化する可能性がある
もし外部テーブルを使うとすると、元のテーブルのサイズは小さく保てば大きな問題ではなくなると思います。
Delta Lake と BigQuery の間でデータ型のミスマッチが起きる可能性がある
Delta Lake と BigQuery は当然同じ仕様の製品ではないため、データ型の不一致があり、意図しない形でデータが変換されるリスクがあります。実際にクエリして問題が起きないか確認しましょう。
Delta Lake data type - https://docs.databricks.com/aws/en/sql/language-manual/sql-ref-datatypes
BigQuery data type - https://cloud.google.com/bigquery/docs/reference/standard-sql/data-types
クライアントが一時的に不整合なデータを参照する可能性がある
Delta Lake や Iceberg はマルチテーブルのトランザクションをサポートしていないため、一連のテーブルを一気に変更しようとしている時に、クライアントが一時的に不整合のあるデータを参照するリスクはあります。しかし、これはオープンテーブルフォーマットを使っていると回避できない問題です。
なお、現在、 BigQuery で dbt を実行する際に、マルチテーブルのトランザクションは実行していないので、不整合が出る可能性としては現状と同じです。
データのテストを通じて、データの品質上の課題を自動検出することが解決策として考えられます。
マテリアライズドビューはストレージロケーションがないため、外部テーブルが作れない
Materialized View と Delta Live Tables を使って、宣言的かつ incremental にデータ処理できることは、Databricks のコスト上の優位性の 1 つです。ただし、Materialized View はあくまでもクエリ結果をキャッシュする機能であり、外部から参照できるストレージロケーションがないようです。よって、Materialized View を直接、外部テーブルで利用できません。
一方で、この制約事項を克服できるかもしれない事項を発見したため、次回はここを検証したいと思います。
Materialized views and streaming tables published from a Delta Live Tables pipeline, including those created by Databricks SQL, can be accessed only by Databricks clients and applications. However, to make your materialized views and streaming tables accessible externally, you can use the Delta Live Tables sink API to write to tables in an external Delta instance. See Stream records to external services with Delta Live Tables sinks.
まとめ
今回は、Databricks で処理した GCS 上にある Delta Lake のテーブルデータを BigQuery から参照するアプローチのメリットや懸念事項を紹介しました。
Materialized views は BigQuery の外部テーブルから参照できないことがわかっているため、この点の克服方法があるかどうか検証し、次回紹介したいと思います。
Discussion