Data Platform Engineering Tool として Databricks Asset Bundles が便利だった
本記事は、 Databricks Advent Calendar 2024 シリーズ 1 の 2 日目の記事です。
本記事の背景
筆者は、事業会社のデータプラットフォームチームのメンバーとして、 GCP 上に構築されたデータプラットフォームを使うユーザのうち、主にデータエンジニアに対して、 Airflow や dbt といった社内標準スタックを使ったデータパイプラインをセルフサービスかつ効率的に開発・デプロイできるツール群を開発・提供しています。この活動は、書籍 ”チームトポロジー” で議論されているプラットフォームチームに相当するものだと認識しています。
筆者は 2010 年代初頭からクラウドプラットフォームを複数利用していますが、これまでの経験上、クラウドプラットフォームが公式に提供しているツールだけでは、開発が完結しづらく、 OSS のツールや自前のツールを開発し、自社プラットフォームをより使いやすくしようと自動化やツール開発などに勤めてきましたが、一方で、プラットフォームチームの労力が大きく、開発負荷が高くなることに課題を感じていました。
一方で、 Databricks が提供している Asset Bundles は、拡張性と柔軟性があり、データパイプラインの開発とデプロイ、 DevOps 、インフラリソースのプロビジョニング、テンプレート化などデータエンジニアにとってデータプラットフォームをセルフサービス化する上で欠かせない要素をプラットフォームベンダーが公式に提供している、筆者の経験上、初めてのケースのため、私の観点をブログ上で取り上げようと考えました。
本記事で言う、データプラットフォームエンジニアリングとは?
データプラットフォームは、主にマイクロサービスの分野で発達した概念です。定義としては以下のとおりです。
Platform engineering is the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organizations in the cloud-native era. Platform engineers provide an integrated product most often referred to as an “Internal Developer Platform” covering the operational necessities of the entire lifecycle of an application.
プラットフォームエンジニアリングは、クラウドネイティブ時代においてソフトウェアエンジニアリング組織のセルフサービス機能を可能にするためのツールチェーンとワークフローを設計・構築する分野です。プラットフォームエンジニアは、アプリケーションのライフサイクル全体の運用に必要な要素をカバーする「内部開発プラットフォーム」と呼ばれる統合製品を提供します。
プラットフォームエンジニアリングやプラットフォームチームの概念が浸透してきた背景は、書籍 ”チームトポロジー” にも紹介されています。現代のソフトウェア開発では、少人数で自己完結したチームを作り、高速にデリバリを行うことが求められている一方で、学習コストや認知負荷が高くなり、生産性が低下してしまうことが課題になっています。この課題を解決するため、開発チームがセルフサービスでアプリケーションを簡単かつ迅速に開発・提供できるように各種ツールチェインを整備することが、プラットフォームエンジニアリングであり、その役割を担うチームがプラットフォームチームです。
この考え方は、データエンジニアリングにも応用でき、データエンジニアがセルフサービスで、迅速にデータパイプラインを開発・デリバリできる仕組みづくりをデータプラットフォームエンジニアリングと考えることができ、その役割を担うのがデータプラットフォームチームです。
ここで、自社で利用するクラウドプラットフォーム自身がデータプラットフォームエンジニアリングの仕組みを直接的に提供していない場合、データプラットフォームチームが提供する役割を担う必要があります。この時、 OSS や内製開発を伴うため、作業負荷は高くなります。
データプラットフォームのツールに具体的に何を求めるかは、会社によって様々ですが、筆者のチームで実施した施策としては以下の通りになります。これにより、データエンジニアがセルフサービスで仕事を完結でき、プラットフォームチームもチケット対応する量が減り、お互いに生産性を向上できました。
- データパイプラインの標準スタックを決める・・・データの取り込みは Fivetran 、オーケストレーションは Composer (Airflow) 、データモデリングは dbt 、データウェアハウスは BigQuery 、ストレージは GCS など。
- 標準的なパイプラインのテンプレートを用意する。テンプレートには Airflow のオーケストレーションコード、 dbt によるデータモデリング、インフラのリソース定義など、データパイプライン開発で必要な一式が含まれます。
- テンプレートを使って開発したパイプラインを Git リポジトリに push するとテストやデプロイが走る CICD パイプラインが標準化されており、簡単に使える。
- データパイプラインのテンプレートの中に、一部インフラリソース(サービスアカウント、 GCS バケット、 IAM ロールなど)をプロビジョニングするための Terraform モジュールが含まれている。プラットフォームチームに支援を求めなくても、事前に合意した範囲であれば、自分でリソースが作成できる。
Databricks Asset Bundles とは
