Data Observability の概要
本記事は、某コミュニティで Data Observability について議論するために書き下したメモです。もし Data Observability について議論されたい方は気軽にコメントください。
概要
Data Observability を直訳するとデータの可観測性。あくまでデータを観測できるようにする技術分野であって、 Data Observability すなわち、データ品質ではない。
本来の意味合いは、外部から観測可能な出力を使って、複雑なシステムの内部状態や振る舞いを観測可能にすること。それにより、対象システム(あるいはデータ)をより理解できるようにする。よく理解できるようにした結果、データの品質やパフォーマンスの最適化などの取り組みを楽にできる場合がある。ただし、ツールやサービスを入れると自動的に実現できるわけではない。
語源は制御工学分野の Observability
元々は制御工学分野の用語。外部から観測可能な出力からシステムの内部状態を観測可能にすること。制御工学は機械、ロボットなど複雑なシステムを制御するための工学分野、理論。
ソフトウェア業界の Observability
ソフトウェア業界での Observability は、主に Microservices など分散システムに対する手法を指す。目的としては語源と同じく、外部から観測可能な出力からシステムの内部状態を観測可能にすること。
分散システムの場合、外部から観測可能な出力の種類は、ログ・メトリクス・トレースの3つ。これらの3つのデータを利用して、分析を行うことで、分散システムの複雑な振る舞いが理解できるようになり、結果的に、システム障害の調査やパフォーマンス最適化などに利用できる。

(画像引用元 https://devopscube.com/what-is-observability/)
例えば、ログ・トレース・メトリクスを組み合わせて、ユーザがリクエストを送ってきた時に各サービスがどう連携しあってリスクエストを処理したのか、各処理でどれくらいの時間がかかったか、どういうエラーや警告が出てたか可視化できる。

(画像引用元 https://devopscube.com/what-is-observability/)
なお、ソフトウェア業界で、最初にObservabilityの概念を導入した元祖は2013年に発表されたTwitterの記事。
Google を中心に SRE(ソフトウェアエンジニアリングで運用を効率化する手法)が発達し、業界に浸透する中で、Observability も普及していった。
Data Observability
分散システムの Observability をデータパイプラインに適用したのが Data Observability 。考案者は、 Data Observability 業界で有名な SaaS の Monte Carlo の CEO 。
Data Observability は、データの品質もしくはパイプラインの問題によって、正常なデータが得られないことで経済的損失を被っている時間 = Data Downtime に対処する方法論として誕生した。
Data Observability において、外部から観測できるデータとして Monte Carlo の場合は、以下を利用する。
- データの鮮度・・・テーブルが正しい時間で更新されているか
- データの量・・・レコード数が多すぎたり、少なすぎたりしないか
- データの分散・・・値は正常な範囲か?
- スキーマ・・・データスキーマは変わっていないか?
- リネージ・・・アップストリームとダウンストリームにおいて、データ資産がどのようにつながっているのか?
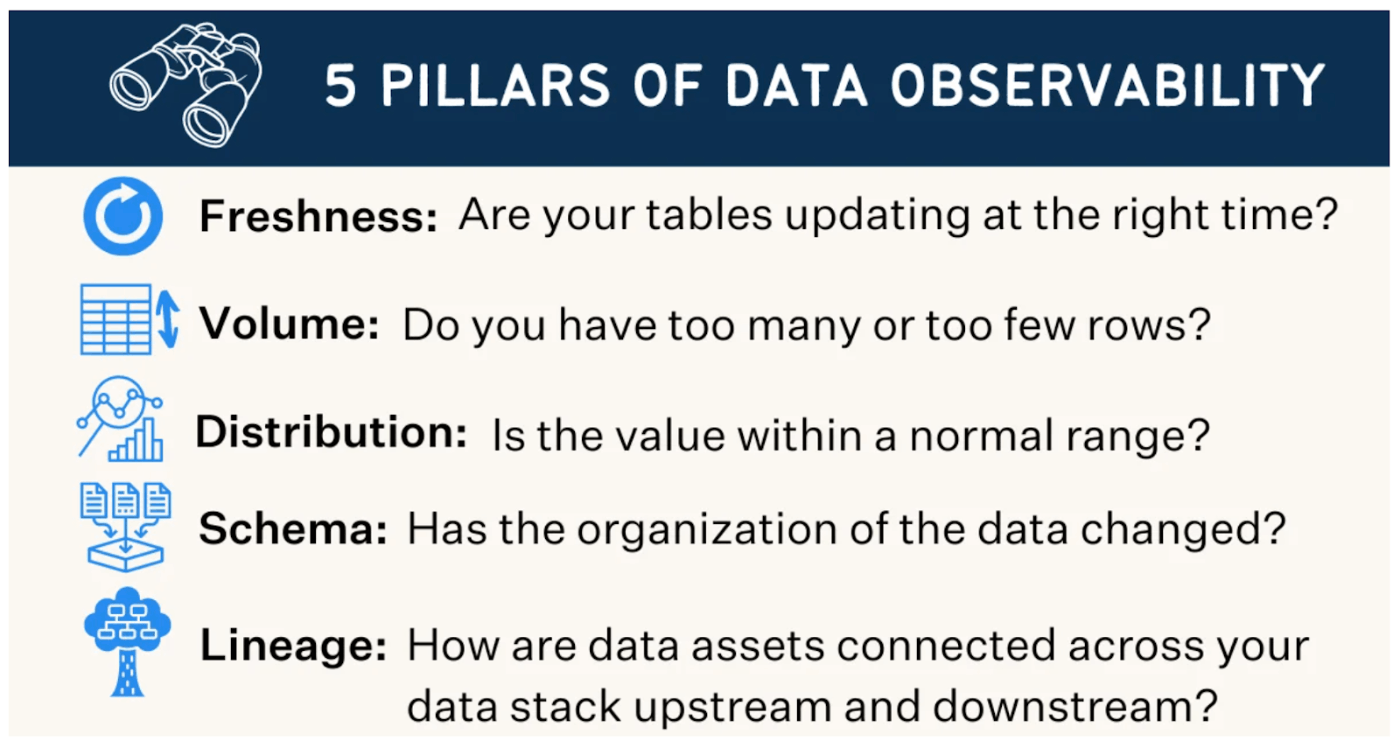
(画像引用元 https://www.montecarlodata.com/blog-what-is-data-observability/)
主なユースケースはデータ品質(正確性、完全性、一貫性、一意性、整合性、適時性、有効性)の監視。継続的にデータ品質メトリクスを取得し、普段のデータの特徴を機械学習アルゴリズムで学習する。これによりハズレ値を見つけることで、異常を検知する。
主な Data Observability ツールのメリット
既存のパイプラインにシームレスに結合し、変更コストが小さい。
機械学習などのアルゴリズムを使って自動的に問題を見つける。
データテストとの違い
- データテストは主にデータの取り込みから、データ変換のあたりまで対応する。Data Observabilityはend to endで監視できる。
- データテストは導入に時間がかかる。また、カバレッジを上げるのは困難。また予測できる問題にしか使えない。Data Observabilityは、導入が簡単で、広範囲に適用し、予想できない問題を見つけるのに使う。
予測できない問題の例
- ダッシュボードやレポートが長期間更新されていなかったが、誰も気づかなかった。利用者から指摘されて、調査したところ問題に気づいた。
- ちょっとしたスキーマやコードの変更で、データの取り込みが止まってしまった、本来は5万件なのに50万件登録された、など。
- データテストは大昔作られたが、ビジネスロジックの変更が反映されていなかった。
モニタリングとの違い
- 多くのデータチームがデータパイプラインをモニタリングしており、パイプラインが異常な状態になった時にアラートを設定するようにしている。
- パイプラインが正常に動作していても、データ品質が異常になるケースはある。
Data Observability ツールやサービスの例
Monte Carlo
Elementary
- OSSおよびSaaS
- OSSの場合、自社のSnowflakeアカウントに閉じた形で利用できるため、導入しやすい。
- 何らかの理由でSaaSに移行したい場合も移行しやすい仕組みになっている。
- 利用企業
- CARTA Holdings (peiさん) - https://speakerdeck.com/pei0804/centralized-to-dataops-transformation?slide=46
- 10x (小売チェーン向けECプラットフォーム「Stailer」の運営) https://speakerdeck.com/10xinc/elementarywoyong-itadetapin-zhi-noke-shi-hua-todetaji-pan-noyun-yong-gai-shan
Elementary の概要
仕組み
dbtに設定を入れると、dbt コマンドを実行するたびにメタデータをSnowflake内のデータベースに溜め込んでくれる。
OSSの場合は、自社のSnowflakeアカウントで完結する。SaaSの場合は、elementaryのデータベースへの参照権をelementary cloudに渡す。
自社データは晒さない仕組みなので、まずはOSSで始めて、しばらく運用してみて、SaaSとの比較で良さそうならSaaSに移行もあり。
機能
- 10x 吉田さん資料を参照。 Elementaryを用いたデータ品質の可視化とデータ基盤の運用改善
- dbt test をデータ品質メトリクスにマッピングして、データ品質を可視化
- データ品質の集計結果はダッシュボードで確認できる Data Observability Dashboard - Elementary
- Anomaly Detection https://docs.elementary-data.com/data-tests/introduction#anomaly-detection-tests
- データ量・鮮度・次元・コラムの異常などを時系列データ分析アルゴリズムで検出
- https://docs.elementary-data.com/data-tests/how-anomaly-detection-works
- スキーマのテスト https://docs.elementary-data.com/data-tests/schema-tests/schema-changes
- スキーマ変更を検出できる
- Data Observability Dashboard https://docs.elementary-data.com/features/data-observability-dashboard
- End to end data lineage https://docs.elementary-data.com/features/lineage
- OSS vs Cloud Elementary: Community vs Cloud - Elementary https://docs.elementary-data.com/overview/cloud-vs-oss
Discussion