これまでの議論を踏まえて、 Databricks Asset Bundles は、筆者から見るとクラウドプラットフォームベンダーがプラットフォームエンジニアリングを強く意識したツールに見えます。
機能 (1) Databricks Workflow jobs のビジネスロジック記述とオーケストレーション設定
まず、 Databricks のオーケストレーションツールである Databricks Workflows 上で実行できるジョブ(データパイプラインのこと)のビジネスロジック (SQL や Python など)とオーケストレーションの設定をコードで記述でき、これらを Git 管理することが可能です。
パイプラインの個別ステップであるタスクの種類としては、 Notebook / Python script / Python wheel / SQL / dbt / Delta Live Table pipeline / Spark などを選択できます。タスクの記述方法については以下を参照ください。
例えば、 dbt のタスクを実行する場合、 Asset Bundle には以下のように記述します。
ジョブのスケジュールとしては、時間ベース、イベントベース(ファイルの到着)、継続などが利用できます。
以下の場合、日次でジョブを実行できます。
機能 (2) Databricks インフラの設定記述
純粋なパイプラインだけでなく、クラウドインフラリソースのプロビジョニングやワークスペースの設定なども行うことができます。
以下はクラシックコンピュートクラスターを新規にプロビジョニングする場合の例です。
どのようなリソースをサポートしているかについては以下のドキュメントを参照してください。
Asset Bundles の設定ファイルの例は以下に紹介されています。
機能 (3) デプロイプロセスの自動化
Asset Bundles を実際に Databricks のワークスペースやアカウントにデプロイする場合は、 Databricks CLI コマンドを利用します。
validate コマンドで設定ファイルに不備がないか確認できます。
$ databricks bundle validate
特定の環境にデプロイする場合は、 deploy コマンドを利用します。
databricks bundle deploy -t dev
databricks bundle deploy -t prod
クラウドリソースのプロビジョニングには裏側で Terraform が使われており、 deploy コマンド実行時に、 Terraform の設定ファイルが生成されます。生成された Terraform 設定ファイルの詳細を確認したい場合は、 Databricks Provider を参照ください。
ジョブでスケジューリングせず、 CICD パイプラインもしくは外部アプリケーションからジョブを実行したい場合は、 run コマンドを利用します。
databricks bundle run -t dev <project-name>_pipeline
なお、 Databricks CLI の詳細については以下のドキュメントを参照してください。
機能 (4) テンプレート化
Databricks CLI には Asset Bundles のテンプレートが 4 つ梱包されており、 init コマンドを使ってテンプレートから Asset Bundles の設定ファイルを生成できます。
databricks bundle init
また、自作のテンプレートも作成できるため、自社の標準パイプラインに合わせてテンプレートを作成し、それを配布することでデータパイプラインプロジェクトコードを用意する手間を減らすことができます。
databricks bundle init /projects/my-custom-bundle-templates
なお、 CLI に梱包されているデフォルトのテンプレートは Github に公開されています。
Databricks Asset Bundles を使った CICD プロセス
CICD のプロセス全体としては以下の通り。必要な権限が付与されていれば、 CLI を使ってローカルから開発環境に素早くデプロイできます。テストで問題なければ、 Git リポジトリにマージし、 CICD パイプラインを実行して、各環境へのデプロイが実行されます。
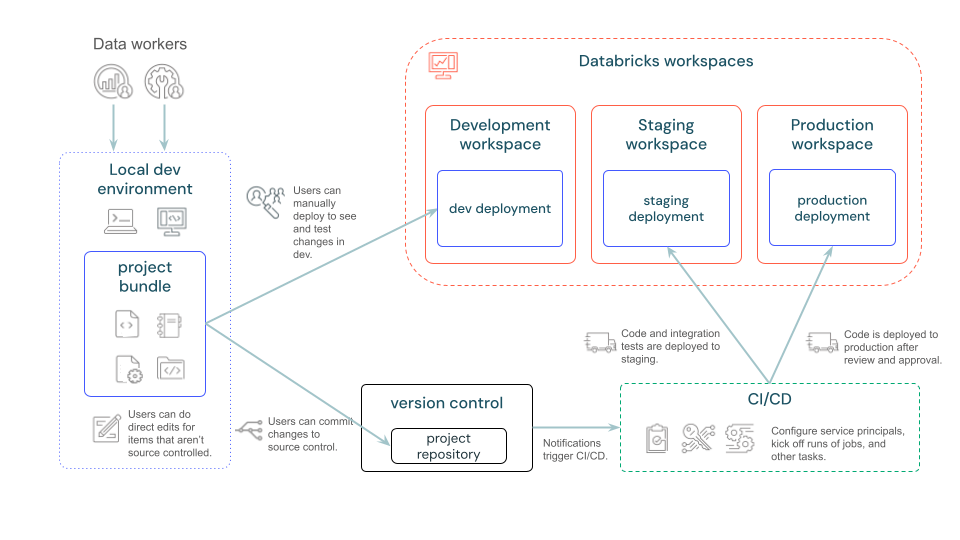
上記で議論した通り、 Asset Bundles を使い、 Databricks のリソースを記述し、 CLI と併用してデプロイも実行できますが、 Asset Bundles が CICD のオーケストレーションの大体を意図したツールではないため、 CICD 部分は自前で用意する必要があります。 Databricks CLI さえ実行できればよく、任意のツールを利用できます。以下のドキュメントでは、 CICD ツールとして、 Github Actions 、 Jenkins などが紹介されています。
おわりに
本記事では、事業会社でデータプラットフォームエンジニアリングを実践する立場から、 Databricks の Asset Bundles がプラットフォームエンジニアリングを強く意識した、今までにないタイプのツールであることを紹介しました。
筆者自身、 Asset Bundles には強いポテンシャルを感じますが、ソーシャルメディアではあまり見かけることがないため、今後、ユーザからの注目が集まり、ツールが今後も継続的に発展していくことを願います!本記事を通じて、 Asset Bundles の可能性に気づいてくれた方が一人でもいらっしゃれば幸いです。
Discussion